
Hadoop 生态圈(四十二)- YARN 核心源码分析
前言
部分内容摘自尚硅谷、黑马等等培训资料
1. YARN应用运行流程
首先回顾,提交 MapReduce 程序到 YARN 集群运行机制,如下图所示:
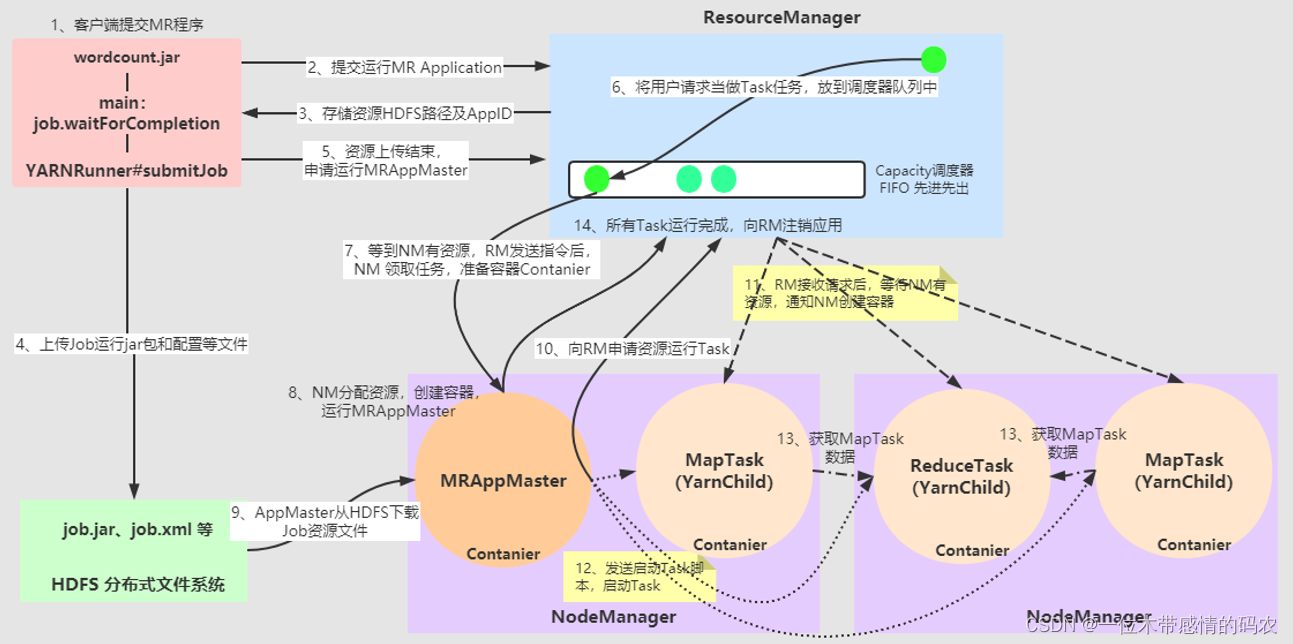
执行流程步骤如下:
- 第 1 步: MapReduce 程序提交到客户端所在的节点,使用 yarn jar 命令提交运行;
1 | yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output |
- 第 2 步:Client 客户端向 ResourceManager 申请运行一个 Application;
- 第 3 步:当 RM 接收到请求后,生成应用 Application 资源提交路径
hdfs://…./.staging以及 application_id,并返回客户端 Client;
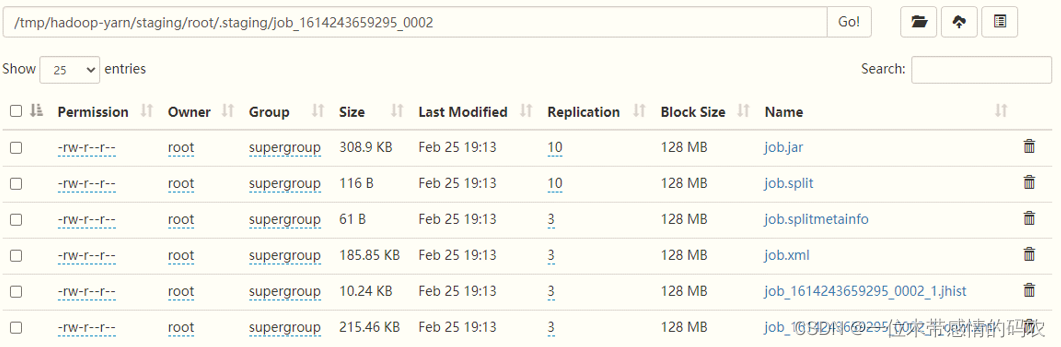
- 第 4 步:Client 客户端提交 job 运行所需资源到资源提交路径

如下图所示,运行 MapReduce 时,上传 Job 资源至 HDFS 目录
- 第 5 步:当 Client 客户端资源提交完毕,申请运行 mrAppMaster;
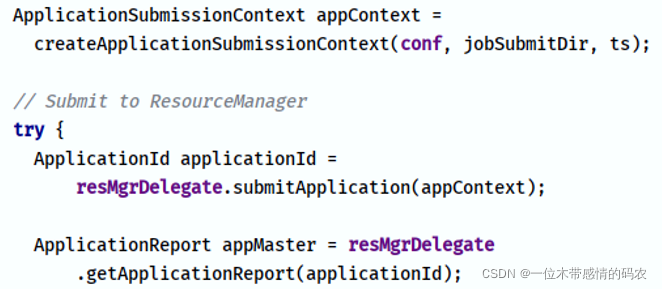
- 第 6 步:当 ResourceManager 接收请求以后,将用户的请求初始化成一个 Task,将其放到队列中(Apache Hadoop YARN 默认使用 CapacityScheduler 容器调度器,将 Task 任务放入某个队列 Queue 中,等待后续执行);

- 第 7 步:当 NodeManager 中有资源时,ResourceManager 向其发送指令,此时 NodeManager 领取到 Task 任务,准备启动容器运行 AppMaster;
- 第 8 步:NodeManager 创建容器 Contanier,容器中包含相关资源(比如 CPU、内存 Memory等),在其中运行 MRAppMaster;

- 第 9 步:MRAppMaster 启动以后,依据资源提交路径,下载 job 资源到本地(也就是 MRAppMaster 所运行 NodeManager 节点临时目录中);
- 第 10 步:MRAppMaster 获取 Job 运行资源信息以后,计算此 MapReduce 任务运行所需要的 MapTask 任务个数,再向 ResourceManager 申请资源,创建 MapTask 容器 Contanier;
- 第 11 步:ResourceManager 接收到 MRAppMaster 请求后,将这些 Task 任务同样放到队列 Queue 中,当 NodeManager 中有资源时,ResourceManager 依然向 NodeManager 发送指令,领取到 Task 任务,创建容器 Contanier;
- 第 12 步:当 NodeManager 中容器 Contanier 创建完成以后,MRAppMaster 将运行 MapTask 任务的程序脚本发送给 Contanier 容器,最后在容器 Contanier 中启动 YarnChild 进程运行 MapTask 任务,处理数据;
- 第 13 步:当 MapTask 任务运行完成以后,MRAppMaster 再向 ResourceManager 申请资源,在 NodeManager 中创建 ReduceTask 任务运行的容器,启动 YarnChild 进程运行 ReduceTask 任务,拉取 MapTask 处理数据,进行聚合操作;
- 第14步、当 MapReduce 应用程序运行完成以后,向 ResourceManager 注销自己,释放资源,至此整个应用运行完成。
2. 第一阶段:Client提交应用至YARN
以入门程序:WordCount 作业为例,执行程序 main 方法,核心代码:
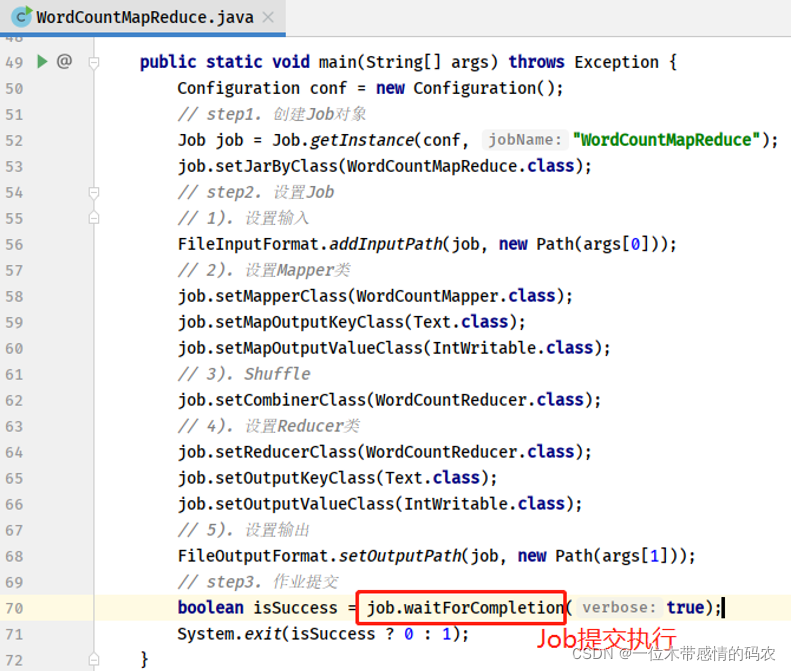
当运行程序,执行到 MAIN 方法中如下代码时:

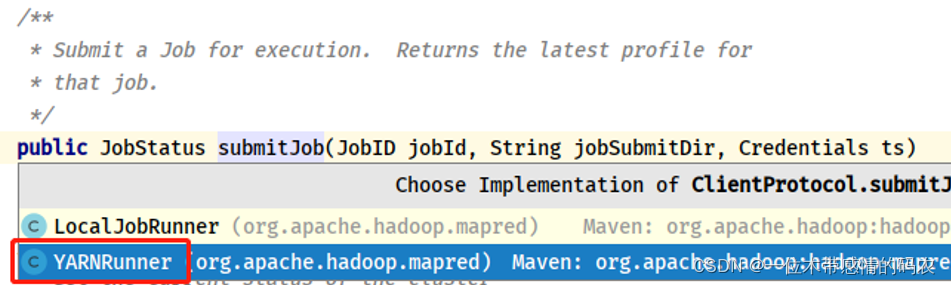
如果提交运行 YARN 集群,则最终调用YARNRunner#submitJob方法:

向 YARN 提交 Job 时,主要流程示意图如下所示:
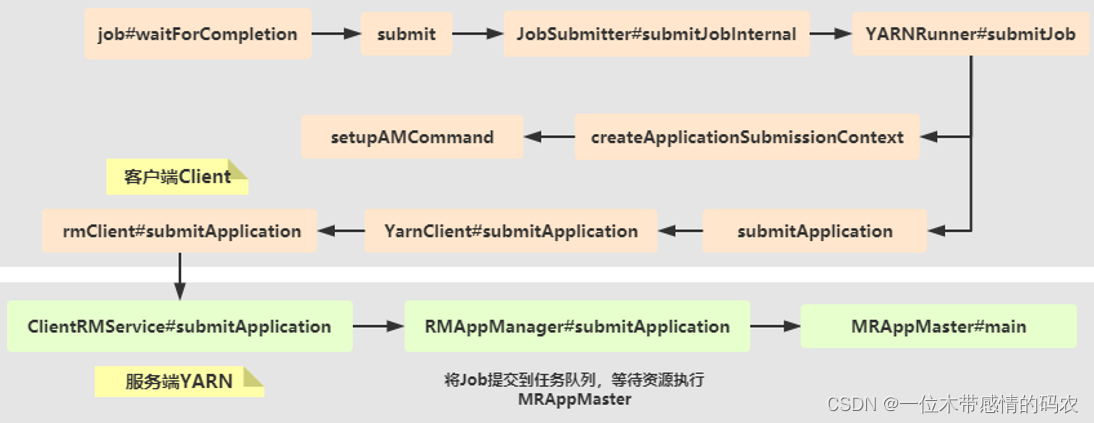
2.1 第一步:JobSubmitter(Job 提交)
MapReduce 程序最后执行job.waitForCompletion方法时,表示应用提交执行等待完成,提交应用时,方法调用链如下所示:
waitForCompletion -> submit -> submitter.submitJobInternal -> submitJob
- Job#waitForCompletion 方法
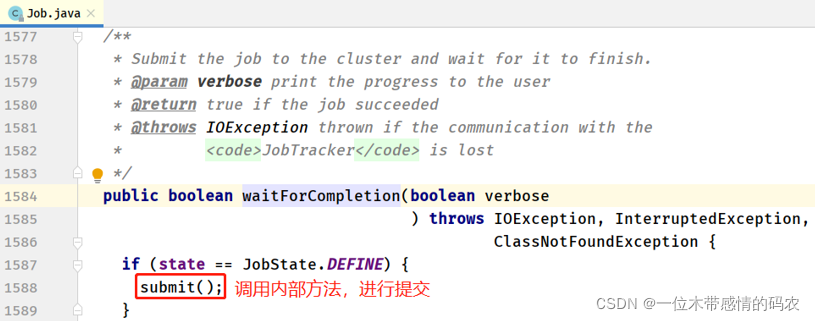
- Job#submit 方法
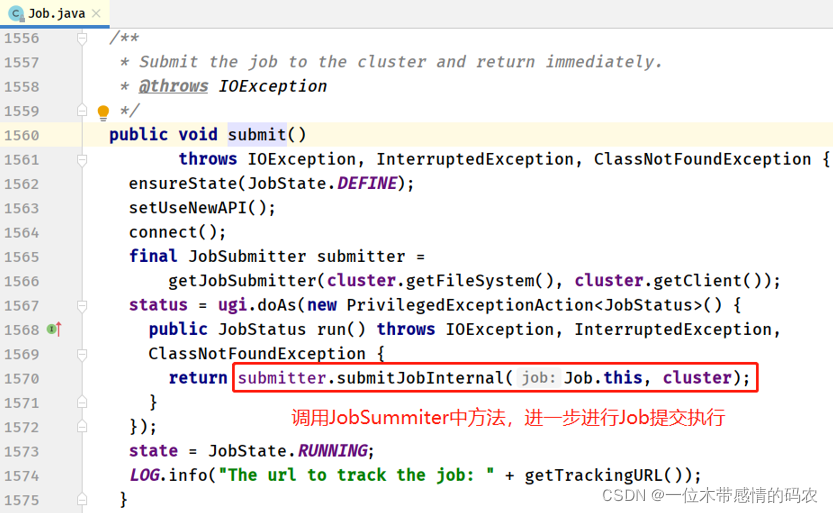
- JobSubmmiter#submitJobInternal 方法
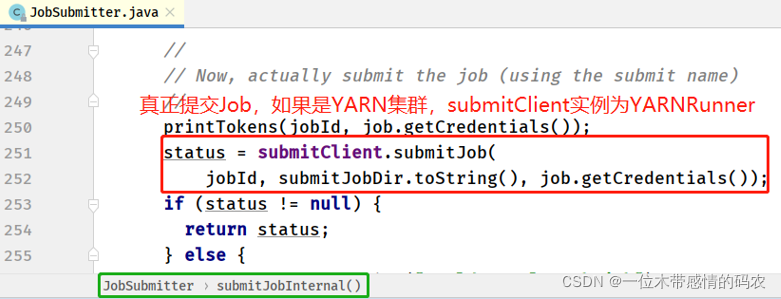
2.2 第二步:createApplicationSubmissionContext(创建应用上下文)
submitClient为ClientProtocol实例对象,有 2 个实现子类:本地模式运行和 YARN 集群运行:
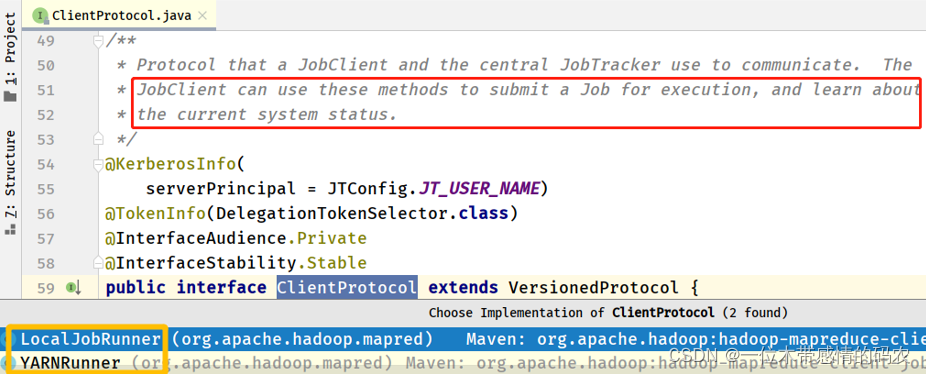
- submitClient#submitJob 调用,选择YARN集群运行
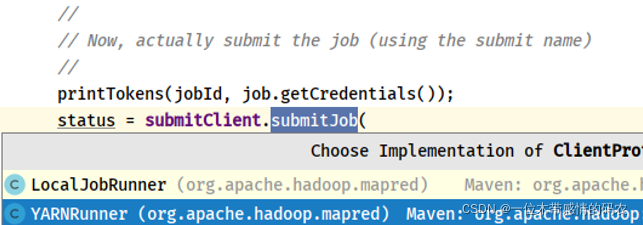
- YARNRunner#submitJob 方法
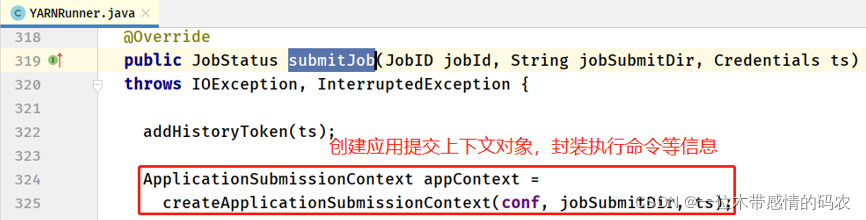
- YARNRunner#createApplicationSubmissionContext 方法
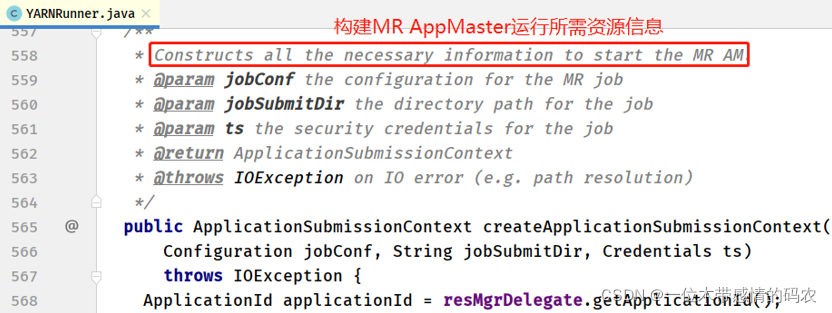
构建 MR AppMaster 运行环境,主要包括:
- 设置本地资源:Job 配置文件、Job Jar 包及提交运行工作目录等

- 设置容器启动上下文:启动 AppMaster 进程 java 命令和运行日志存储等

- 应用提交上下文设置:比如设置应用 ID 和运行队列 Queueu 等

2.3 第三步:RMAppManager#submitApplication(提交应用)
在YARNRunner#submitJob方法中,应用提交上下文构建完成后,进行应用提交。
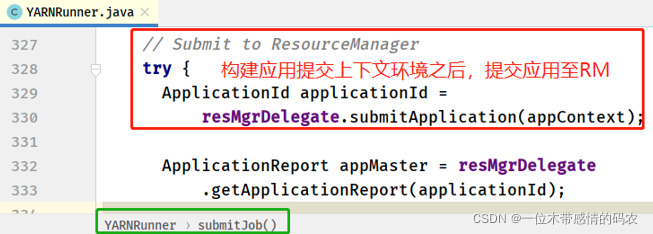
- ResourceMgrDelegate#submitApplication 方法
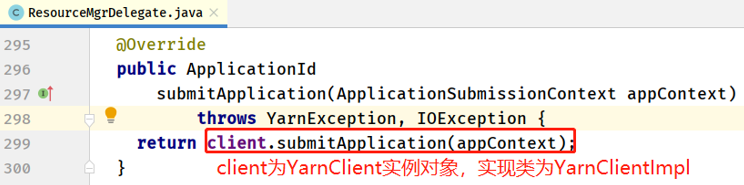
- YARNClientImpl#submitApplication 方法
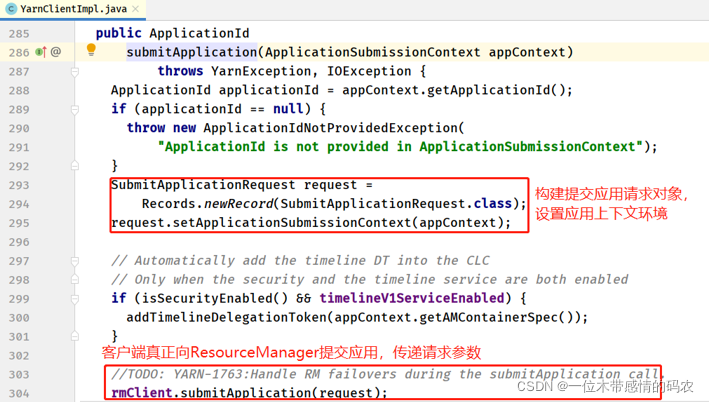
rmClient是一个ApplicationClientProtocol类对象,这是一个 RPC 的接口协议,对应的实现类ApplicationClientProtocolPBClientImpl。 - 客户端 ApplicationClientProtocolPBClientImpl#submitApplication 方法
此时ApplicationClientProtocolPBServiceImpl类属于客户端 Client 实现类,所在包为:org.apache.hadoop.yarn.api.impl.pb.client。
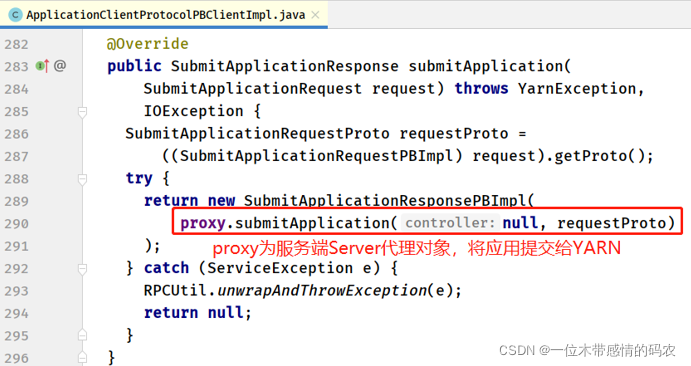
RPC Client端proxy.submitApplication()对应的 RPC Server 端的方法数为:ApplicationClientProtocolPBServiceImpl#submitApplication(),是对称的关系,都实现了ApplicationClientProtocalPB接口。 - 服务端 ApplicationClientProtocolPBServiceImpl#submitApplication 方法
此时ApplicationClientProtocolPBServiceImpl类属于服务端 Service 实现类,所在包为:org.apache.hadoop.yarn.api.impl.pb.service。
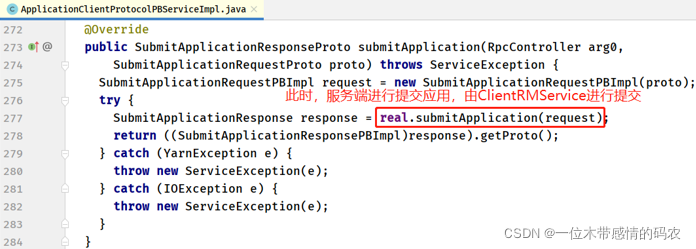
ApplicationClientProtocolPBServiceImpl类对象由ClientRMService构建,属于 RM 端的服务类,专门用于服务 Client,包括 Client 的作业提交,作业查询等服务。 - ClientRMService#submitApplication 方法
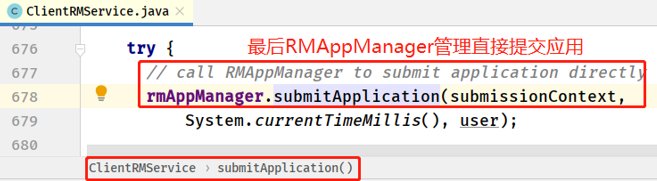
由ClientRMService.submitApplication()直接把作业交给RMAppManager类的对象rmAppManager进行提交,这也是作业最终上岸了,接下来就是 RM 的事情。
2.4 作业提交调用层次
客户端 Client 进行作业提交时,分为 Client 端和 Service 服务端 2 个层次:
- 客户端层次流程图
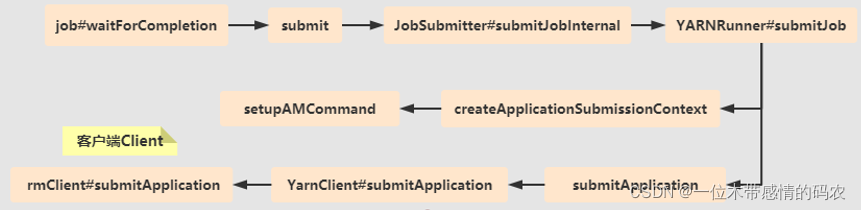
- 服务端层次流程图

3. 第二阶段:YARN启动AppMaster
MapReduce 作业提交已经到达 ResourceManager 端,并且交给 RMAppManager 进行继续运转,将此应用当做任务提交到队列 Queue 中,开始执行MRAppMaster任务,流程图如下。
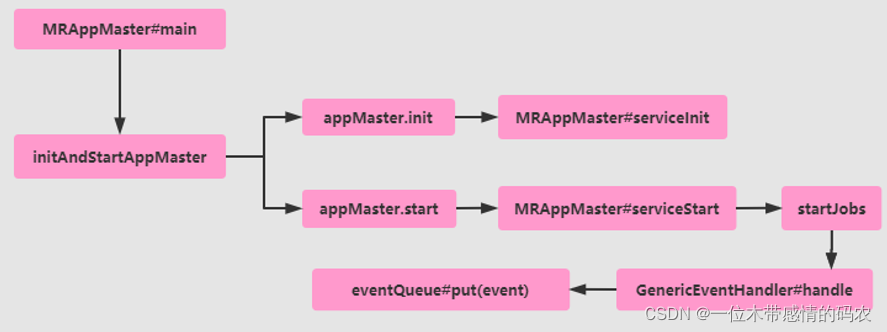
从 MRAppMaster 类中 main 查看,启动 MRAppMaster 进程流程步骤。
- MRAppMaster#main 方法
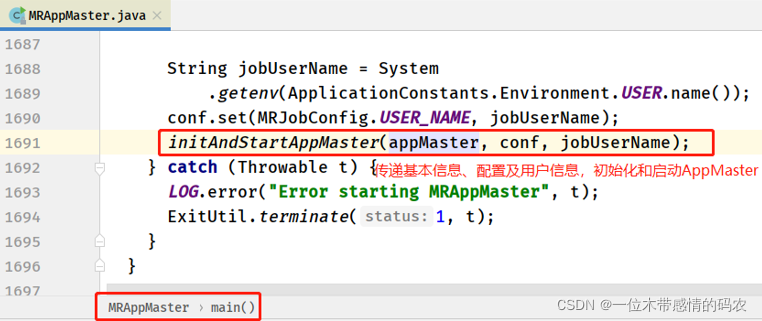
- MRAppMaster#initAndStartAppMaster 方法
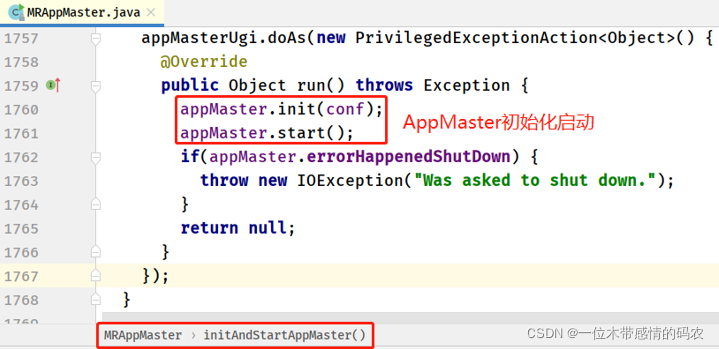
3.1 第一步:AppMaster 初始化
ResourceManager 在启动 AppMaster 之前,先对 AppMaster 服务进行初始化操作。
- 初始化 AbstractServie#init 方法
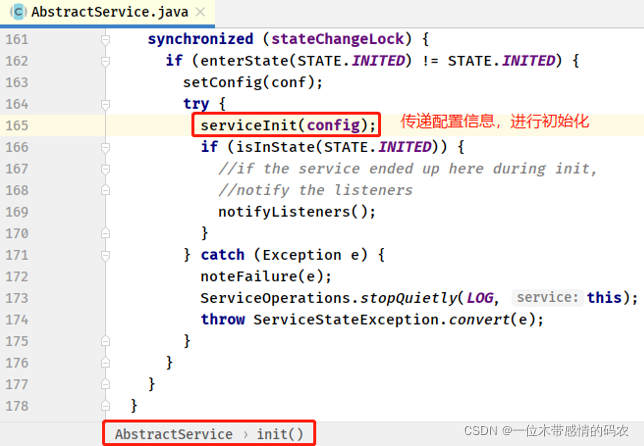
- 启动 MRAppMaster#serviceInit 方法
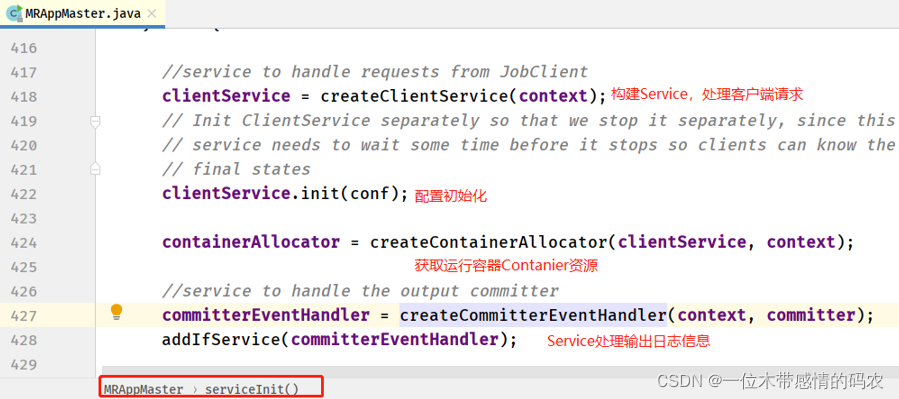
当 MRAppMaster 初始化完成以后,开始启动 MRAppMaster 进程服务。
3.2 第二步:AppMaster启动
- 启动 MRAppMaster#start 方法
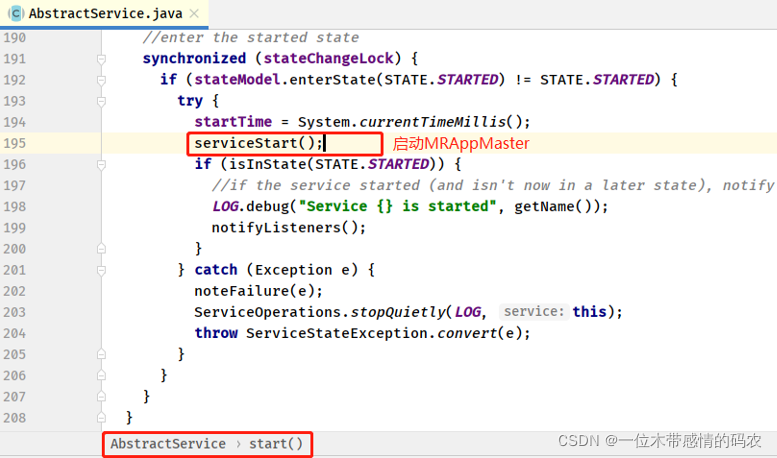
- 启动 MRAppMaster#serviceStart 方法
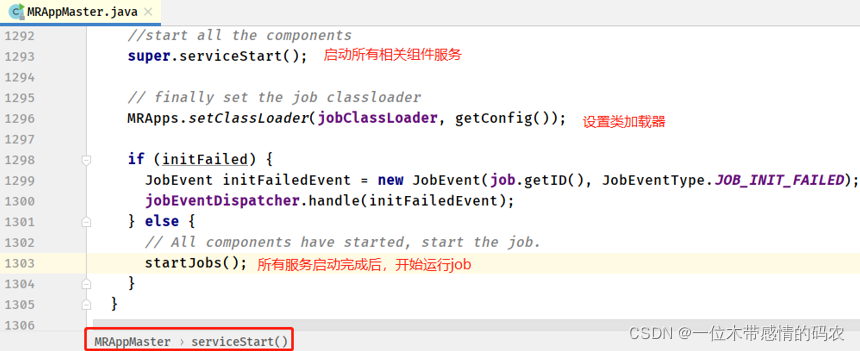
- MRAppMaster#startJobs 方法
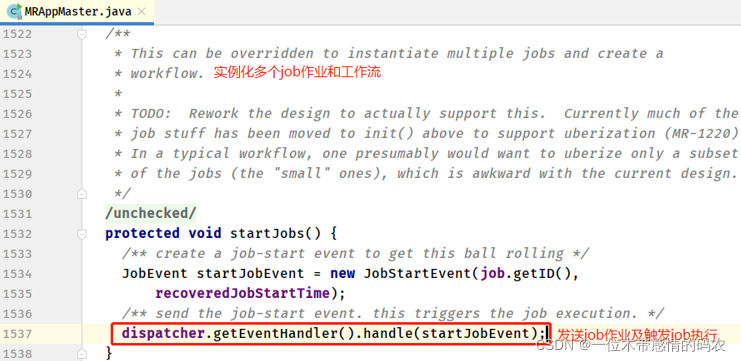
从分发器Dispatcher(实例为AysncDispatcher异步分发器) 中获取事件处理器 EventHandler,处理器的实例对象GenericEventHandler(通用事件处理器),调用handle方法启动 Job 作业执行。 - GenericEventHandler#handle 方法
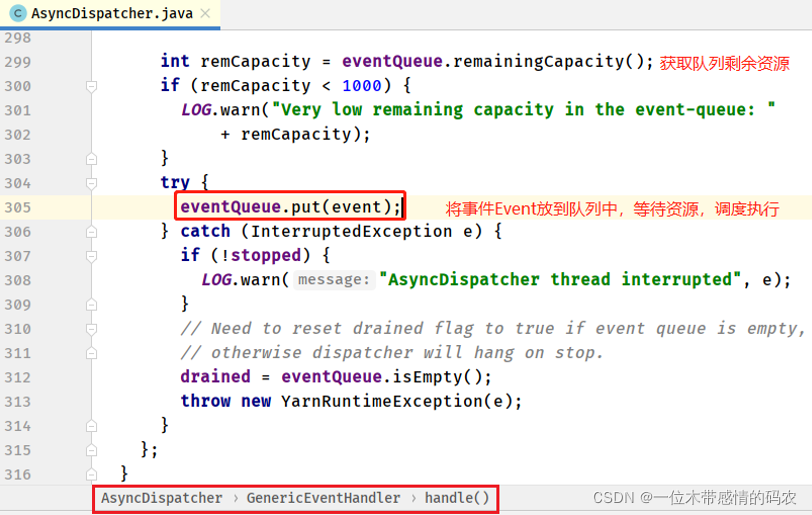
最后将 Job 作业存放到队列 Queue 中,对于 Apache Hadoop YARN 来说,默认使用 Capacity Scheduler 容量调度器的default队列中,等待调度执行。
4. 第三阶段:调度执行应用进程
任何一个应用提交运行至 YARN 集群,首先为应用启动 AppMaster,当启动完成以后,为每个应用启动应用进程,调度任务 Task 执行,其中不同应用对应的应用进程不一样。

针对 MapReduce 应用提交运行 YARN 上来说,当 MRAppMaster 启动以后,计算整个 Job 的 MapTask 和 ReduceTask 数量,然后向 ResourceManager 申请资源,运行 Task 任务。无论运行 MapTask 还是 ReduceTask,都是 YarnChild 中执行 Task,运行流程图:
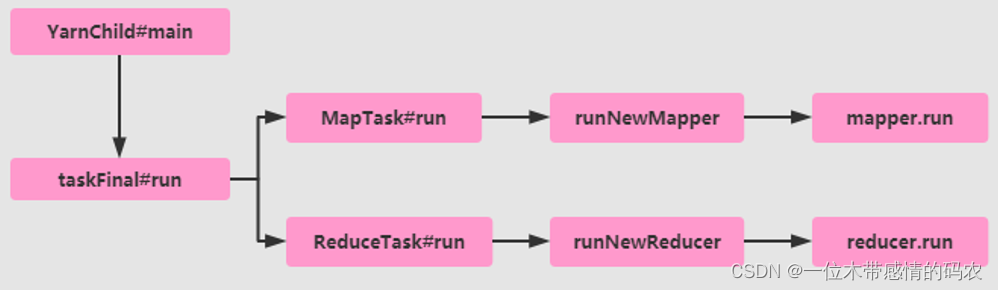
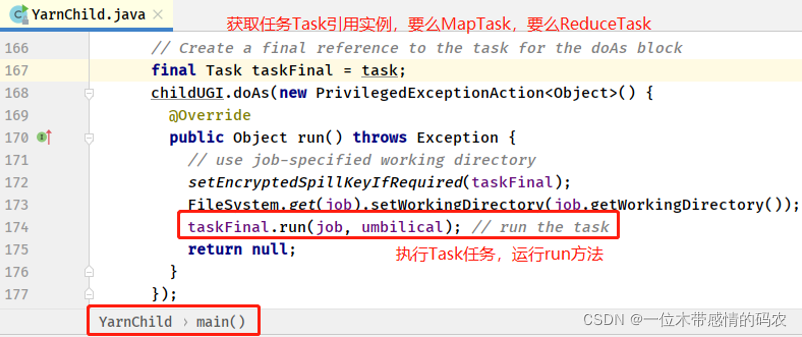
查看 YarnChild 类中 main 方法,核心源码:
Task 类 2 个实现子类:MapTask 和 ReduceTask,查看其中 run 方法,如何执行任务。
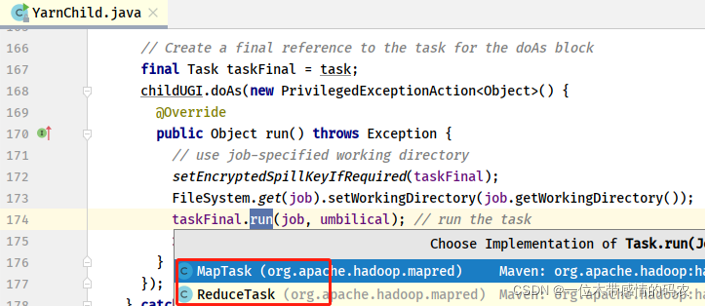
4.1 第一步:MapTask任务执行
查看 MapTask 任务中 run 方法,主要判断是否是 MapReduce New API 编写程序,如果是的话直接调用:runNewMapper方法,运行 MapTask 任务。
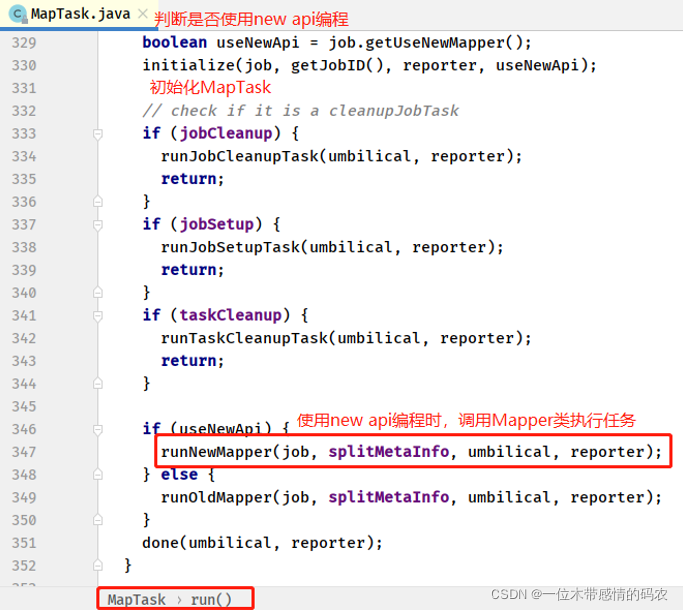
- MapTask#runNewMapper 方法
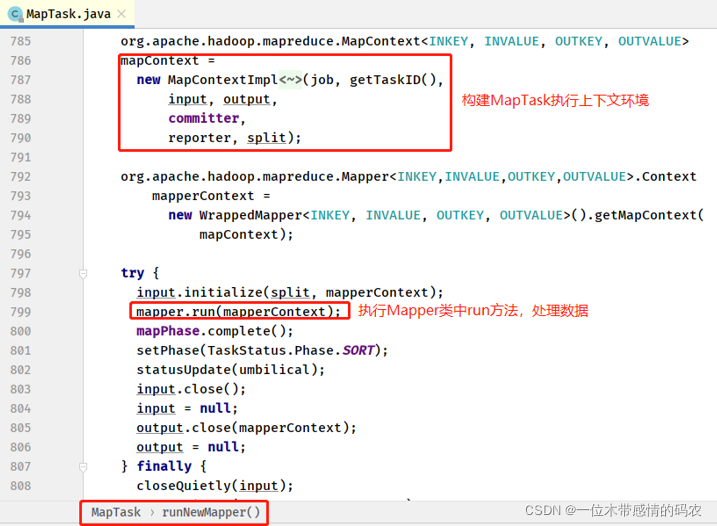
- Mapper#run 方法
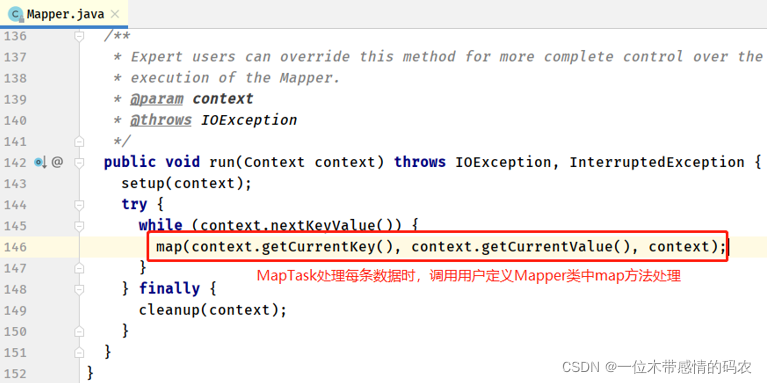
4.2 第二步:ReduceTask任务执行
在 MapReduce 计算引擎中,先运行 MapTask 处理每个 Split 分片数据,当完成以后告知 MRAppMaster 主节点,接着通知所有 ReduceTask 到 MapTask 输出目录拉取所属自己文件数据。
接下来,查看 ReduceTask 类中 run 方法,核心执行流程。
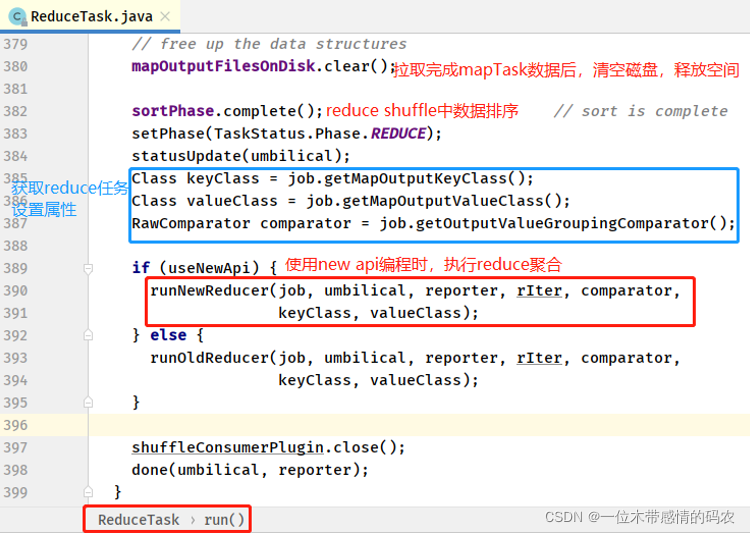
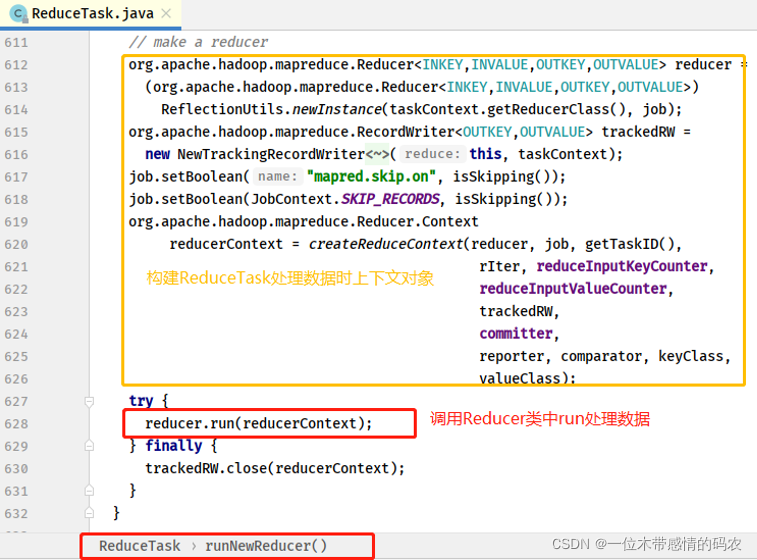
- ReduceTask#runNewReducer 方法
- Reducer#run 方法
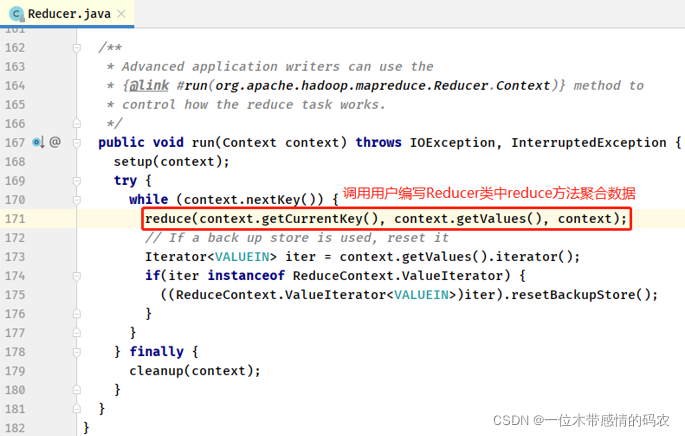
当 ReduceTask 运行完成后,将数据输出到外部存储引擎(比如 HDFS 文件系统),告知 MRAppMaster。MRAppMaster 等到所有 ReduceTask 任务运行完成后,向 ResourceManager 发送信息,要求 ResourceManager 注销自己,释放资源,以便其他应用运行使用,至此一个 MapReduce 应用程序运行 YARN 集群完成。



