Elastic Stack 日志分析(五)- Elasticsearch Windows 集群部署教程
1. 相关概念
1.1 单机 & 集群
单台 Elasticsearch 服务器提供服务,往往都有最大的负载能力,超过这个阈值,服务器性能就会大大降低甚至不可用,所以生产环境中,一般都是运行在指定服务器集群中。
除了负载能力,单点服务器也存在其他问题:
- 单台机器存储容量有限;
- 单服务器容易出现单点故障,无法实现高可用;
- 单服务的并发处理能力有限配置服务器集群时,集群中节点数量没有限制,大于等于 2 个节点就可以看做是集群了。一般出于高性能及高可用方面来考虑集群中节点数量都是 3 个以上。
1.2 集群Cluster
一个集群就是由一个或多个服务器节点组织在一起,共同持有整个的数据,并一起提供索引和搜索功能。一个 Elasticsearch 集群有一个唯一的名字标识,这个名字默认就是elasticsearch。这个名字非常重要,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
1.3 节点Node
集群中包含很多服务器,一个节点就是其中的一个服务器。作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于 Elasticsearch 集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做elasticsearch的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做elasticsearch的集群中。在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何 Elasticsearch 节点,这时启动一个节点,会默认创建并加入一个叫做elasticsearch的集群。
2. Windows集群
2.1 部署集群
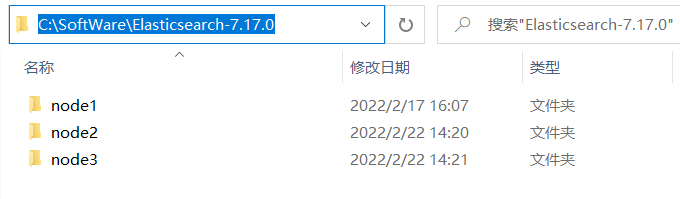
- 创建
Elasticsearch-7.17.0文件夹,在内部复制三个 elasticsearch 服务;
- 修改集群文件目录中每个节点的
config/elasticsearch.yml配置文件;
node1节点:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22#节点 1 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node1
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1001
#tcp 监听端口
transport.tcp.port: 9301
#discovery.seed_hosts: ["localhost:9301", "localhost:9302","localhost:9303"]
#discovery.zen.fd.ping_timeout: 1m
#discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node1", "node2","node3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"node2节点:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22#节点 2 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node2
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1002
#tcp 监听端口
transport.tcp.port: 9302
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node1", "node2","node3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"node3节点:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23#节点 3 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node3
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1003
#tcp 监听端口
transport.tcp.port: 9303
#候选主节点的地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9301", "localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node1", "node2","node3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
2.2 启动集群
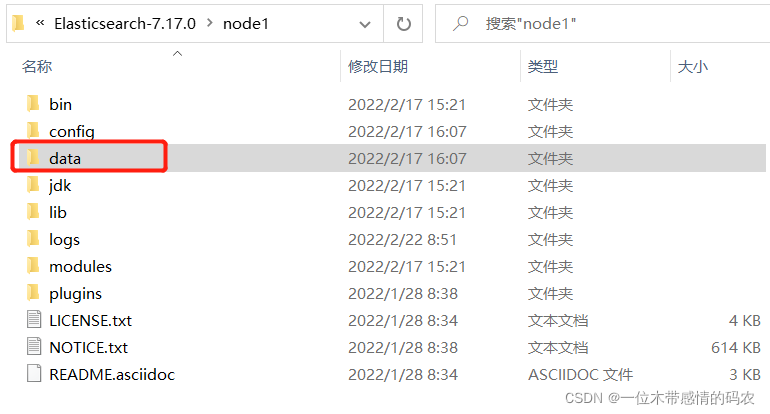
- 启动前先删除每个节点中的
data目录中所有内容(如果存在);
- 分别双击执行
bin/elasticsearch.bat,启动节点服务器,启动后,会自动加入指定名称的集群;
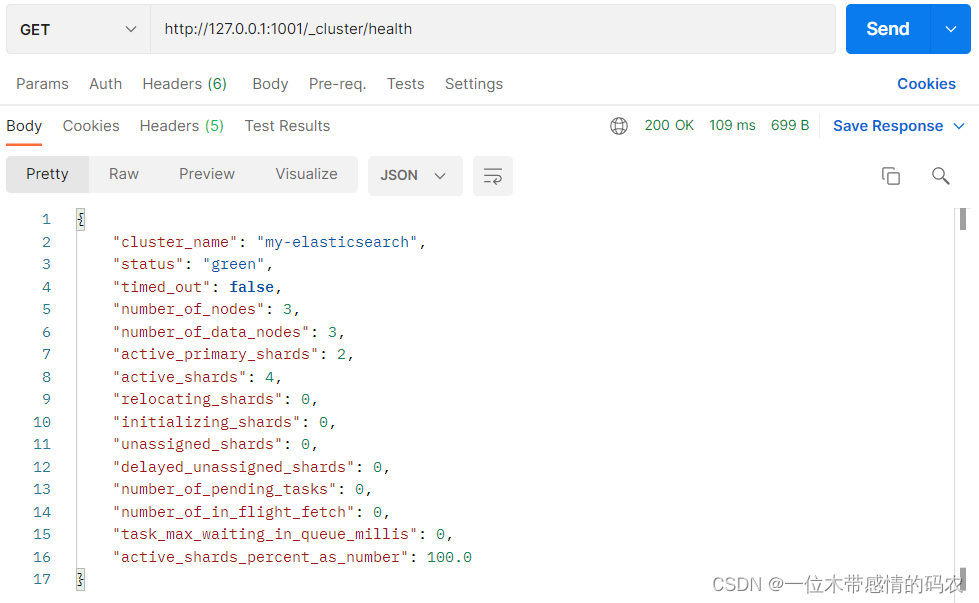
2.3 测试集群
查看集群状态(用 Postman 进行测试,没安装的可以看我上一篇博客安装使用):
- node1节点
- node2节点
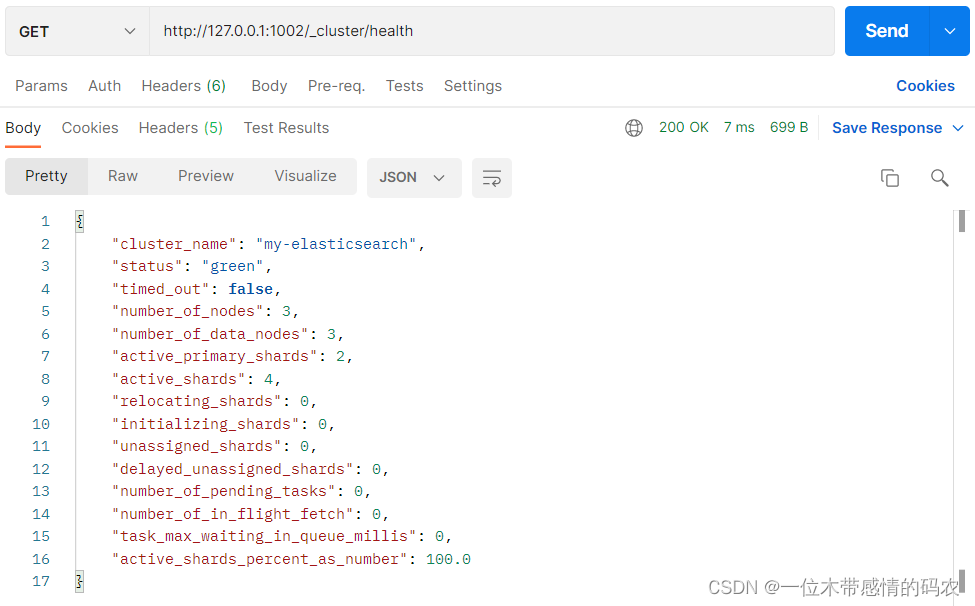
- node3节点
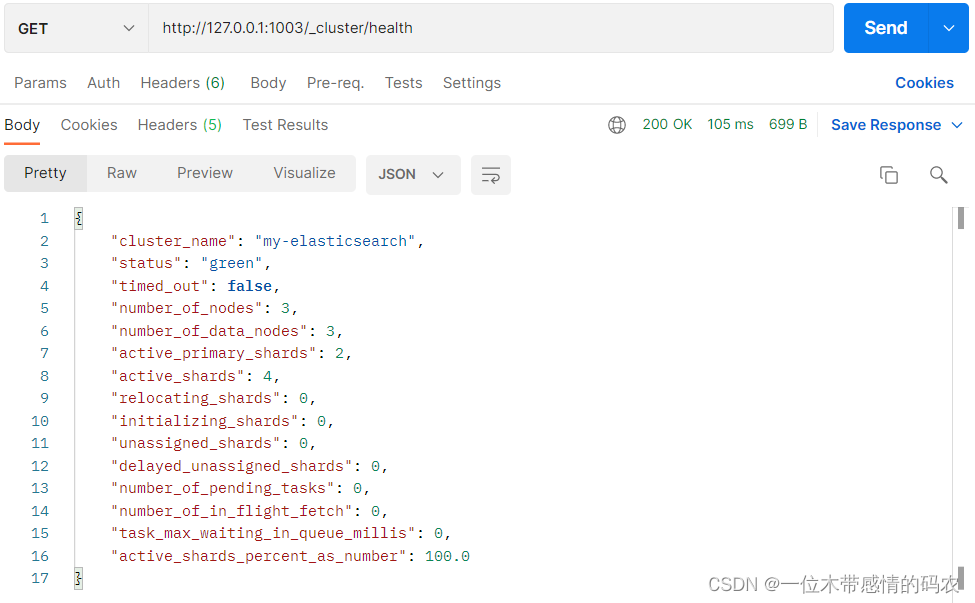
status字段表示当前集群在总体上是否工作正常。它的三种颜色含义如下:
- green
- 所有的主分片和副本分片都正常运行;
- yellow
- 所有的主分片都正常运行,但不是所有的副本分片都正常运行;
- red
- 有主分片没能正常运行;
向集群中的node1节点增加索引:
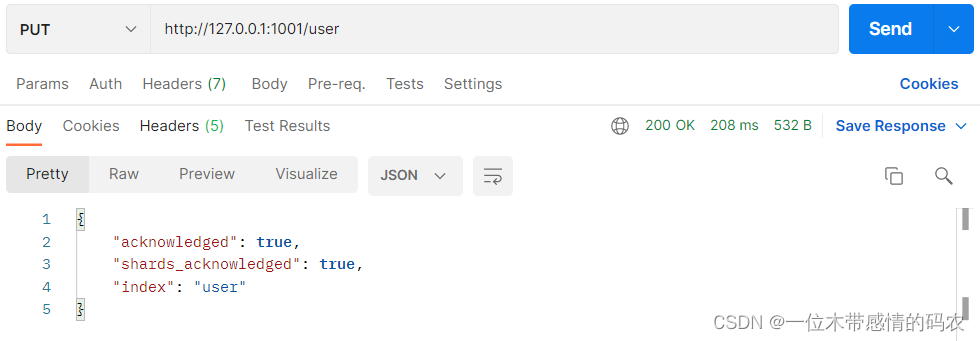
向集群中的node2节点查询索引:
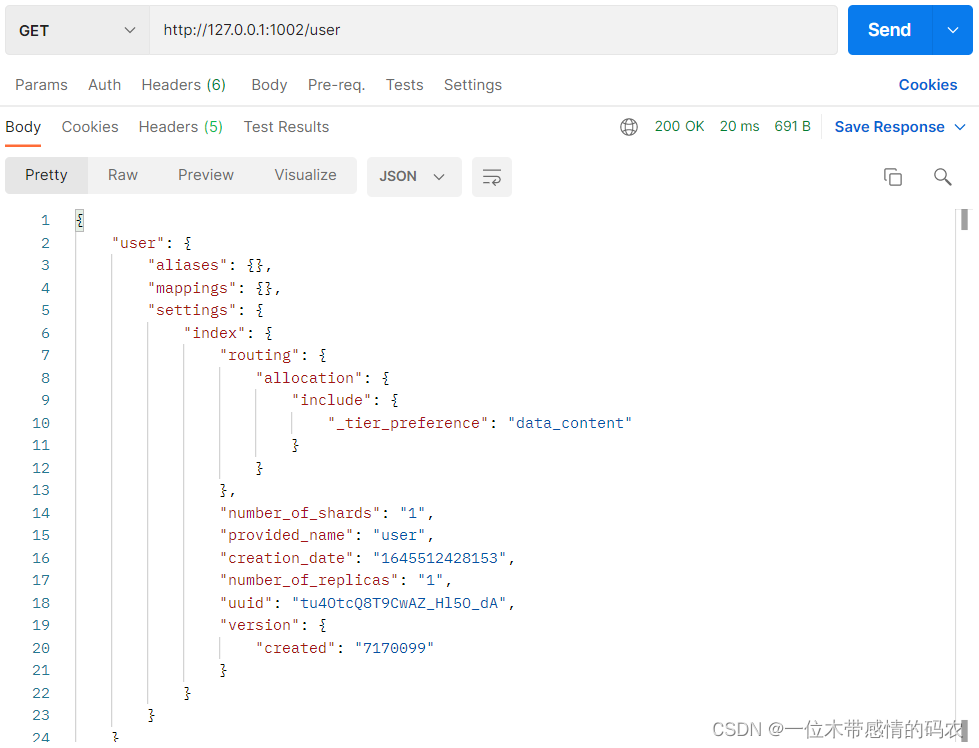
2.4 Elasticsearch-head插件安装
插件安装包链接:https://pan.baidu.com/s/14c8YrfCPDelBTLkWwqSrXA,提取码:6666。
在 Chrome 浏览器点击右上角的三个点 ===>更多工具===>扩展程序,出现下面的画面:
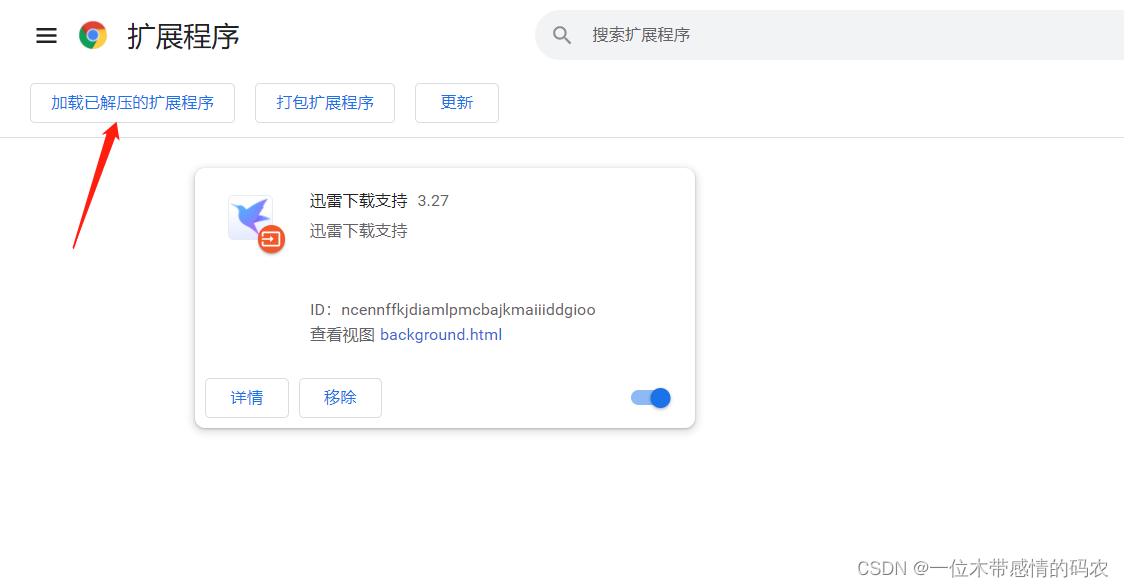
选择刚刚下载的安装包即可:
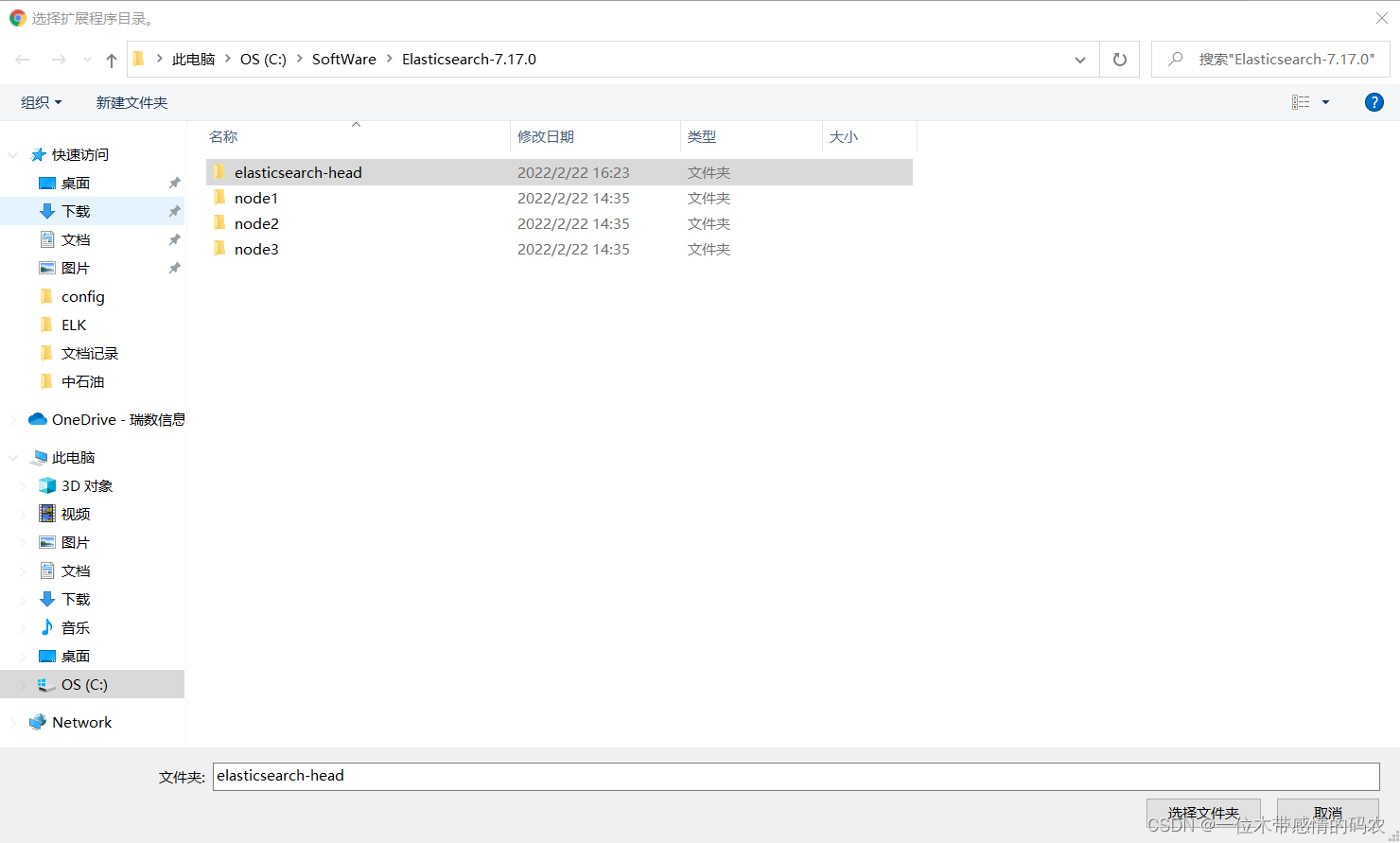
直接点击即可使用: