
Elastic Stack 日志分析(十四)- Elasticsearch 操作底层流程详解
1. Elasticsearch索引文档流程
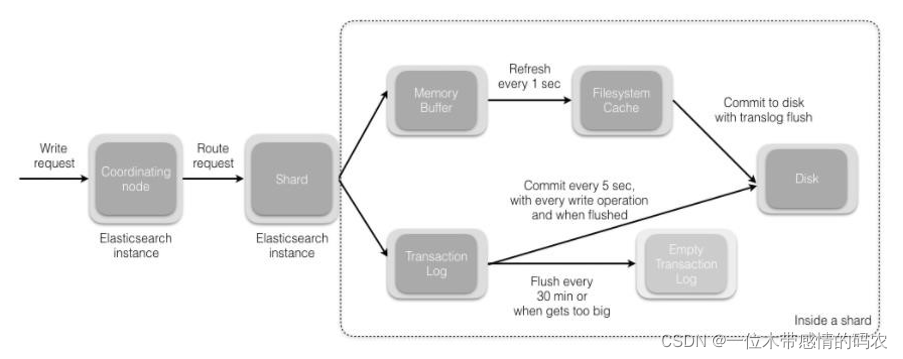
- 协调节点默认使用文档 ID 参与计算(也支持通过 routing),以便为路由提供合适的分片:
shard = hash(document_id) % (num_of_primary_shards); - 当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 Memory Buffer,然后定时(默认是每隔 1 秒)写入到 Filesystem Cache,这个从 Memory Buffer 到 Filesystem Cache 的过程就叫做 refresh;
- 当然在某些情况下,存在 Momery Buffer 和 Filesystem Cache 的数据可能会丢失,ES 是通过 translog 的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中,当 Filesystem cache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
- 在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync 将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog;
- flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512M)时;
2. Elasticsearch更新和删除文档流程
- 删除和更新也都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更;
- 磁盘上的每个段都有一个相应的
.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del文件中被标记为删除的文档将不会被写入新段; - 在新的文档被创建时,Elasticsearch 会为该文档指定一个版本号,当执行更新时,旧版本的文档在
.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉;
3. Elasticsearch搜索流程
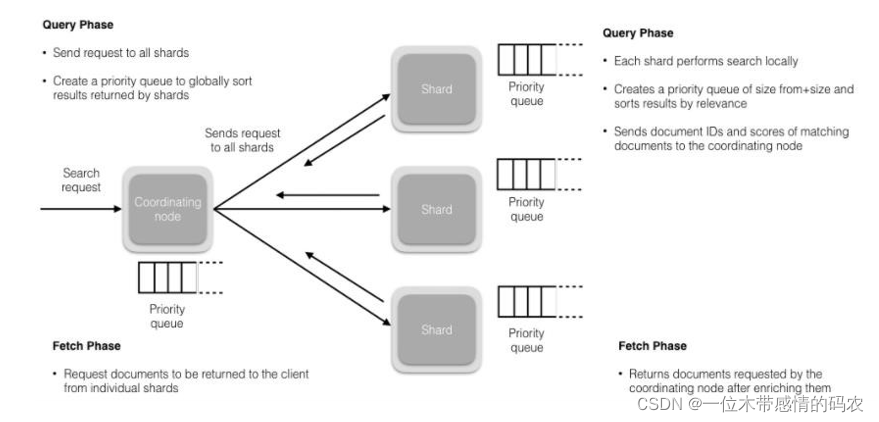
- 搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
- 在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询 Filesystem Cache 的,但是有部分数据还在 Memory Buffer,所以搜索是近实时的;
- 每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表;
- 接下来就是取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端;
- Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document frequency,这个评分更准确,但是性能会变差;
此文章版权归 程序园 所有,如有转载,请注明来自原作者。
相关推荐

评论
ValineDisqus


