
Hadoop 生态圈(三十八)- YARN Fair Scheduler 公平调度器深入研究
前言
部分内容摘自尚硅谷、黑马等等培训资料
1. 什么是Fair Scheduler
FairScheduler 是 Hadoop 可插拔的调度程序,提供了 YARN 应用程序公平地共享大型集群中资源的另一种方式。FairScheduler是一个将资源公平的分配给应用程序的方法,使所有应用在平均情况下随着时间的流逝可以获得相等的资源份额。
Fair Scheduler 设计目标是为所有的应用分配公平的资源(对公平的定义通过参数来设置)。公平调度是一个分配资源给所有application的方法,平均来看,是随着时间的进展平等分享资源的。
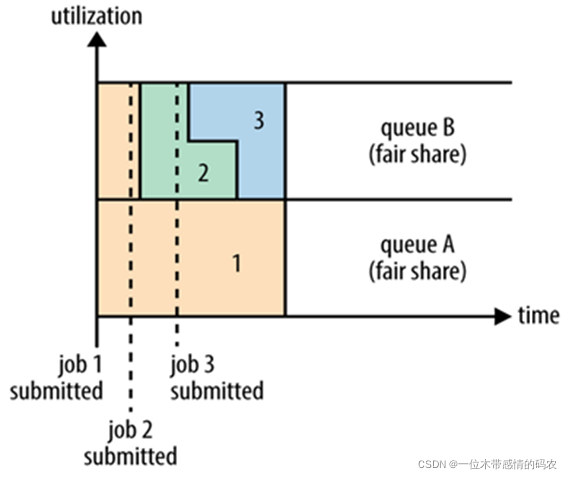
公平调度可以在多个队列间工作。如上图所示,假设有两个用户 A 和 B,分别拥有一个队列:
- 当 A 启动一个 job 而 B 没有任务时,A 会获得
全部集群资源; - 当 B 启动一个 job 后,A 的 job 会继续运行,不过一会儿之后两个任务会
各自获得一半的集群资源。 - 如果此时 B 再启动第二个 job 并且其它 job 还在运行,则它将会和 B 的第一个 job 共享 B 这个队列的资源,也就是 B 的两个 job 会各自使用四分之一的集群资源,而 A 的 job 仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。
FairScheduler 将应用组织到队列中,并在这些队列之间公平地共享资源。默认情况下,所有用户共享一个名为default的队列。如果应用明确在容器资源请求中指定了队列,则该请求将提交到指定的队列。可以通过配置,根据请求中包含的用户名或组分配队列。在每个队列中,使用调度策略在运行的应用程序之间共享资源。默认设置是基于内存的公平共享,但是也可以配置具有优势资源公平性的 FIFO 和多资源。
- 分层队列: 队列可以按层次结构排列以划分资源,并可以配置权重以按特定比例共享集群。
- 基于用户或组的队列映射: 可以根据提交任务的用户名或组来分配队列。如果任务指定了一个队列,则在该队列中提交任务。
- 资源抢占: 根据应用的配置,抢占和分配资源可以是友好的或是强制的。默认不启用资源抢占。
- 保证最小配额: 可以设置队列最小资源,允许将保证的最小份额分配给队列,保证用户可以启动任务。当队列不能满足最小资源时,可以从其它队列抢占。当队列资源使用不完时,可以给其它队列使用。这对于确保某些用户、组或生产应用始终获得足够的资源。
- 允许资源共享: 即当一个应用运行时,如果其它队列没有任务执行,则可以使用其它队列,当其它队列有应用需要资源时再将占用的队列释放出来。所有的应用都从资源队列中分配资源。
- 默认不限制每个队列和用户可以同时运行应用的数量。 可以配置来限制队列和用户并行执行的应用数量。限制并行执行应用数量不会导致任务提交失败,超出的应用会在队列中等待。
2. 启用Fair Scheduler
要使用 Fair Scheduler,首先在yarn-site.xml配置文件进配置:
1 | <property> |
3. 资源配置文件
Fair Scheduler的配置文件,位于类路径下,默认文件名fair-scheduler.xml,通过属性指定:
1 | <!-- Path to allocation file, the file is searched for on the classpath --> |
若没有fair-scheduler.xml这个配置文件,Fair Scheduler 采用的分配策略:调度器会在用户提交第一个应用时为其自动创建一个队列,队列的名字就是用户名,所有的应用都会被分配到相应的用户队列中。
4. Fair Scheduler配置
定制 Fair Scheduler 涉及到 2 个文件。首先,scheduler有关的选项可以在yarn-site.xml中配置。此外,多数情况,用户需要创建一个 “allocation” 文件来列举存在的 queues 和它们相应的 weights和capacities。这个“allocation”文件每隔10秒钟加载一次,更新的配置可以更快的生效。
4.1 调度器级别的参数
在HADOOP_CONF/yarn-site.xml中,主要用于配置调度器级别的参数。
- 属性一: 是否将与 allocation 有关的 username 作为默认的 queue name,当 queue name 没有指定的时候。如果设置成 false(且没有指定 queue name)或者没有设定,所有的 jobs 将共享 “default” queue。

- 属性二: 是否使用 “preemption”(优先权,抢占),默认为 fasle

- 属性三: 启动抢占后的资源利用率阈值。利用率是计算所有资源中容量使用的最大比率。 默认值是 0.8f。

- 属性四: 在一个队列内部分配资源时,默认情况下,采用公平轮询的方法将资源分配各个应用程序,而该参数则提供了另外一种资源分配方式:按照应用程序资源需求数目分配资源,即需求资源数量越多,分配的资源越多。默认情况下,该参数值为 false。

- 属性五: 是在允许在一个心跳中,发送多个container分配信息

- 属性六: 如果 assignmultuple 为 true,在一次心跳中,最多发送分配container的个数。默认为 -1,无限制。

- 属性七: 一个 float 值,在 0~1 之间,表示在等待获取满足 node-local 条件的 containers 时,最多放弃不满足 node-local 的 container 的机会次数,放弃的 nodes 个数为集群的大小的比例。默认值为 -1.0 表示不放弃任何调度的机会。

- 属性八: 当应用程序请求某个机架上资源时,它可以接受的可跳过的最大资源调度机会。

- 属性九: 是否根据 application 的大小(job 的个数)作为权重。默认为 false,如果为 true,那么复杂的 application 将获取更多的资源。

- 属性十: 如果设置为 true,application提交时可以创建新的队列,要么是 application 指定了队列,或者是按照 user-as-default-queue 放置到相应队列。如果设置为 false,任何时间一个 app 要放置到一个未在分配文件中指定的队列,都将被放置到 “default” 队列。默认是 true。如果一个队列放置策略已经在分配文件中指定,本属性将会被忽略。

- 属性十一: 默认值 500ms,锁住调度器重新进行计算作业所需资源的间隔

4.2 分配文件队列的参数
- 可以在分配(allocation)文件中配置每一个队列,并且可以像 Capacity Scheduler 一样分层次配置队列,分配文件每10秒重载一次,因此允许在运行时进行修改。

- 队列的层次
通过嵌套<queue>元素实现的。所有的队列都是<root>队列的孩子,即使没有配到<root>元素里。在这个配置中,把dev队列有分成了eng和science两个队列。
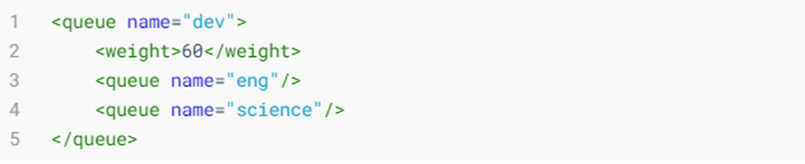
Fair Scheduler中的队列有一个权重属性(权重就是对公平的定义),并把这个属性作为公平调度的依据。在每个资源池的配置项中,有个 weight 属性(默认为 1),标记了资源池的权重,当资源池中有任务等待,并且集群中有空闲资源时候,每个资源池可以根据权重获得不同比例的集群空闲资源。- 例子中,当调度器分配集群
40:60资源给prod和dev时便视作公平,eng和science队列没有定义权重,则会被平均分配。 - 权重并不是百分比,把上面的 40 和 60 分别替换成 2 和 3,效果也是一样的。注意,对于在没有配置文件时,
按用户自动创建的队列,它们仍有权重并且权重值为1。 - 比如,资源池 businessA 和 businessB 的权重分别为 2 和 1,这两个资源池中的资源都已经跑满了,并且还有任务在排队,此时集群中有 30 个 Container 的空闲资源,那么,businessA 将会额外获得 20 个 Container 的资源,businessB 会额外获得 10 个 Container 的资源。
- 例子中,当调度器分配集群
- 队列的默认调度策略(整体)
- 通过顶级元素
<defaultQueueSchedulingPolicy>进行配置,如果没有配置,默认采用公平调度。每个队列内部仍可以有不同的调度策略。

- 针对 Apache Hadoop 来说,Fair Scheduler 默认的调度策略(scheduling policy)是基于内存
- CDH 版本的 YARN 默认采用的调度策略是
Fair Scheduler的DRF策略,即基于 vcore 和内存的策略,而不是只基于内存的调度策略。

- 通过顶级元素
- 每个队列的调度策略
- 尽管是 Fair Scheduler,其仍支持在队列级别进行 FIFO Schedule。每个队列的调度策略可以被其内部的
<schedulingPolicy>元素覆盖。

- 例子中,
prod队列就被指定采用 FIFO 进行调度,所以,对于提交到prod队列的任务就可以按照 FIFO 规则顺序的执行了。需要注意,prod和dev之间的调度仍然是公平调度,同样eng和science也是公平调度。
- 尽管是 Fair Scheduler,其仍支持在队列级别进行 FIFO Schedule。每个队列的调度策略可以被其内部的
- 队列的设置
Fair Scheduler 采用了一套基于规则的系统来确定应用应该放到哪个队列。- 例子中,
<queuePlacementPolicy>元素定义了一个规则列表,其中的每个规则会被逐个尝试直到匹配成功。

- 所有Rule接受
create参数,用于表明该规则是否能够创建新队列。create默认值为true;如果设置为 false 并且 Rule 要放置 app 到一个 allocations file 没有配置的队列,那么继续应用下一个 Rule; - 上例第一个规则
specified,则会把应用放到它指定的队列中,若这个应用没有指定队列名或队列名不存在,则说明不匹配这个规则,然后尝试下一个规则; primaryGroup规则会尝试把应用放在以用户所在的Unix组名命名的队列中,如果没有这个队列,不创建队列转而尝试下一个规则;- 当前面所有规则不满足时,则触发
default规则,把应用放在dev.eng队列中; - 可以
不配置queuePlacementPolicy规则,调度器则默认采用如下规则:

- 简单的配置策略:使得所有的应用放入同一个队列(default),这样就可以让所有应用之间平等共享集群而不是在用户之间。

- 例子中,
- 运行Apps数量限制及AM资源限制
- 对特定用户可以运行的 apps 的数量限制

- 设置任意用户(没有特定限制的用户)运行 app 的默认最大数量限制

- 设置队列的默认运行 app 数量限制,可以被任一队列的
maxRunningApps元素覆盖

- 设置队列的默认 AM 共享资源限制;可以被任一队列的
maxAMShare元素覆盖
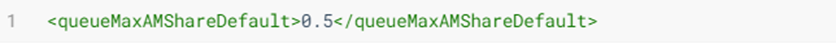
- 对特定用户可以运行的 apps 的数量限制
- 抢占(Preemption)
- 当一个 job 提交到一个繁忙集群中的空队列时,job 并不会马上执行,而是阻塞直到正在运行的 job 释放系统资源。为了使提交 job 的执行时间更具预测性(可以设置等待的超时时间),Fair 调度器支持抢占。
抢占就是允许调度器杀掉占用超过其应占份额资源队列的containers,这些 containers 资源便可被分配到应该享有这些份额资源的队列中。需要注意抢占会降低集群的执行效率,因为被终止的containers需要被重新执行。- 通过设置一个全局的参数
yarn.scheduler.fair.preemption=true来启用抢占功能。此外,还有两个参数用来控制抢占的过期时间(这两个参数默认没有配置,需要至少配置一个来允许抢占 Container):- 公平共享抢占的默认阈值
配置文件中的顶级元素<defaultFairSharePreemptionThreshold>为所有队列配置这个阈值;还可在<queue>元素内配置<fairSharePreemptionThreshold>元素来为某个队列指定超阈值,默认是 0.5。

- 公平共享抢占的默认超时时间
配置文件中的顶级元素<defaultMinSharePreemptionTimeout>为所有队列配置这个超时时间;还可在<queue>元素内配置<minSharePreemptionTimeout>元素来为某个队列指定超时时间。

如果队列在fair share preemption timeout指定时间内未获得平等的资源的一半(这个比例可以配置),调度器则会进行抢占 containers。 - 默认最小共享抢占超时时间
配置文件中的顶级元素<defaultFairSharePreemptionTimeout>为所有队列配置这个超时时间;还可在<queue>元素内配置<fairSharePreemptionTimeout>元素来为某个队列指定超时时间。

如果队列在minimum share preemption timeout指定的时间内未获得最小的资源保障,调度器就会抢占 containers。 - 哪些情况下会发生抢占
最小资源抢占,当前 queue 的资源无法保障时,而又有 apps 运行,需要向外抢占;
公平调度抢占,当前 queue 的资源为达到 max,而又有 apps 运行,需要向外抢占;
- 公平共享抢占的默认阈值
- 最小最大资源设置
资源设置格式:X表示内存,单位为MB;Y表示虚拟CPU Core核数;注意分隔符

最小资源保证:- 在每个资源池中,允许配置该资源池的最小资源,这是为了防止把空闲资源共享出去还未回收的时候,该资源池有任务需要运行时候的资源保证。
- 比如,资源池 businessA 中配置了最小资源为(5vCPU,5GB),那么即使没有任务运行,Yarn 也会为资源池 businessA 预留出最小资源,一旦有任务需要运行,而集群中已经没有其他空闲资源的时候,最小资源也可以保证资源池 businessA 中的任务可以先运行起来,随后再从集群中获取资源。

- 如果一个队列的最小共享未能得到满足,那么它将会在相同 parent 下其他队列之前获得可用资源。在单一资源公平策略下,一个队列如果它的内存使用量低于最小内存值则认为是未满足的。
- 在 DRF 策略下,如果一个队列的主资源是低于最小共享的话则认为是未满足的。如果有多个队列未满足的情况,资源分配给相关资源使用量和最小值之间比率最小的队列。
- 注意一点,有可能一个队列处于最小资源之下,但是在它提交 application 时不会立刻达到最小资源,因为已经在运行的 job 会使用这些资源。
最大资源限制- 最多可以使用的资源量,fair scheduler 会保证每个队列使用的资源量不会超过该队列的最多可使用资源量。

- 对于单一资源公平策略,vcores 的值会被忽略。一个队列永远不会分配资源总量超过这个限制。
- 最多可以使用的资源量,fair scheduler 会保证每个队列使用的资源量不会超过该队列的最多可使用资源量。
4.3 资源调度分配案例一
根据用户组分配资源池 ,假设在生产环境 Yarn 中,总共有四类用户需要使用集群,开发用户、测试用户、业务 1 用户、业务 2 用户。为了使其提交的任务不受影响,在 Yarn 上规划配置了五个资源池,分别为 dev_group(开发用户组资源池)、test_group(测试用户组资源池)、business1_group(业务1用户组资源池)、business2_group(业务2用户组资源池)、default(只分配了极少资源)。并根据实际业务情况,为每个资源池分配了相应的资源及优先级等。
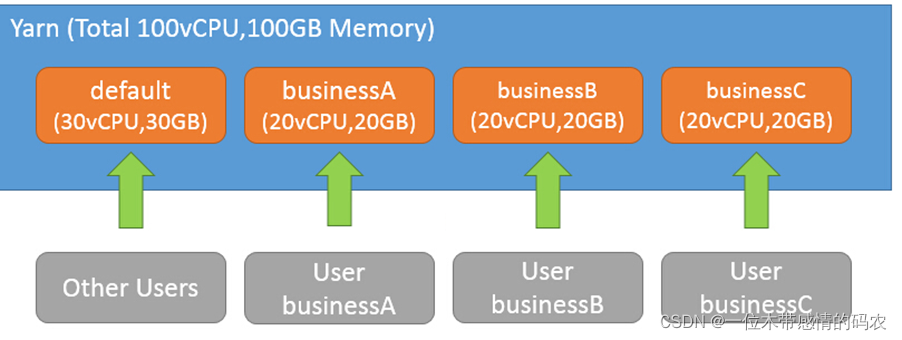
相关配置如下:
1 |
|
4.4 资源调度分配案例二
由于公司的 hadoop 集群的计算资源不是很充足,需要开启 yarn 资源队列的资源抢占。
- 只有一个队列的资源小于设置的最小资源时,才有可能启动资源抢占。
- 只要所有的资源队列的最小资源之和小于等于集群的资源总量就都是合理的。如果最小资源之和大于集群的资源总量,同时又开启了资源抢占模式,那么资源调度就会不停的处于资源抢占的模式(这样的逻辑当然是不合理的了)。
- 所有队列的最大资源配置之和可以大于集群的资源总量是合理的
- 每个队列的最大资源配置只要小于等于集群的资源总量就也是合理的。
1 |
|
- 第一: 三个资源队列 default,online,develop,bi 四个队列;集群的共有 24core,48G 内存

该示例的最小资源之和是 100%,最大资源之和可以大于资源总量,最大值可以根据实际中的情况来划分。例如在线上要优先保证线上资源,所以 online 队列的最小资源比例为 70%,最大为 100%;develop,和 bi 的最小资源都是可以为 0 的,这样才能保证在紧急情况下 online 可以抢占 100% 的资源。

- 第二:queuePlacementPolicy

5. 演示Fair Scheduler
下面以三台机器为例,进行初步设置,运行程序 MapReduce 或 Spark 程序演示。
开启 Fair Scheduler,相关参数配置,添加到HADOOP_CONF/yarn-site.xml中
1 | <!-- 设置使用公平调度器FairScheduler --> |
- 资源队列配置,文件
HADOOP_CONF/fair-scheduler.xml,内容如下:
1 |
|
- 启动 ResouceManager,打开 8088 页面
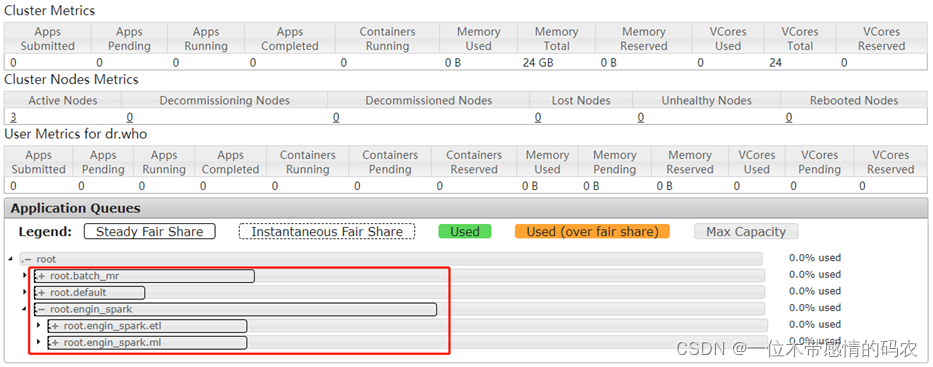
- 运行 MapReduce 中 WordCount 程序,指定运行队列 batch_mr
1
2
3
4
5
6HADOOP_HOME=/export/server/hadoop
${HADOOP_HOME}/bin/yarn jar \
${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
wordcount \
-Dmapreduce.job.queuename=batch_mr \
datas/input.data /datas/output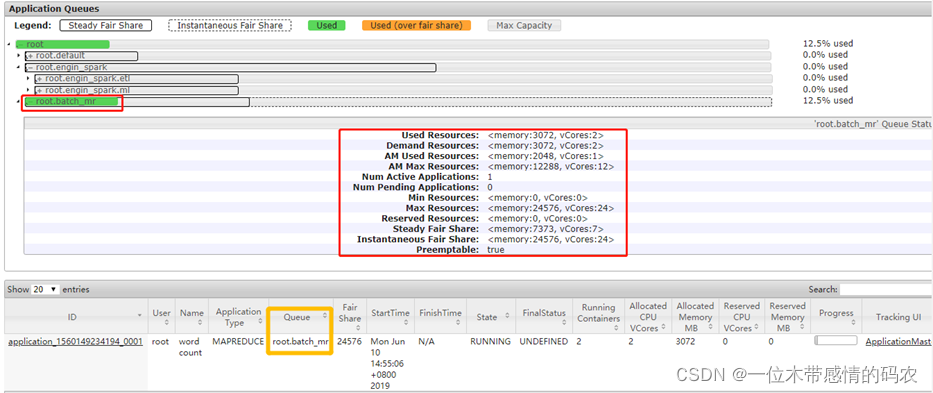
- 不指定运行队列,默认运行在default队列
1
2
3
4
5HADOOP_HOME=/export/server/hadoop
${HADOOP_HOME}/bin/yarn jar \
${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
wordcount \
datas/input.data /datas/output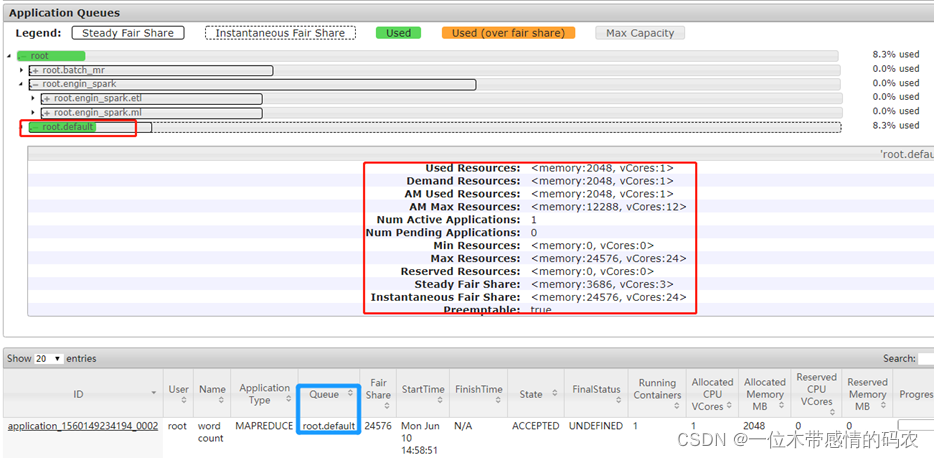
6. Fair Scheduler整体结构
公平调度器的运行流程就是RM去启动FairScheduler,SchedulerDispatcher两个服务,这两个服务各自负责 update 线程,handle 线程。
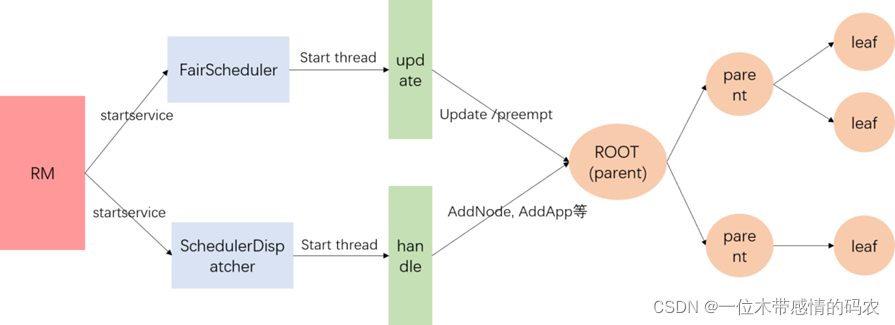
- update线程有两个任务:
- 更新各个队列的资源(Instantaneous Fair Share);
- 判断各个 leaf 队列是否需要抢占资源(如果开启抢占功能);
- handle线程主要是处理一些事件响应,比如集群增加节点,队列增加APP,队列删除APP,APP更新container等。



