本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关。
1. urllib库的使用
1.1 获取数据
爬虫的定义我这里就不多说了,直接进入正题,如何利用urllib库去使用爬虫。模拟浏览器向服务器发送请求:
1
2
| import urllib.request
response = urllib.request.urlopen('http://www.某du.com')
|
下面的方法能获取响应的页面源码,但是需要注意的是read()返回的是字节形式的二进制数据,所以需要decode()解码:
1
| content = response.read().decode('utf-8')
|
返回的reponse的类型为HTTPResponse,该返回值常用的方法如下:
- read() :字节形式读取二进制数据,
read(Number)返回指定字节的数据;
- readline() :读取一行;
- readlines() :一行一行读取所有;
- getcode() :获取响应状态码;
- geturl() :获取请求的URL;
- getheaders() :获取headers;
1.2 下载
除了获取数据,我们也能通过爬虫下载网页资源:
- 下载网页:
1
| urllib.request.urlretrieve('http://www.某du.com','baidu.html')
|
- 下载图片:
1
| urllib.request.urlretrieve('https://xxxxx.cdn.bcebos.com/pic/fcfaaf51f3deb48f8f9616a7fd1f3a292cf578cf?x-bce-process=image/resize,m_lfit,h_500,limit_1/format,f_auto','迪丽热巴.jpg')
|
- 下载视频:
1
| urllib.request.urlretrieve('https://vd2.xxxxxxxx.com/mda-magpzuurpki42hbv/v1-cae/sc/mda-magpzuurpki42hbv.mp4?v_from_s=hkapp-haokan-hbe&auth_key=1661150989-0-0-5951edef259d3b8ceac0327beca694ac&bcevod_channel=searchbox_feed&pd=1&cd=0&pt=3&logid=1189836669&vid=12518682849229018276&abtest=103579_1-103742_4&klogid=1189836669','迪丽热巴.mp4')
|
2. 请求对象request的定制
User-Agent,中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本,浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等
URL 的组成有以下几个部分:
1
2
| http/https wwww.某du.com 80/443 s wd=迪丽热巴 #
协议 主机 端口号 路径 参数 锚点
|
上面的例子我们是请求的http接口,能够正常爬取,但是请求https某度网址,会遇到UA反爬,也是很常见的一种反爬机制:
1
2
3
4
5
| import urllib.request
url = 'https://www.某du.com'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
print(content)
|

所以在发送请求时,要带上我们的UA,UA的获取方法如下:
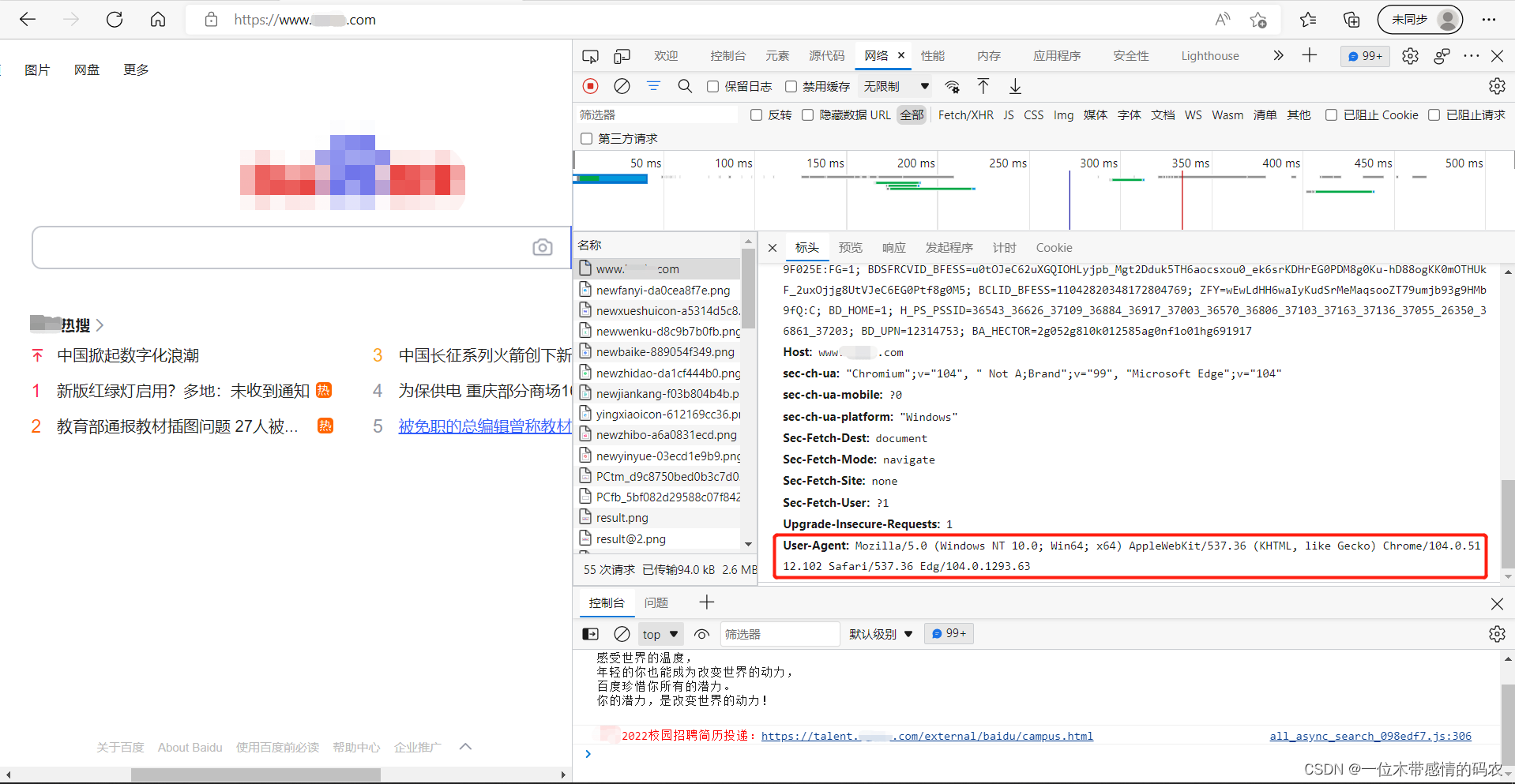
带上UA爬虫代码如下:
1
2
3
4
5
6
7
8
| headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
url = 'https://www.某du.com'
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
|
因为urlopen()方法不支持字典变量,所以我们可以将信息放入定制的Request对象中,再将Request对象放入urlopen()中。这里需要注意的是,Request()方法的参数必须使用关键字传参,查看Request源码,可以发现,第二个参数是data=None,所以不指定的话,默认会认为传入的UA是data参数:
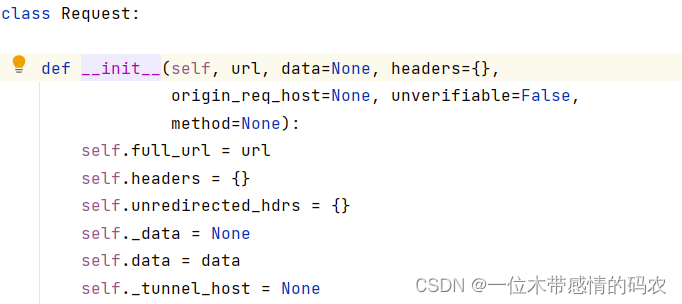
3. 编解码
编码集的演变:由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc‐kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
3.1 get请求
3.1.1 quote()
上面说了 URL 的组成和UA的作用,那么现在有一个需求:获取https://www.某du.com/s?wd=迪丽热巴的网页源码。
1
2
3
4
5
6
7
8
9
| import urllib.request
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
url = 'https://www.某du.com/s?wd=迪丽热巴'
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
|
直接运行上面的代码,会发现报错:

这是因为编码的问题,我们需要将迪丽热巴四个字变成unicode编码的格式,而这需要依赖urllib.parse的quote()方法:
1
2
3
4
5
6
7
8
9
10
11
| import urllib.request
import urllib.parse
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
name = urllib.parse.quote('迪丽热巴')
url = 'https://www.某du.com/s?wd=' + name
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
|
3.1.2 urlencode()
既然有将一个参数变成unicode编码格式的方法,那么肯定有将多个参数同时变为unicode编码格式的方法,毕竟我们平时用的接口不可能只有一个参数,这个方法就是urlencode(),它的参数类型是字典,应用场景:URL 同时有多个参数时,将多个参数变成unicode编码的格式。
1
2
3
4
5
6
7
8
| import urllib.request
import urllib.parse
data = {
'wd' : '迪丽热巴',
'sex' : '女'
}
a = urllib.parse.urlencode(data)
print(a)
|
运行结果如下,将多个参数同时转为了unicode编码格式并用&分割:

3.2 post请求
上面说的案例都是get请求接口,但其实我们遇到的更多的还是post请求接口,在请求时要带上参数值,以某度翻译为例,找到发送单词请求数据的 URL:
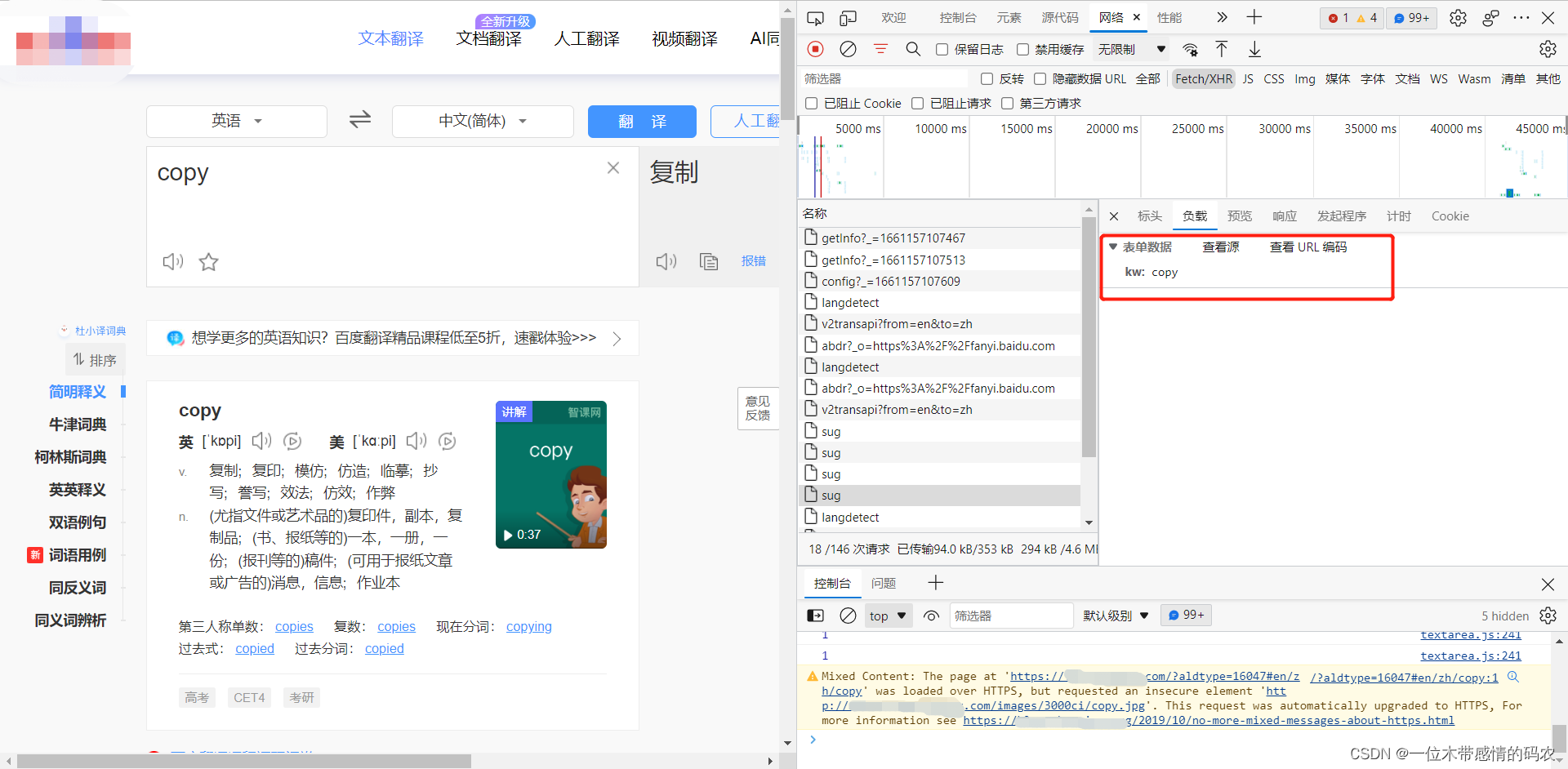
请求地址为https://fanyi.某du.com/sug,且以post方式发送。携带的参数为{kw:copy},返回的数据为一组json数据,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import urllib.request
import urllib.parse
import json
url = 'https://fanyi.某du.com/sug'
data = {
'kw' : 'copy'
}
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
obj = json.loads(content)
print(obj)
|
注意:
get请求方式的参数必须编码,参数是拼接到 URL 后面,编码之后不需要调用encode()方法;post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用encode()方法;
3.3 案例:某度详细翻译
前面的案例用过了某度翻译的post的接口,但其实某度翻译还有一个某度详细翻译的接口,返回的数据更加详细:
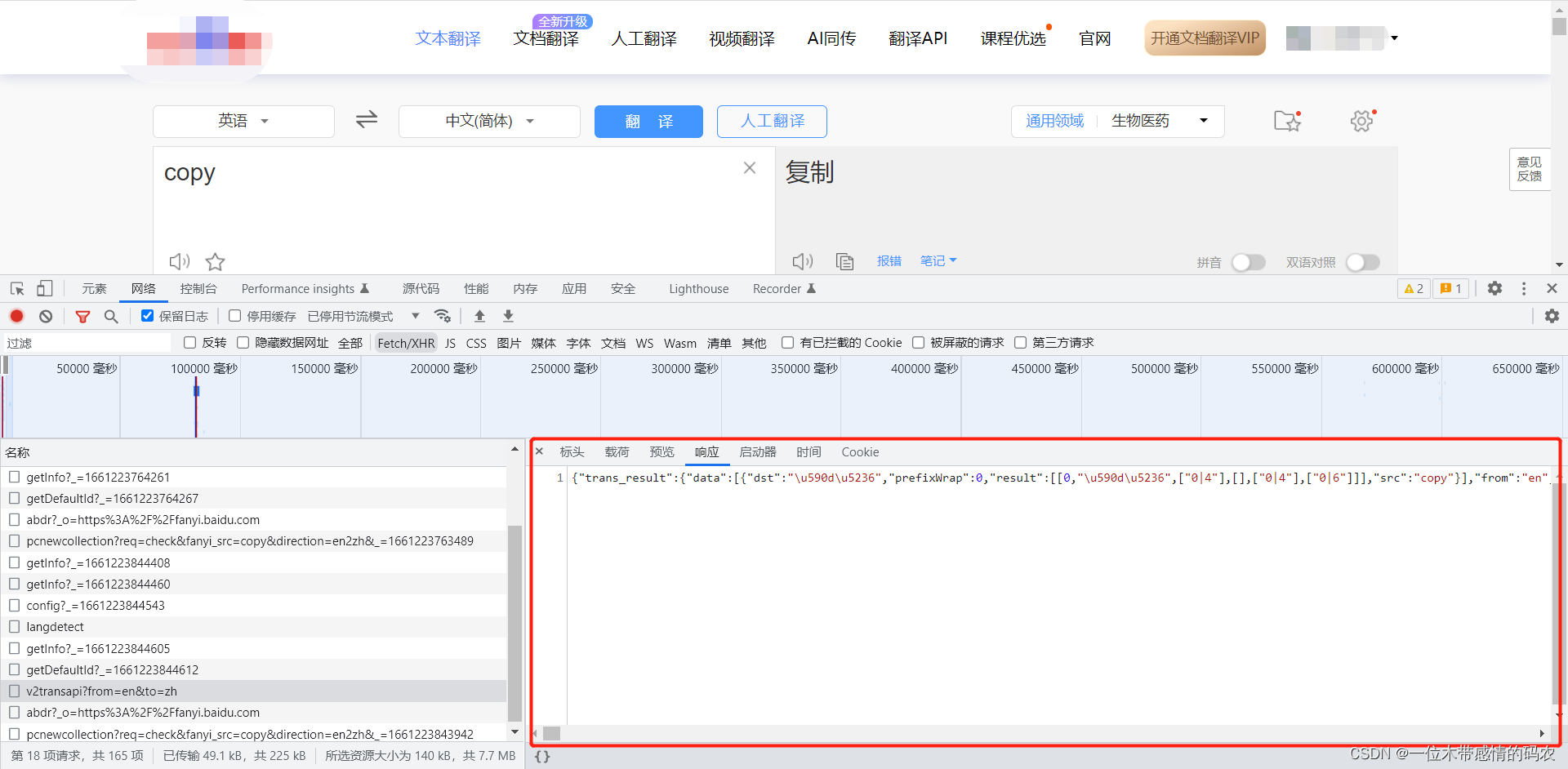
该接口需要的参数如下:
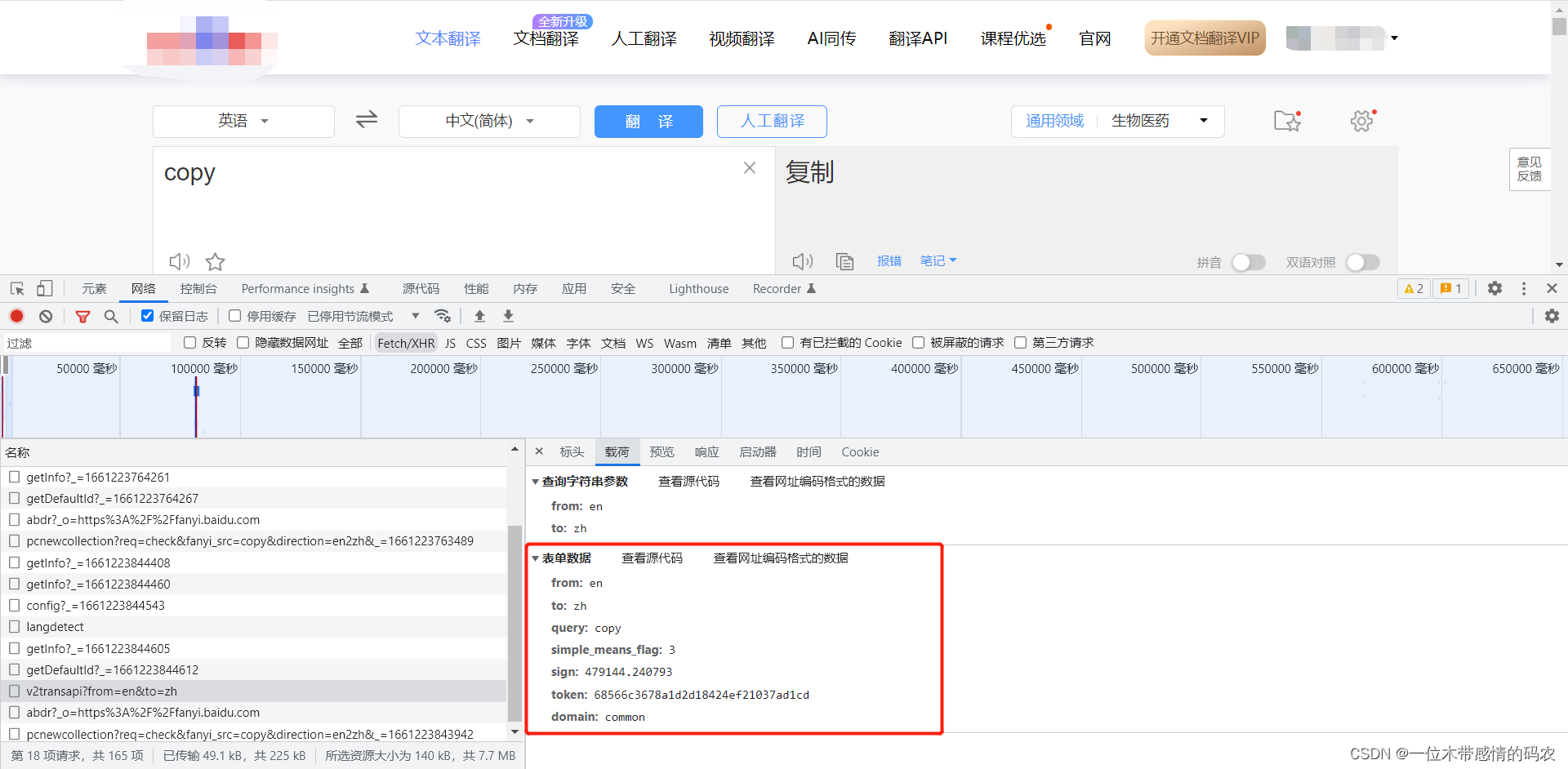
爬虫代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import urllib.request
import urllib.parse
import json
url = 'https://fanyi.某du.com/v2transapi?from=en&to=zh'
data = {
'from': 'en',
'to': 'zh',
'query': 'copy',
'simple_means_flag': '3',
'sign': '479144.240793',
'token': '68566c3678a1d2d18424ef21037ad1cd',
'domain': 'common'
}
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
obj = json.loads(content)
print(obj)
|
运行代码,遇到报错:

这是因为请求头中的数据没有全部放到headers中:
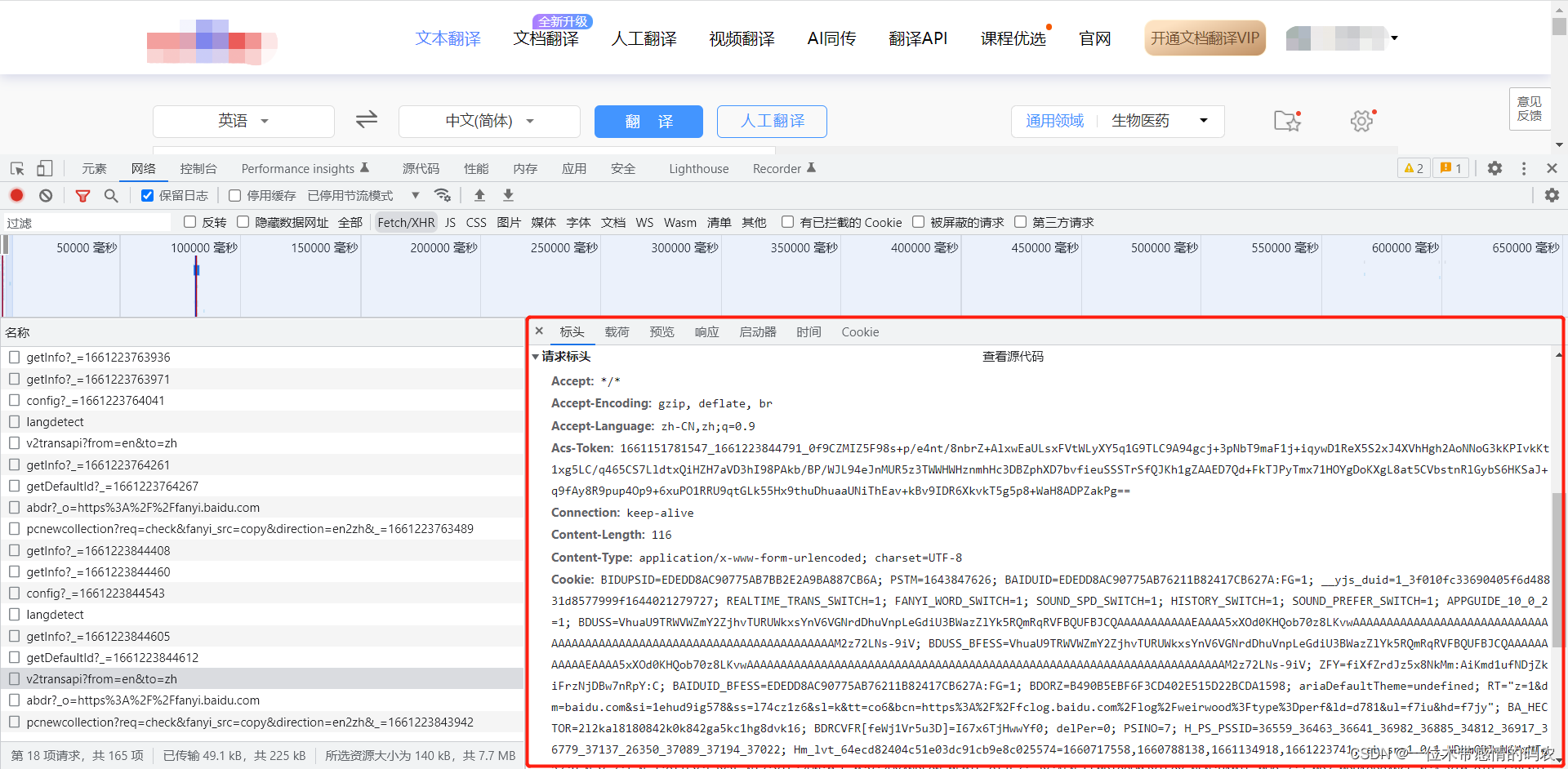
将请求头的数据全部放入headers即可,这里我使用的Sublime Text修改的数据格式,否则手动改还是有些费事:
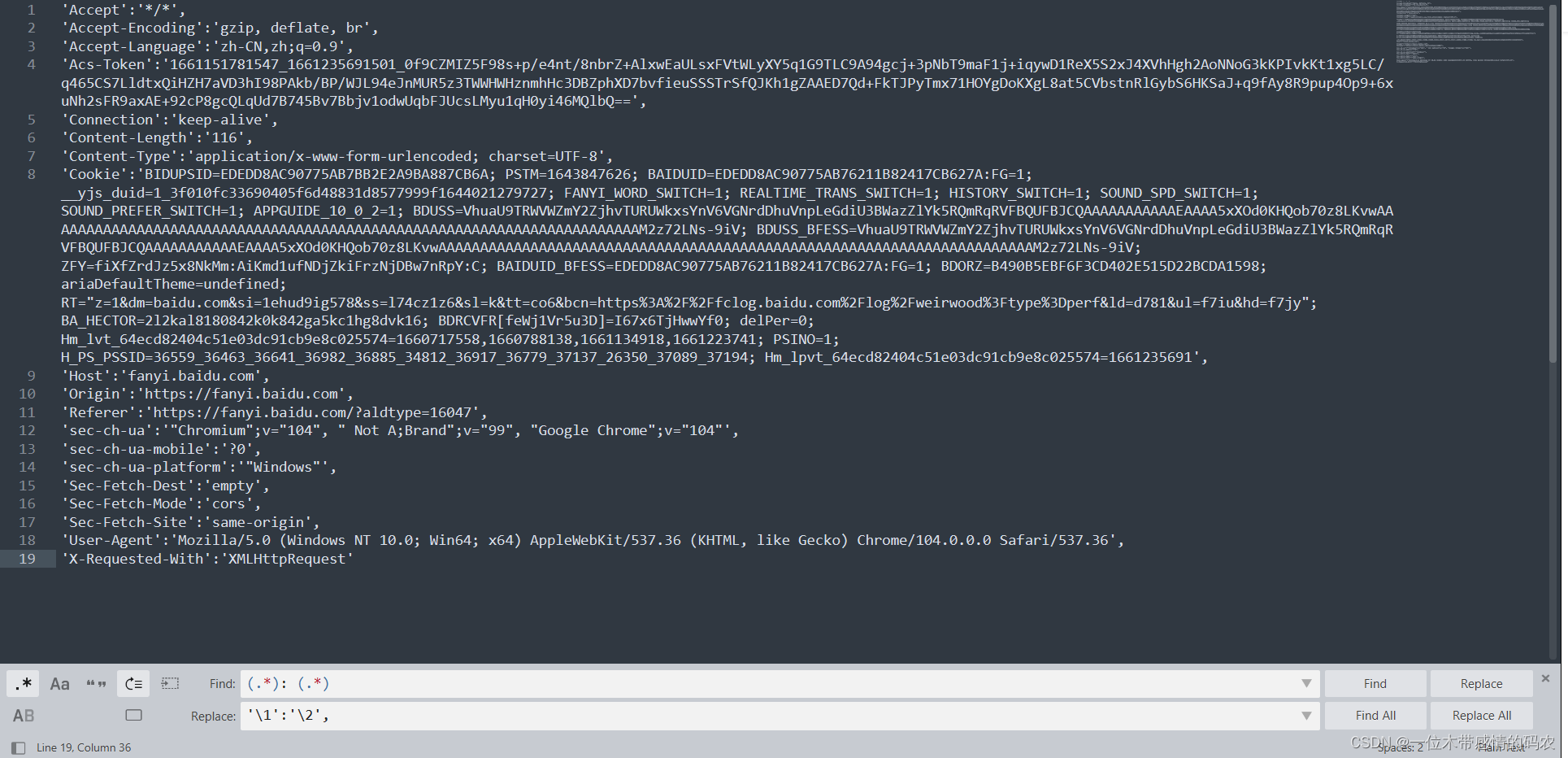
加入请求头数据后的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| import urllib.request
import urllib.parse
import json
url = 'https://fanyi.某du.com/v2transapi?from=en&to=zh'
data = {
'from': 'en',
'to': 'zh',
'query': 'copy',
'simple_means_flag': '3',
'sign': '479144.240793',
'token': '68566c3678a1d2d18424ef21037ad1cd',
'domain': 'common'
}
headers = {
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Acs-Token':'1661151781547_1661235691501_0f9CZMIZ5F98s+p/e4nt/8nbrZ+AlxwEaULsxFVtWLyXY5q1G9TLC9A94gcj+3pNbT9maF1j+iqywD1ReX5S2xJ4XVhHgh2AoNNoG3kKPIvkKt1xg5LC/q465CS7LldtxQiHZH7aVD3hI98PAkb/BP/WJL94eJnMUR5z3TWWHWHznmhHc3DBZphXD7bvfieuSSSTrSfQJKh1gZAAED7Qd+FkTJPyTmx71HOYgDoKXgL8at5CVbstnRlGybS6HKSaJ+q9fAy8R9pup4Op9+6xuNh2sFR9axAE+92cP8gcQLqUd7B745Bv7Bbjv1odwUqbFJUcsLMyu1qH0yi46MQlbQ==',
'Connection':'keep-alive',
'Content-Length':'116',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'BIDUPSID=EDEDD8AC90775AB7BB2E2A9BA887CB6A; PSTM=1643847626; BAIDUID=EDEDD8AC90775AB76211B82417CB627A:FG=1; __yjs_duid=1_3f010fc33690405f6d48831d8577999f1644021279727; FANYI_WORD_SWITCH=1; REALTIME_TRANS_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; APPGUIDE_10_0_2=1; BDUSS=VhuaU9TRWVWZmY2ZjhvTURUWkxsYnV6VGNrdDhuVnpLeGdiU3BWazZlYk5RQmRqRVFBQUFBJCQAAAAAAAAAAAEAAAA5xXOd0KHQob70z8LKvwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAM2z72LNs-9iV; BDUSS_BFESS=VhuaU9TRWVWZmY2ZjhvTURUWkxsYnV6VGNrdDhuVnpLeGdiU3BWazZlYk5RQmRqRVFBQUFBJCQAAAAAAAAAAAEAAAA5xXOd0KHQob70z8LKvwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAM2z72LNs-9iV; ZFY=fiXfZrdJz5x8NkMm:AiKmd1ufNDjZkiFrzNjDBw7nRpY:C; BAIDUID_BFESS=EDEDD8AC90775AB76211B82417CB627A:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; ariaDefaultTheme=undefined; RT="z=1&dm=baidu.com&si=1ehud9ig578&ss=l74cz1z6&sl=k&tt=co6&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=d781&ul=f7iu&hd=f7jy"; BA_HECTOR=2l2kal8180842k0k842ga5kc1hg8dvk16; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1660717558,1660788138,1661134918,1661223741; PSINO=1; H_PS_PSSID=36559_36463_36641_36982_36885_34812_36917_36779_37137_26350_37089_37194; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1661235691',
'Host':'fanyi.baidu.com',
'Origin':'https://fanyi.baidu.com',
'Referer':'https://fanyi.baidu.com/?aldtype=16047',
'sec-ch-ua':'"Chromium";v="104", " Not A;Brand";v="99", "Google Chrome";v="104"',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'"Windows"',
'Sec-Fetch-Dest':'empty',
'Sec-Fetch-Mode':'cors',
'Sec-Fetch-Site':'same-origin',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
obj = json.loads(content)
print(obj)
|
执行后发现还是报错:
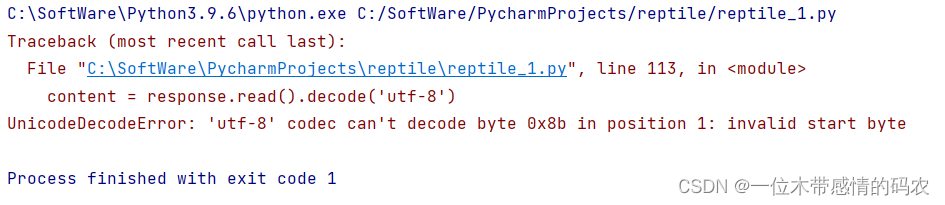
这是因为接收的编码格式不支持utf-8,将'Accept-Encoding':'gzip, deflate, br'注释即可,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| import urllib.request
import urllib.parse
import json
url = 'https://fanyi.某du.com/v2transapi?from=en&to=zh'
data = {
'from': 'en',
'to': 'zh',
'query': 'copy',
'simple_means_flag': '3',
'sign': '479144.240793',
'token': '68566c3678a1d2d18424ef21037ad1cd',
'domain': 'common'
}
headers = {
'Accept':'*/*',
'Accept-Language':'zh-CN,zh;q=0.9',
'Acs-Token':'1661151781547_1661235691501_0f9CZMIZ5F98s+p/e4nt/8nbrZ+AlxwEaULsxFVtWLyXY5q1G9TLC9A94gcj+3pNbT9maF1j+iqywD1ReX5S2xJ4XVhHgh2AoNNoG3kKPIvkKt1xg5LC/q465CS7LldtxQiHZH7aVD3hI98PAkb/BP/WJL94eJnMUR5z3TWWHWHznmhHc3DBZphXD7bvfieuSSSTrSfQJKh1gZAAED7Qd+FkTJPyTmx71HOYgDoKXgL8at5CVbstnRlGybS6HKSaJ+q9fAy8R9pup4Op9+6xuNh2sFR9axAE+92cP8gcQLqUd7B745Bv7Bbjv1odwUqbFJUcsLMyu1qH0yi46MQlbQ==',
'Connection':'keep-alive',
'Content-Length':'116',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'BIDUPSID=EDEDD8AC90775AB7BB2E2A9BA887CB6A; PSTM=1643847626; BAIDUID=EDEDD8AC90775AB76211B82417CB627A:FG=1; __yjs_duid=1_3f010fc33690405f6d48831d8577999f1644021279727; FANYI_WORD_SWITCH=1; REALTIME_TRANS_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; APPGUIDE_10_0_2=1; BDUSS=VhuaU9TRWVWZmY2ZjhvTURUWkxsYnV6VGNrdDhuVnpLeGdiU3BWazZlYk5RQmRqRVFBQUFBJCQAAAAAAAAAAAEAAAA5xXOd0KHQob70z8LKvwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAM2z72LNs-9iV; BDUSS_BFESS=VhuaU9TRWVWZmY2ZjhvTURUWkxsYnV6VGNrdDhuVnpLeGdiU3BWazZlYk5RQmRqRVFBQUFBJCQAAAAAAAAAAAEAAAA5xXOd0KHQob70z8LKvwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAM2z72LNs-9iV; ZFY=fiXfZrdJz5x8NkMm:AiKmd1ufNDjZkiFrzNjDBw7nRpY:C; BAIDUID_BFESS=EDEDD8AC90775AB76211B82417CB627A:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; ariaDefaultTheme=undefined; RT="z=1&dm=baidu.com&si=1ehud9ig578&ss=l74cz1z6&sl=k&tt=co6&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=d781&ul=f7iu&hd=f7jy"; BA_HECTOR=2l2kal8180842k0k842ga5kc1hg8dvk16; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1660717558,1660788138,1661134918,1661223741; PSINO=1; H_PS_PSSID=36559_36463_36641_36982_36885_34812_36917_36779_37137_26350_37089_37194; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1661235691',
'Host':'fanyi.baidu.com',
'Origin':'https://fanyi.baidu.com',
'Referer':'https://fanyi.baidu.com/?aldtype=16047',
'sec-ch-ua':'"Chromium";v="104", " Not A;Brand";v="99", "Google Chrome";v="104"',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'"Windows"',
'Sec-Fetch-Dest':'empty',
'Sec-Fetch-Mode':'cors',
'Sec-Fetch-Site':'same-origin',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
obj = json.loads(content)
print(obj)
|
需要注意的是,在整个请求标头中,最重要的就是cookie,事实上将请求标头中除去cookie外所有的行全部注释,爬虫也能正常运行。
cookie 一般是登录后产生(post),用来保持登录状态的,一般登录一次,下一次访问该网站下的其他网址时就不需要登录了,这就是由于cookie的作用。cookie 就是给无状态的 HTTP/HTTPS 协议添加了一种保持之前状态的功能,这样下次处理信息的时候就不用重新获取信息了。
cookie 还可以来判断是否是爬虫程序,因为一般的爬虫程序中并不会携带 cookie,有些比较严格的网站,不登录也需要携带 cookie 访问,也就是说 cookie 的应用场景并不仅仅只有登录后才需要。
4. Ajax
Ajax 即 “Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是指⼀种创建交互式网页应用的网页开发技术。用于创建快速动态网页,在无需重新加载整个网页的情况下,能够更新部分网页的技术。
通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新,这意味着可以在不重新加载整个网页的情况下,对网页的某个部分进行更新,而传统的网页(不使用 Ajax)如果需要更新内容,必须重载整个页面。
4.1 Ajax的get请求
以爬取某瓣网电影前十页数据为案例,某瓣网的分页就是用Ajax实现的。先完成一个小目标,爬取第一页数据,找到某瓣网数据接口:
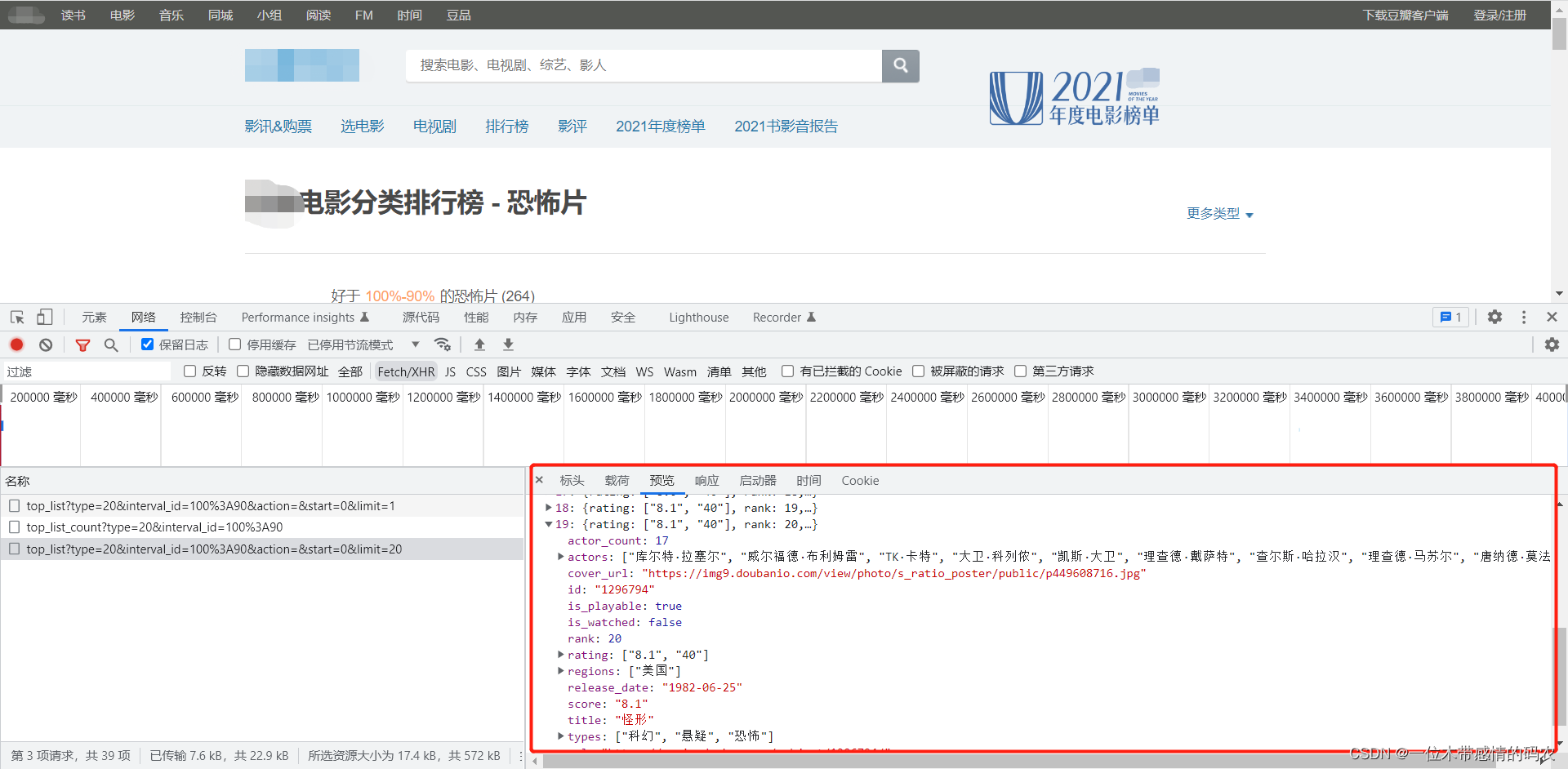
爬取首页数据并写入到文件中:
1
2
3
4
5
6
7
8
9
10
| import urllib.request
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
url = 'https://movie.某ban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&start=0&limit=20'
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
file = open('douban.json', 'w', encoding='utf-8')
file.write(content)
|
查看文件内容,快捷键ctrl+alt+L自动对齐,已爬取到第一页的数据:
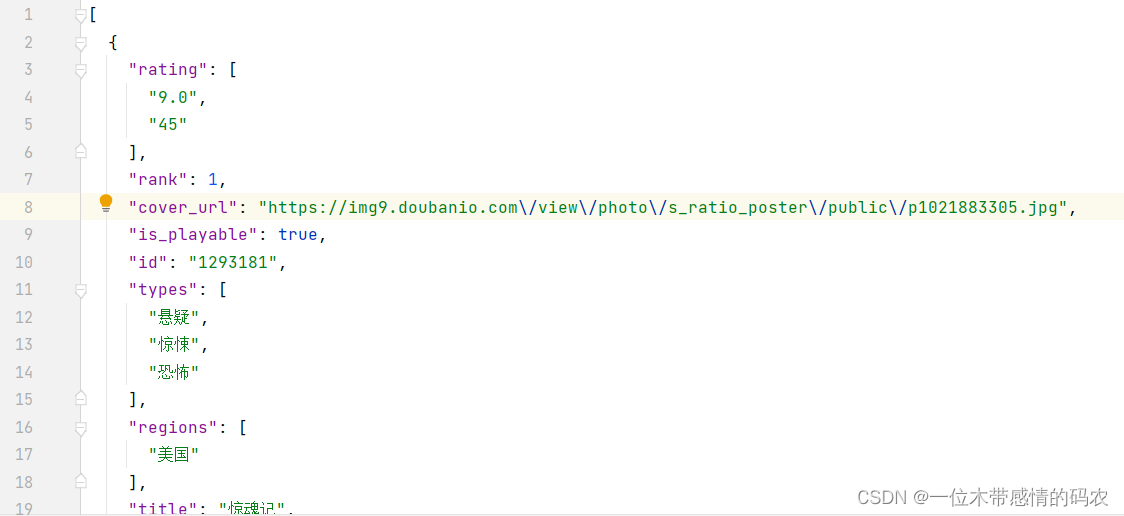
下面就是爬取前十页的数据了。通过观察,找到下面三个接口,这三个接口是豆瓣网电影前三页的接口,可以明显看到这三个接口的规律,接口是根据start=(page-1)*20来区分页数的:
1
2
3
| https://movie.某ban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&start=0&limit=20
https://movie.某ban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&start=20&limit=20
https://movie.某ban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&start=40&limit=20
|
知道了接口规律,那么接下来就是爬取前十页数据了,代码已封装:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import urllib.request
import urllib.parse
def create_request(page):
base_url = 'https://movie.某ban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
data = {
'start': (page - 1) * 20,
'limit': 20
}
data = urllib.parse.urlencode(data)
url = base_url + data
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page, content):
with open('douban_' + str(page) + '.json', 'w', encoding='utf-8') as file:
file.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page, end_page + 1):
request = create_request(page)
content = get_content(request)
down_load(page, content)
|
运行代码可以得到对应页面的数据文件,效果我就不放了。
4.2 Ajax的post请求
下面以爬取某德基餐厅信息的案例来演示,如何爬取Ajax的post请求。先登录某德基官网,找到对应的post接口。(图片违规,不让我放上来。。。。。。。)
然后通过对比前三页接口的不同,找到不同页码接口之间的规律:

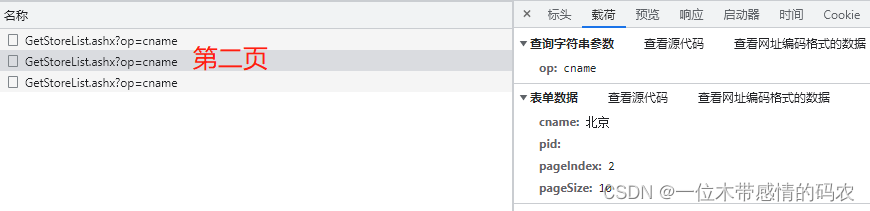
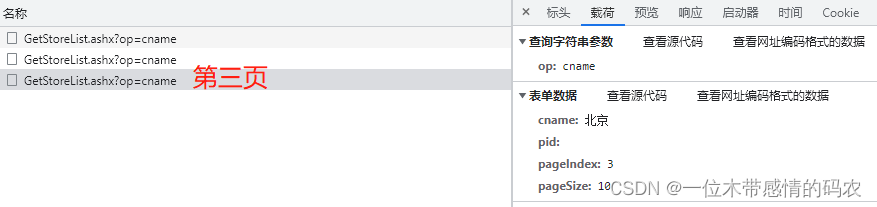
可以明显发现,该接口是通过pageIndex参数控制页码,pageSize控制每页的数量,cname控制地区。下面就直接放代码了,难点不多:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| import urllib.request
import urllib.parse
def create_request(page):
base_url = 'http://www.某fc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
data = {
'cname': '北京',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=base_url, data=data, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page, content):
with open('某fc_' + str(page) + '.json', 'w', encoding='utf-8') as file:
file.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page, end_page + 1):
request = create_request(page)
content = get_content(request)
down_load(page, content)
|
5. 捕获异常
如果我们想让自己的爬虫代码更加健壮的话,也是需要捕获异常的,这里就介绍两个异常类,HTTPError和URLError,HTTPError类是URLError类的子类。
当然实际平时爬虫的使用中,捕获异常使用的并不多,所以我这里就不做过多的介绍了,直接拿上一个某德基的代码改一下放这里:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| import urllib.request
import urllib.parse
import urllib.error
def create_request(page):
base_url = 'http://www.某fc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
data = {
'cname': '北京',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=base_url, data=data, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page, content):
with open('某fc_' + str(page) + '.json', 'w', encoding='utf-8') as file:
file.write(content)
if __name__ == '__main__':
try:
start_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page, end_page + 1):
request = create_request(page)
content = get_content(request)
down_load(page, content)
except urllib.error.HTTPError:
print('系统正在升级')
except urllib.error.URLError:
print('您访问的域名不存在')
|
6. cookie登录
在很多网站中,和上面案例中的网站有一个不一样的地方,就是未登录状态和登录状态所展示出来的数据是不一样的,这里就讲一下,如果想采集登录之后才展示出来的数据,应该怎么去写代码。这里就以某博https://某bo.cn/为例,采集个人主页的信息,首先按照上面讲过的代码进行尝试(因为涉及个人隐私,所以代码中的链接 uid 和后续的 cookie 我都会做随机修改处理,各位以自己的为准即可):
1
2
3
4
5
6
7
8
9
10
11
| import urllib.request
import urllib.parse
url = 'https://某bo.cn/6328349562/info'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
|
运行代码会发现编码不对:

而查看个人信息网页的源代码,编码格式确实是utf-8,之所以编码不对是因为我们没有登录信息,请求个人信息主页时会自动跳转到登录页面,而登录页面的编码格式却是gb2312,这也是一个小的爬虫手段,所以我们只需要改一下编码格式为gb2312即可。可是随之而来的问题是,我们这样获取的是登录页面的信息,而我们实际想要的是个人信息主页,应该怎么去绕过登录页面直接到达个人信息主页呢,这就需要一个重要的东西,就是cookie,在个人信息主页,打开检查,点击网络的info,将请求头的东西都复制出来:
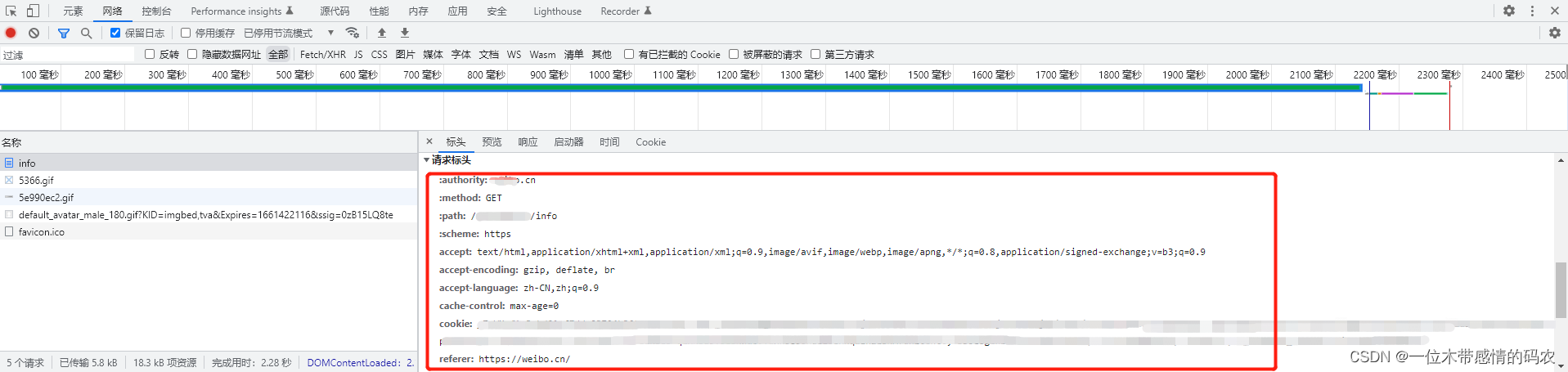
前面带有冒号的可以不要,放入代码的headers中,可以用前面说过的正则方法,方便快捷。注意编码格式需要改回utf-8,因为这里不需要再去登录页了,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import urllib.request
import urllib.parse
url = 'https://某bo.cn/6347449799/info'
headers = {
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language':'zh-CN,zh;q=0.9',
'cache-control':'max-age=0',
'cookie':'_T_WM=f1c3ebd01cf7dde23704b362ixs82v8q; SUB=_2A25OA26gDeRhGeBN71UV9CfLwjWIHXVtDHLorDV6PUNbktANLUjfkmdQ7XiRIiAWGcim-RPUJFDBLv9yPaBCUSFB; SUBP=0033WrSXqPxfM725Ws9jqgMF26451P9D9WFzL6FUia2PJzLiF9NnWlEC5JpX5KzhUgL.Foq0ShNESD.N2K.2dKCoIE7LxK-L1KBLB-qLxKBLB.BLBKWaUJYLxKBLBonL12BLxKqL1MDUVG6Efeh2centt; SSOLoginState=1661038641; ALF=1664046284; MLOGIN=1; M_WEIBOCN_PARAMS=luicode%3D20084629',
'referer':'https://weibo.cn/',
'sec-ch-ua':'"Chromium";v="104", " Not A;Brand";v="99", "Google Chrome";v="104"',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'"Windows"',
'sec-fetch-dest':'document',
'sec-fetch-mode':'navigate',
'sec-fetch-site':'same-origin',
'sec-fetch-user':'?1',
'upgrade-insecure-requests':'1',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
|
如此便可获取到个人主页的信息,效果图我就不放了,懒。
7. Handler处理器
随着业务逻辑逐渐复杂,请求对象的定制已经满足不了我们的需求,长期爬取一个网站,会被网站识别为爬虫,对我们的设备进行封 IP 操作,所以我们就需要动态cookie和代理来解决这个问题,而代理就是以Handler为基础,这里还是先用百度的简单案例,讲一下如何使用Handler处理器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import urllib.request
import urllib.parse
url = 'https://www.某du.com'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
request = urllib.request.Request(url=url, headers=headers)
handler = urllib.request.HTTPHandler()
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)
|
8. 代理的基本使用
当我们使用爬虫长期、高频的访问某个网站,就会被识别为爬虫,封禁设备 IP,从而导致无法访问该网站,而代理,就是为了隐藏我们的真实 IP,防止被封禁。当然代理不仅仅是这一个用途,像我们打游戏时开的加速器就是代理,访问外网的资源也需要使用代理,以及一些私密单位的内部资源都需要代理来进行访问,代理也能用来提高访问速度,通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
那么下面我就来演示一下,如何用代理爬取网站信息。首先我们上某度网站,某度ip,可以直接显示出我们的本机ip:
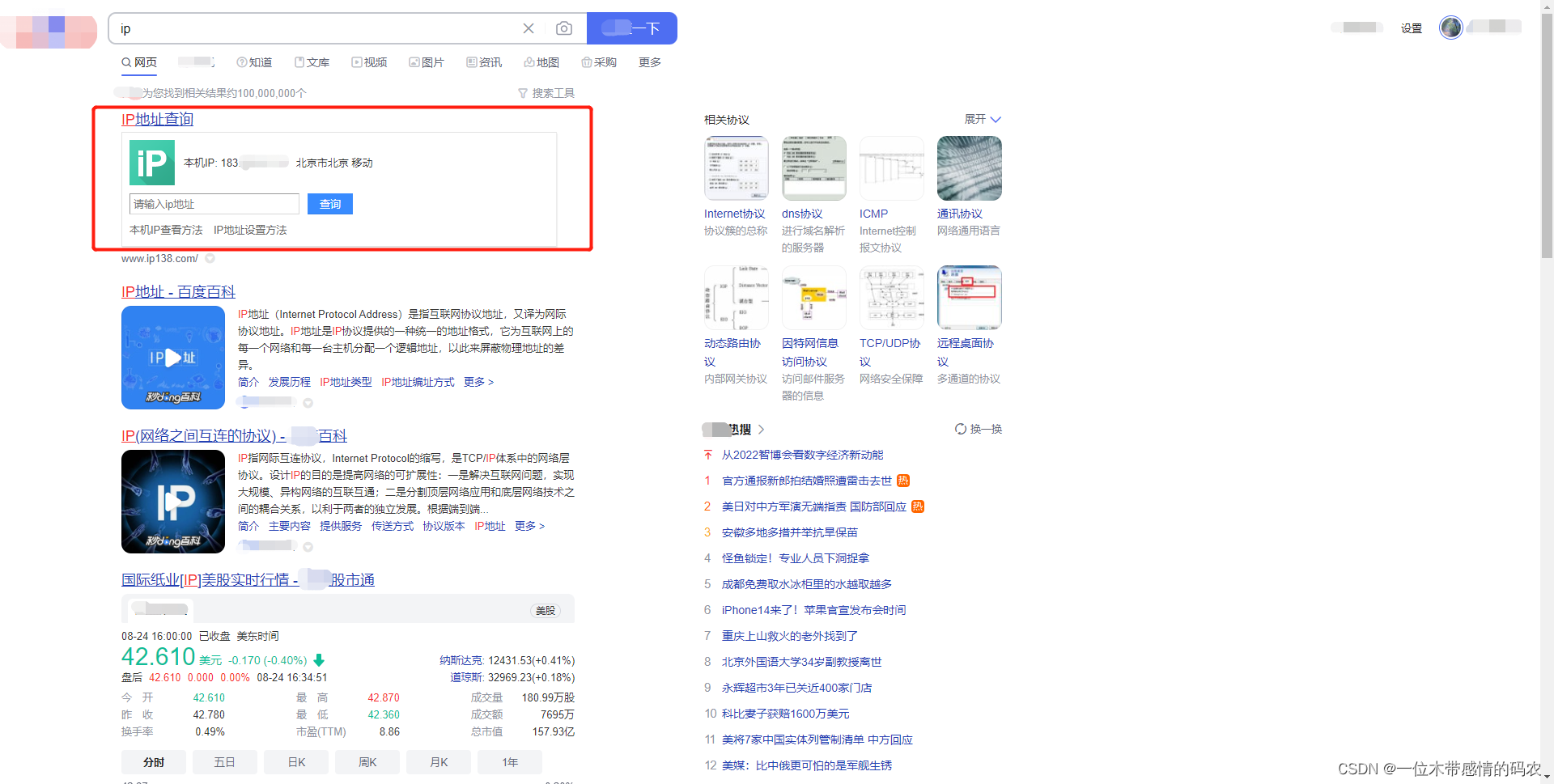
我们先使用之前请求对象定制的方法,来爬取该网站信息看是否能正常获取到:
1
2
3
4
5
6
7
8
9
10
11
12
| import urllib.request
import urllib.parse
url = 'https://www.某du.com/s?wd=ip'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
with open('代理.html', 'w', encoding='utf-8') as file:
file.write(content)
|
打开代理.html文件,可以看到和我们正常访问一模一样。
然后换成Hanlder处理器,使用代理访问,我这里用的是快代理网站的免费代理,连接不太稳定,可能换几个代理才有一个能用的:
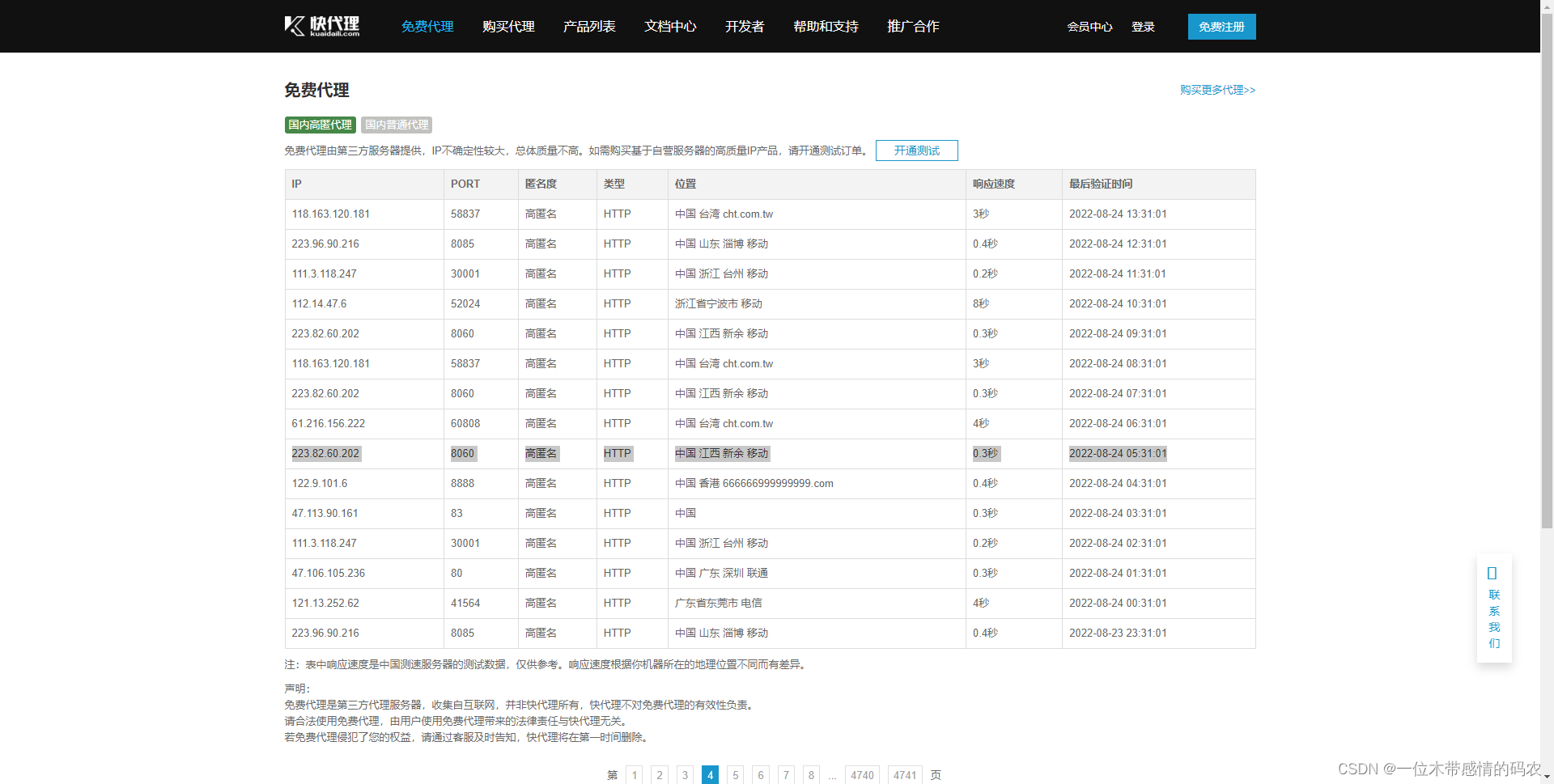
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| import urllib.request
import urllib.parse
url = 'http://www.某du.com/s?wd=ip'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
proxies = {
'http': '223.82.60.202:8060'
}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('代理.html', 'w', encoding='utf-8') as file:
file.write(content)
|
效果图如下:
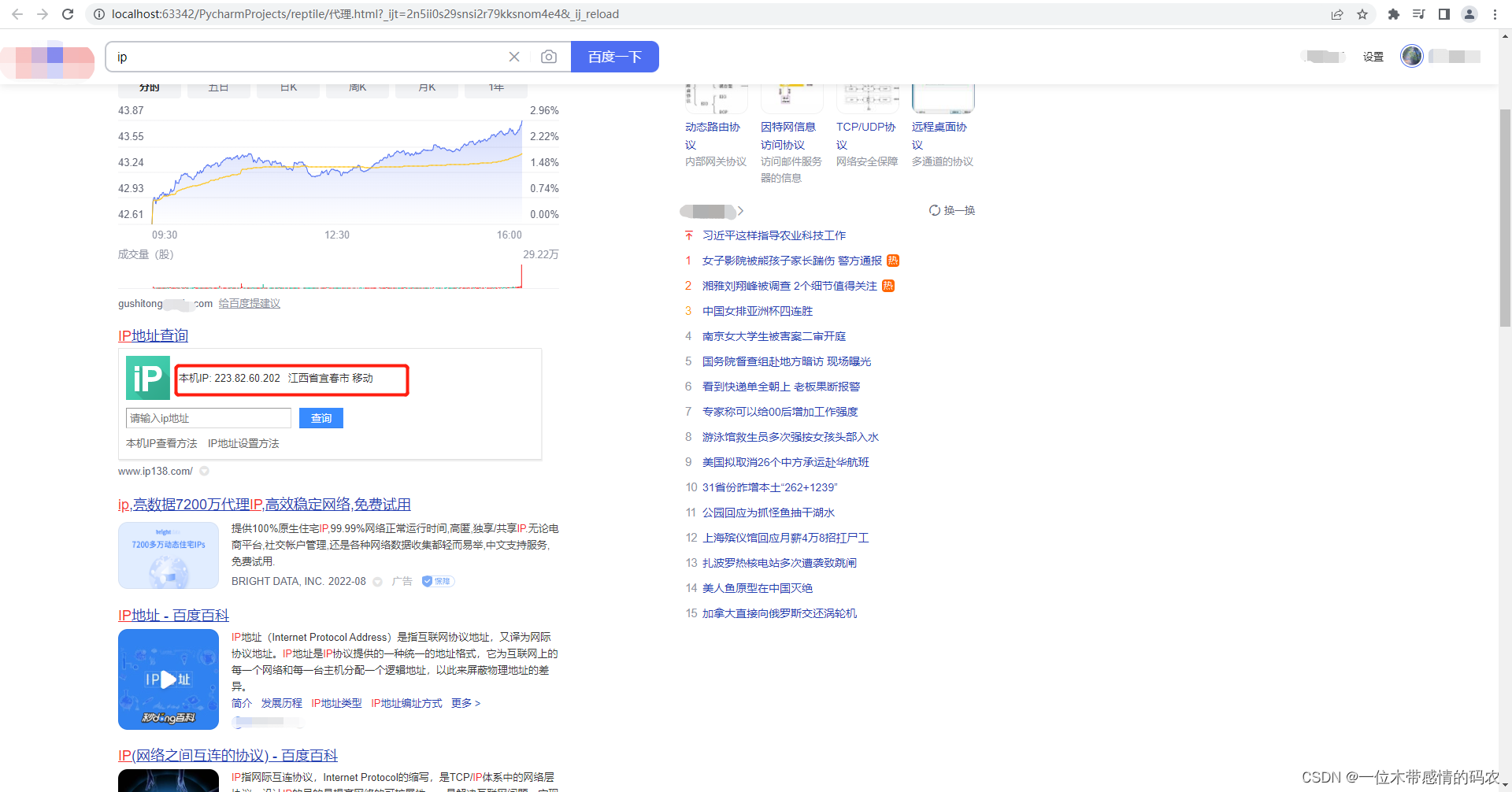
当然在我们实际生产中,只用一个代理也是不现实的,也会面临被封ip的风险,所有就有了代理池的概念。
代理池就是由代理IP组成的池子, 它可以提供多个稳定可用的代理IP。
我们在做爬虫的时候, 最常见一种反爬手段就是ip反爬,也就是当同一个ip高频的访问这个网站次数过多,就会限制这个ip访问。所以就需要使用代理来隐藏我们的真实ip,同时为了保证我们的代理能长期稳定的使用,就需要随机使用代理池里的代理地址,最简单的代理池实现方式就是将代理地址都放到一个列表里,创建一个随机数,每次请求都随机的从代理池中取一个代理使用,我这里就不贴代码了,就是一个很简单的功能。
这篇博客就说这些简单的爬虫基础吧,已经万字长文了,后面再更新深入的爬虫相关知识。
参考文献
【1】https://www.bilibili.com/video/BV1Db4y1m7Ho?p=51
【2】https://blog.csdn.net/itcast_cn/article/details/123678415
【3】https://www.runoob.com/python3/python-urllib.html
【4】https://blog.csdn.net/m0_46473590/article/details/118328217
【5】https://blog.csdn.net/Y_peak/article/details/120068358
【6】https://www.weixueyuan.net/a/739.html






