
ClickHouse 实时分析(一)- ClickHouse 入门
1. 什么是ClickHouse
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C++ 语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。
1.1 OLAP场景的关键特征
- 绝大多数是读请求;
- 数据以相当大的批次(>1000行)更新,而不是单行更新,或者根本没有更新;
- 已添加到数据库的数据不能修改;
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分;
- 宽表,即每个表包含着大量的列;
- 查询相对较少(通常每台服务器每秒查询数百次或更少);
- 对于简单查询,允许延迟大约 50 毫秒;
- 列中的数据相对较小,数字和短字符串(例如,每个 URL 60个字节);
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行);
- 事务不是必须的;
- 对数据一致性要求低;
- 每个查询有一个大表,除了它以外,其他的都很小;
- 查询结果明显小于源数据,换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的 RAM 中;
很容易可以看出,OLAP 场景与其他通常业务场景(例如,OLTP 或 K/V)有很大的不同, 因此想要使用 OLTP 或 Key-Value 数据库去高效的处理分析查询场景,并不是非常完美的适用方案。例如,使用 OLAP 数据库去处理分析请求通常要优于使用 MongoDB 或 Redis 去处理分析请求。
1.2 列式数据库更适合OLAP场景的原因
列式数据库更适合于 OLAP 场景(对于大多数查询而言,处理速度至少提高了 100 倍),下面通过图片详细解释原因:
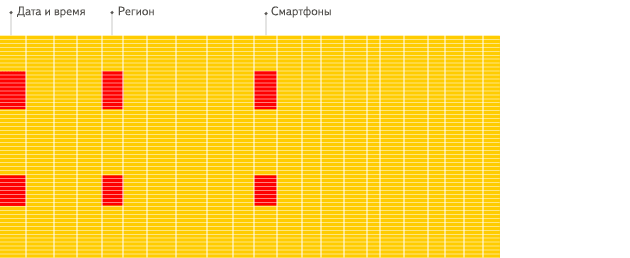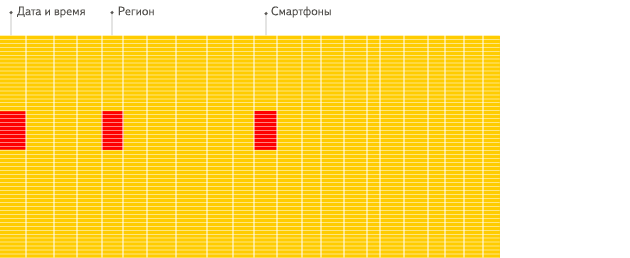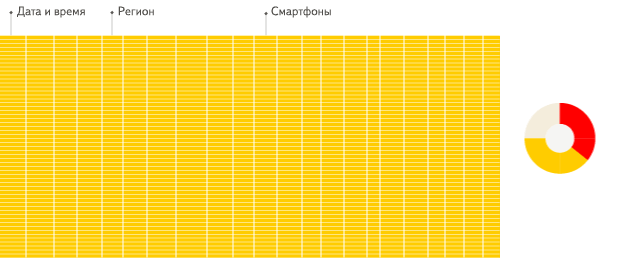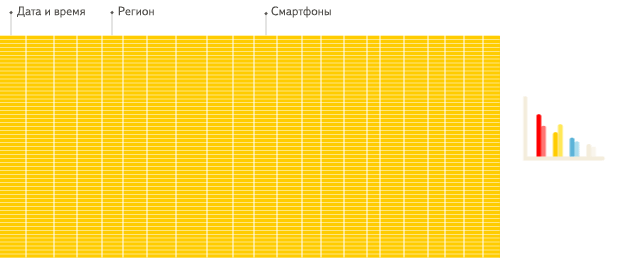
行式:
列式:
下面将详细介绍为什么会发生这种情况。
1.2.1 输入/输出
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取 100 列中的 5 列,这将帮助你最少减少 20 倍的 IO 消耗;
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩,这进一步降低了 IO 的体积;
- 由于 IO 的降低,这将帮助更多的数据被系统缓存;
例如,查询统计每个广告平台的记录数量需要读取广告平台ID这一列,它在未压缩的情况下需要 1 个字节进行存储。如果大部分流量不是来自广告平台,那么这一列至少可以以十倍的压缩率被压缩。当采用快速压缩算法,它的解压速度最少在十亿字节(未压缩数据)每秒。换句话说,这个查询可以在单个服务器上以每秒大约几十亿行的速度进行处理。这实际上是当前实现的速度。
1.2.2 CPU
由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效。同时这将有助于实现一个几乎没有调用成本的查询引擎。如果你不这样做,使用任何一个机械硬盘,查询引擎都不可避免的停止 CPU 进行等待。所以,在数据按列存储并且按列执行是很有意义的。
有两种方法可以做到这一点:
- 向量引擎:所有的操作都是为向量而不是为单个值编写的。这意味着多个操作之间的不再需要频繁的调用,并且调用的成本基本可以忽略不计。操作代码包含一个优化的内部循环;
- 代码生成:生成一段代码,包含查询中的所有操作;
这是不应该在一个通用数据库中实现的,因为这在运行简单查询时是没有意义的。但是也有例外,例如,MemSQL 使用代码生成来减少处理 SQL 查询的延迟(只是为了比较,分析型数据库通常需要优化的是吞吐而不是延迟)。
为了提高 CPU 效率,查询语言必须是声明型的(SQL 或 MDX), 或者至少一个向量 (J, K)。 查询应该只包含隐式循环,允许进行优化。
2. ClickHouse的特点
2.1 列式存储
以下面的表为例:
| Id | Name | Age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 22 |
| 3 | 王五 | 34 |
- 采用行式存储时,数据在磁盘上的组织结构为:
| 1 | 张三 | 18 | 2 | 李四 | 22 | 3 | 王五 | 34 |
好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
- 采用列式存储时,数据在磁盘上的组织结构为:
| 1 | 2 | 3 | 张三 | 李四 | 王五 | 18 | 22 | 34 |
这时想查所有人的年龄只需把年龄那一列拿出来就可以了。
- 列式储存的好处:
- 对于列的聚合,计数,求和等统计操作原因优于行式存储;
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重;
- 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于 cache 也有了更大的发挥空间;
在一个真正的列式数据库管理系统中,除了数据本身外不应该存在其他额外的数据。这意味着为了避免在值旁边存储它们的长度number,你必须支持固定长度数值类型。例如,10亿 个 UInt8 类型的数据在未压缩的情况下大约消耗 1GB 左右的空间,如果不是这样的话,这将对 CPU 的使用产生强烈影响。即使是在未压缩的情况下,紧凑的存储数据也是非常重要的,因为解压缩的速度主要取决于未压缩数据的大小。
这是非常值得注意的,因为在一些其他系统中也可以将不同的列分别进行存储,但由于对其他场景进行的优化,使其无法有效的处理分析查询。例如:HBase,BigTable,Cassandra,HyperTable。在这些系统中,你可以得到每秒数十万的吞吐能力,但是无法得到每秒几亿行的吞吐能力。
需要说明的是,ClickHouse 不单单是一个数据库, 它是一个数据库管理系统。因为它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置或重启服务。
2.2 数据压缩
在一些列式数据库管理系统中(例如:InfiniDB CE 和 MonetDB)并没有使用数据压缩。但是, 若想达到比较优异的性能,数据压缩确实起到了至关重要的作用。
除了在磁盘空间和 CPU 消耗之间进行不同权衡的高效通用压缩编解码器之外,ClickHouse 还提供针对特定类型数据的专用编解码器,这使得 ClickHouse 能够与更小的数据库(如时间序列数据库)竞争并超越它们。
更多信息可参考下方链接:https://clickhouse.com/docs/zh/sql-reference/statements/create/#create-query-specialized-codecs
2.3 数据的磁盘存储
许多的列式数据库(如 SAP HANA,Google PowerDrill)只能在内存中工作,这种方式会造成比实际更多的设备预算。
ClickHouse 被设计用于工作在传统磁盘上的系统,它提供每 GB 更低的存储成本,但如果可以使用 SSD 和内存,它也会合理的利用这些资源。
2.4 DBMS的功能
数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。
ClickHouse 支持一种基于 SQL 的声明式查询语言,它在许多情况下与ANSI SQL标准相同,几乎覆盖了标准 SQL 的大部分语法,包括 DDL 和 DML,以及配套的各种函数,用户管理及权限管理,数据的备份与恢复。
更多信息可参考下方链接:https://clickhouse.com/docs/zh/sql-reference/
ClickHouse SQL与 ANSI SQL 的兼容性可参考下方链接:https://clickhouse.com/docs/zh/sql-reference/ansi/
2.5 多样化引擎
ClickHouse 和 MySQL 类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类 20 多种引擎。
2.6 高吞吐写入能力
ClickHouse 采用类LSM Tree的结构,数据写入后定期在后台 Compaction。通过类 LSM tree 的结构,ClickHouse 在数据导入时全部是顺序 append 写,写入后数据段不可更改,在后台 compaction 时也是多个段 merge sort 后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在 HDD 上也有着优异的写入性能。
官方公开 benchmark 测试显示能够达到 50MB-200MB/s 的写入吞吐能力,按照每行 100Byte 估算,大约相当于 50W-200W条/s 的写入速度。
2.7 数据分区与线程级并行
ClickHouse 将数据划分为多个 partition,每个 partition 再进一步划分为多个 index granularity(索引粒度),然后通过多个 CPU 核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
所以,ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多 cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务, ClickHouse 并不是强项。
2.8 适合在线查询
在线查询意味着在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中。
2.9 支持近似计算
ClickHouse 提供各种各样在允许牺牲数据精度的情况下对查询进行加速的方法:
- 用于近似计算的各类聚合函数,如:distinct values, medians, quantiles;
- 基于数据的部分样本进行近似查询。这时,仅会从磁盘检索少部分比例的数据;
- 不使用全部的聚合条件,通过随机选择有限个数据聚合条件进行聚合。这在数据聚合条件满足某些分布条件下,在提供相当准确的聚合结果的同时降低了计算资源的使用;
2.10 Adaptive Join Algorithm
ClickHouse 支持自定义 JOIN 多个表,它更倾向于散列连接算法,如果有多个大表,则使用合并-连接算法。
更多信息参考下方链接:https://clickhouse.com/docs/zh/sql-reference/statements/select/join/
2.11 支持数据复制和数据完整性
ClickHouse 使用异步的多主复制技术。当数据被写入任何一个可用副本后,系统会在后台将数据分发给其他副本,以保证系统在不同副本上保持相同的数据。在大多数情况下 ClickHouse 能在故障后自动恢复,在一些少数的复杂情况下需要手动恢复。
更多信息参考下方链接:https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/replication/
2.12 角色的访问控制
ClickHouse 使用 SQL 查询实现用户帐户管理,并允许角色的访问控制,类似于 ANSI SQL 标准和流行的关系数据库管理系统。
更多信息参考下方链接:https://clickhouse.com/docs/zh/operations/access-rights/
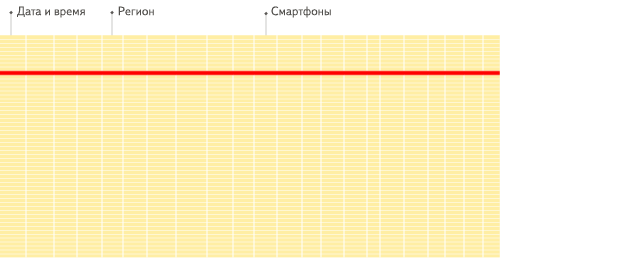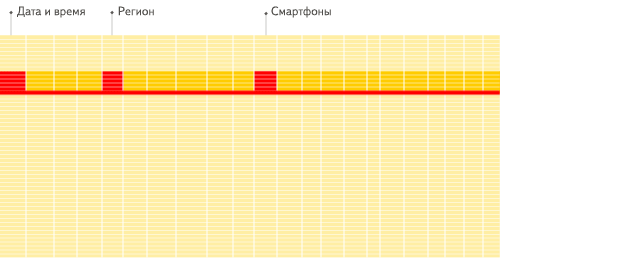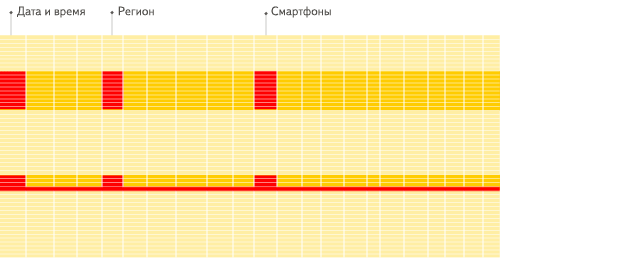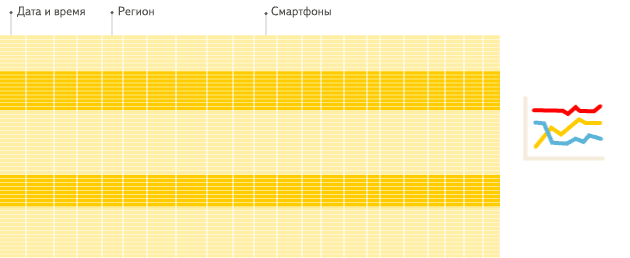
2.13 性能对比
单表查询:
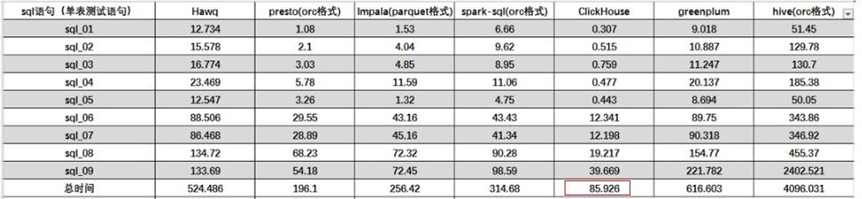
关联查询:
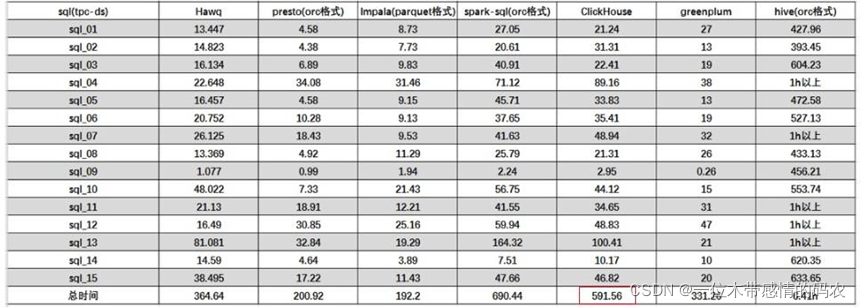
结论:ClickHouse 像很多 OLAP 数据库一样,单表查询速度优于关联查询,而 ClickHouse 的两者差距更为明显。
2.14 ClickHouse的限制
- 没有完整的事务支持;
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合 GDPR;
- 稀疏索引使得 ClickHouse 不适合通过其键检索单行的点查询;
参考文献
【1】https://clickhouse.com/docs/zh/
【2】https://www.bilibili.com/video/BV1Yh411z7os?from=search&seid=4579023877699743987&spm_id_from=333.337.0.0



