
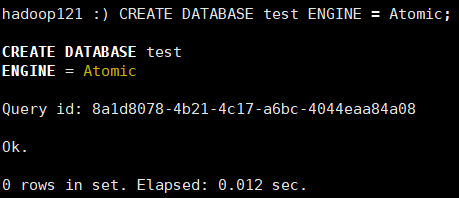
ClickHouse 实时分析(五)- ClickHouse 的操作使用指南
1. ClickHouse的使用
ClickHouse 本身作为一个数据库,对普通增删改查的操作都是支持的。但是,他针对数仓的使用场景,又有非常多的高级特性。对这些高级特性的掌握程度将直接影响 ClickHouse 的使用效率。实现一个同样的查询逻辑,不同的 SQL 写法在 ClickHouse 上很容易体现出非常非常大的执行时长差别。所以在使用 ClickHouse 时,需要对这些特性非常重视。
使用数据库首先要建库,ClickHouse 提供了多种库引擎实现不同场景下的库声明。
1.1 Atomic库引擎
这是 ClickHouse 默认的库引擎。默认创建的 default 库就是使用的这种引擎,可以在建库时进行声明。它支持非阻塞的DROP TABLE和RENAME TABLE查询和原子的EXCHANGE TABLES t1 AND t2查询。
1 | CREATE DATABASE testdb ENGINE = Replicated('zoo_path', 'shard_name', 'replica_name') [SETTINGS ...] |
zoo_path——ZooKeeper 地址,同一个 ZooKeeper 路径对应同一个数据库。shard_name——分片的名字,数据库副本按 shard_name 分组到分片中。replica_name——副本的名字,同一分片的所有副本的副本名称必须不同。
Atomic 类型的数据库完全由 ClickHouse 自己管理数据。每个数据库对应/var/lib/clickhouse/data目录下的一个子目录。数据库中的每个表会分配一个唯一的 UUID,数据存储在目录 /var/lib/clickhouse/store/xxx/xxxyyyyy-yyyy-yyyyyyyy-yyyyyyyyyyyy/,其中xxxyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy是该表的
UUID。
更多操作可以参考官网:https://clickhouse.com/docs/zh/engines/database-engines/atomic/,这里就不再细说了。
除了 Atomic 引擎,ClickHouse 还提供了丰富的库引擎,包括 MySql、SQLite、PostgreSQL等等,有兴趣的了解的可以去 ClickHouse 官网了解:https://clickhouse.com/docs/zh/。
2. SQL操作
基本上来说传统关系型数据库(以 MySQL 为例)的 SQL 语句,ClickHouse 基本都支持, 这里不会从头讲解 SQL 语法只介绍 ClickHouse 与标准 SQL(MySQL)不一致的地方。
2.1 Insert
基本与标准 SQL(MySQL)基本一致。
- 标准
insert into [table_name] values(…),(….)
- 从表到表的插入
insert into [table_name] select a,b,c from [table_name_2]
更多操作可参考官网:https://clickhouse.com/docs/zh/sql-reference/statements/insert-into/
2.2 Update和Delete
ClickHouse 提供了 Delete 和 Update 的能力,这类操作被称为 Mutation 查询,它可以看做 Alter 的一种。
虽然可以实现修改和删除,但是和一般的 OLTP 数据库不一样,Mutation 语句是一种很“重”的操作,而且不支持事务。
“重” 的原因主要是每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。所以尽量做批量的变更,不要进行频繁小数据的操作。
- 删除操作
alter table t_order_smt delete where sku_id ='sku_001';
- 修改操作
alter table t_order_smt update total_amount=toDecimal32(2000.00,2) where id=102;
由于操作比较“重”,所以 Mutation 语句分两步执行,同步执行的部分其实只是进行新增数据新增分区和并把旧分区打上逻辑上的失效标记。直到触发分区合并的时候,才会删除旧数据释放磁盘空间,一般不会开放这样的功能给用户,由管理员完成。
更多操作可参考官网:https://clickhouse.com/docs/zh/sql-reference/statements/alter/
2.3 查询操作
ClickHouse 基本上与标准 SQL 差别不大:
- 支持子查询;
- 支持 CTE(Common Table Expression 公用表表达式 with 子句);
- 支持各种 JOIN, 但是 JOIN 操作无法使用缓存,所以即使是两次相同的 JOIN 语句,ClickHouse 也会视为两条新 SQL;
- 窗口函数;
- 不支持自定义函数;
- GROUP BY 操作增加了 with rollup\with cube\with total 用来计算小计和总计;
- 插入数据:
1 | insert into t_order_mt values |
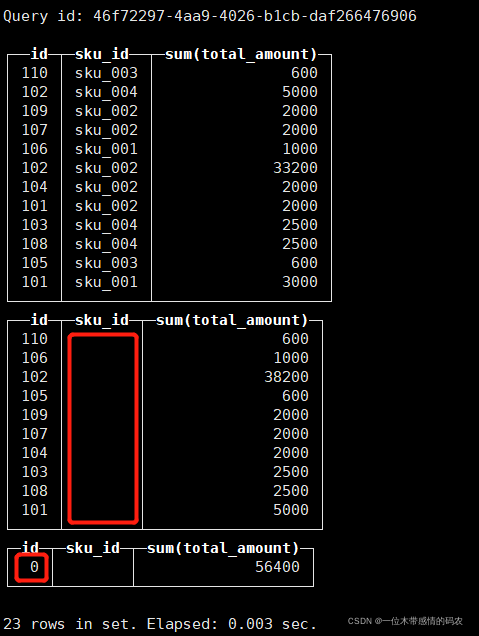
- with rollup:从右至左去掉维度进行小计。
select id , sku_id,sum(total_amount) from t_order_mt group by id,sku_id with rollup;
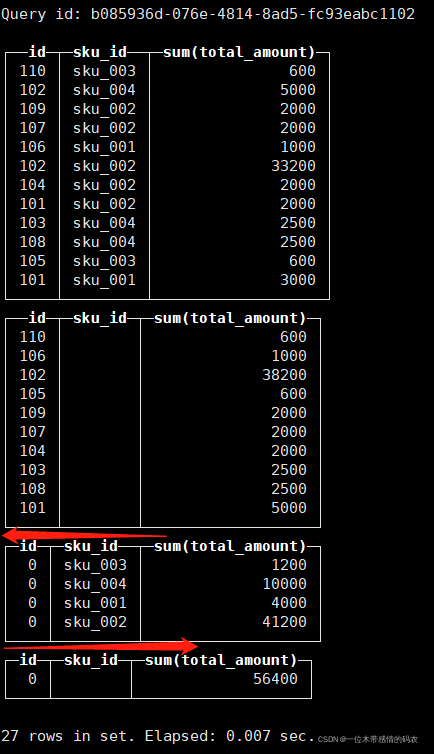
- with cube:从右至左去掉维度进行小计,再从左至右去掉维度进行小计。
select id , sku_id,sum(total_amount) from t_order_mt group by id,sku_id with cube;
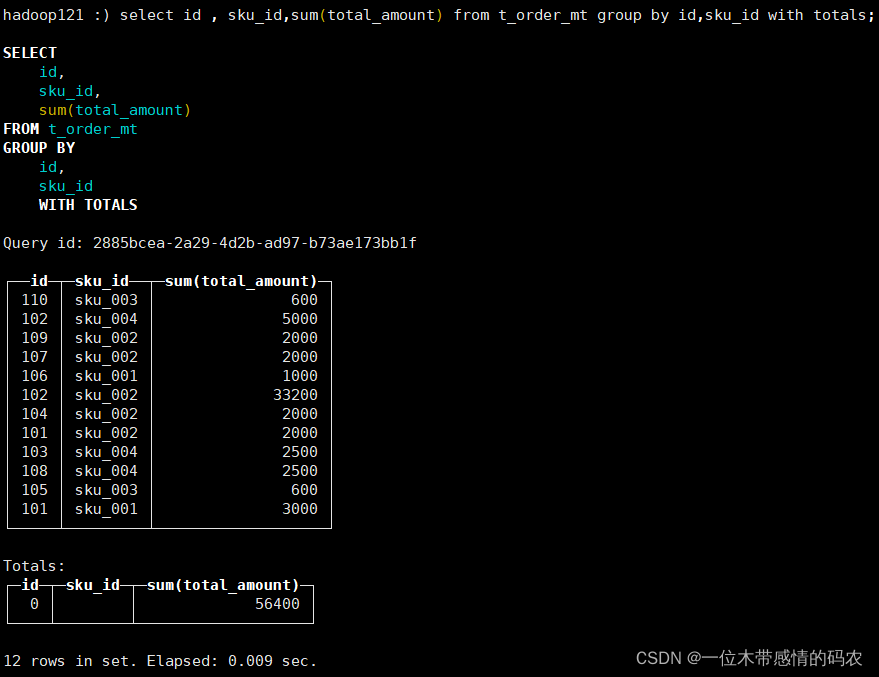
- with totals: 只计算合计。
select id , sku_id,sum(total_amount) from t_order_mt group by id,sku_id with totals;
2.4 alter操作
同 MySQL 的修改字段基本一致。
- 新增字段;
1 | alter table tableName add column newcolname String after col1; |
- 修改字段类型;
1 | alter table tableName modify column newcolname String; |
- 删除字段;
1 | alter table tableName drop column newcolname; |
3. 数据导入导出
使用 ClickHouse 首先需要有数据。我们之前也通过 insert into 语句造了一些测试数据,但是这种方式,在 ClickHouse 中是非常不推荐的。一方面,insert 语句插入数据,效率太低。ClickHouse 是面向海量数据进行查询分析,insert 语句很难用来形成海量的数据。另一方面,ClickHouse 常用的 MergeTree 表引擎,会将新插入的数据放到一个临时的分区当中,后续需要进行数据合并。频繁的 insert 操作会产生大量的临时分区,增加数据合并的性能消耗。所以,ClickHouse 中通常情况下都是通过数据文件进行大批量的导出导入操作来产生的。常用的数据导入导出方式是通过clickhouse-client客户端写入或读取 csv 文件来完成。
例如导出数据到 csv 文件:
1 | clickhouse-client -h 127.0.0.1 --database="defalut" --query="select * from t_stock FORMAT CSV" > t_stock.csv |
从 csv 文件导入数据:
1 | clickhouse-client -h 127.0.0.1 --database="default" --query="insert into t_stock FORMAT CSV" < ./test.csv |
另外,官方也提供了一个clickhouse-copier工具来专门对 ClickHouse 数据进行备份与恢复。
同时,官方也提供了大量高质量的数据集可供测试。因此我们需要将这些高质量的数据集导入到 ClickHouse 中,这样对于学习 ClickHouse 是非常方便高效的。
官网数据集可参考:https://clickhouse.com/docs/zh/getting-started/example-datasets/github-events/
学习过程中,常用的数据集还是线上测试数据库中用到的数据,也就是Yandex.Metric Data数据集。数据集包含两张表hits_v1和visits_v1。数据集可以从官方网站上下载。参见https://clickhouse.com/docs/zh/getting-started/example-datasets/metrica/。
而这个官方文件的导入过程相当简单粗暴,那就是直接转移数据文件。
- 导入 hits_v1 表;
1 | tar -xvf hits_v1.tar -C /var/lib/clickhouse |
- 导入 vits_v1 表;
1 | tar -xvf visits_v1.tar -C /var/lib/clickhouse |
- 解压出来的文件分配给 ClickHouse 用户(可选);
1 | chown -R clickhouse:clickhouse /var/lib/clickhouse |
- 重启 ClickHouse 服务;
1 | systemctl restart clickhouse-server |
重启完成后,就可以在 ClickHouse 中查到一个 datasets 数据以及 hits_v1 和 visits_v1 两张表。hits_v1 表使用的是MergeTree引擎,拥有 800W+ 的数据。visits_v1 表使用的是CollapsingMergeTree引擎,拥有 160W+ 的数据。
更多支持格式参照:https://clickhouse.com/docs/zh/interfaces/formats/。
参考文献
【1】https://clickhouse.com/docs/zh/
【2】https://www.bilibili.com/video/BV1Yh411z7os?from=search&seid=4579023877699743987&spm_id_from=333.337.0.0



