
Hadoop 生态圈(三十二)- MapReduce 属性优化
前言
部分内容摘自尚硅谷、黑马等等培训资料
1. 属性优化概述
MapReduce 的核心优化在于修改数据文件类型、合并小文件、使用压缩等方式,通过降低 IO 开销来提升 MapReduce 过程中 Task 的执行效率。除此之外,MapReduce 中也可以通过调节一些参数来从整体上提升 MapReduce 的性能。
2. 基准测试
2.1 功能
可以通过基准测试来测试 MapReduce 集群对应的性能,观察实施了优化以后的 MapReduce 的性能是否得到提升等。
MapReduce 中自带了基准测试的工具 jar 包,只要运行即可看到自带的测试工具类:
1 | yarn jar /data/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar |
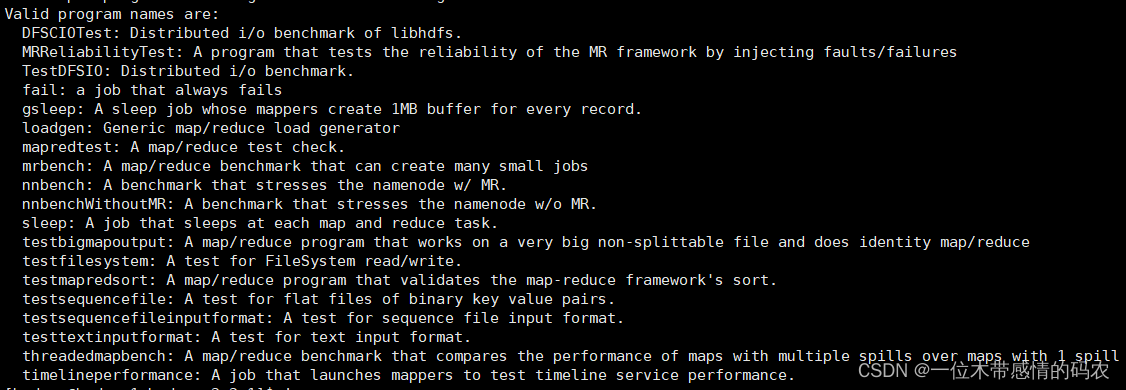
2.2 MR Bench
- 功能: 用于指定生成文件,MapTask、ReduceTask 的个数,并且可以指定执行的次数
- 语法:
1 | [-baseDir <base DFS path for output/input, default is /benchmarks/MRBench>] |
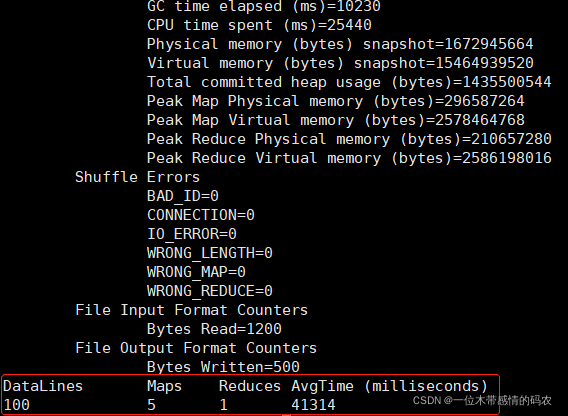
- 例如: 生成每个文件 10000 行,100 个 mapper,20 个 reducer,执行 20 次
1 | yarn jar /data/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar mrbench -numRuns 20 -inputLines 10000 -maps 100 -reduces 20 |
测试:
1 | yarn jar /data/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar mrbench -numRuns 1 -inputLines 100 -maps 5 -reduces 1 |
2.3 Load Gen
- 功能: 指定对某个数据进行加载,处理,测试性能耗时,可以调整 Map 和 Reduce 个数
- 语法:
1 | Usage: [-m <maps>] [-r <reduces>] |
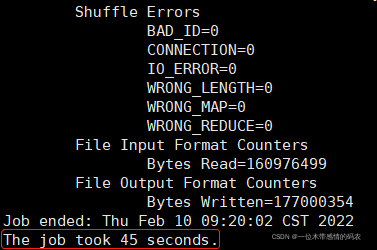
测试: 对 150M 的数据进行测试,10 个 Map,1 个 Reduce
1 | yarn jar /data/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar loadgen -m 10 -r 1 -indir /datas/input/compress -outdir /datas/output/load |
3. Uber模式
3.1 功能
我们在实际使用 MapReduce 过程会发现一种特殊情况,当运行于 Hadoop 集群上的一些 mapreduce 作业本身的数据量并不是很大,如果此时的任务分片很多,那么为每个 map 任务或者 reduce 任务频繁创建 Container,势必会增加 Hadoop 集群的资源消耗,并且因为创建分配 Container 本身的开销,还会增加这些任务的运行时延。面临这个问题,如果能将这些小任务都放入少量的 Container 中执行,将会解决这些问题。MapReduce 中就提供了这样的解决方案,Uber 模式。
Uber 运行模式对小作业进行优化,不会给每个任务分别申请分配 Container 资源,这些小任务将统一在一个 Container 中按照先执行 map 任务后执行 reduce 任务的顺序串行执行
3.2 使用
- 开启:
mapreduce.job.ubertask.enable=true(默认为false) - 条件:
- map 任务的数量不大于
mapreduce.job.ubertask.maxmaps参数(默认值是 9); - reduce 任务的数量不大于
mapreduce.job.ubertask.maxreduces参数(默认值是 1); - 输入文件大小不大于
mapreduce.job.ubertask.maxbytes参数(默认为 1 个块的大小 128M); - map 任务和 reduce 任务需要的资源量不能大于 MRAppMaster 可用的资源总量;
- map 任务的数量不大于
4. JVM重用
4.1 功能
JVM 正常指代一个 Java 进程,Hadoop 默认使用派生的 JVM 来执行 map-reducer,如果一个 MapReduce 程序中有 100 个 Map,10 个 Reduce,Hadoop 默认会为每个 Task 启动一个 JVM 来运行,那么就会启动 100 个 JVM 来运行 MapTask,在 JVM 启动时内存开销大,尤其是 Job 大数据量情况,如果单个 Task 数据量比较小,也会导致 JVM 资源,这就导致了资源紧张及浪费的情况。
为了解决上述问题,MapReduce 中提供了 JVM 重用机制来解决,JVM 重用可以使得 JVM 实例在同一个 job 中重新使用 N 次,当一个 Task 运行结束以后,JVM 不会进行释放,而是继续供下一个 Task 运行,直到运行了 N 个 Task 以后,就会释放,N 的值可以在 Hadoop 的mapred-site.xml文件中进行配置,通常在 10-20 之间。
4.2 使用
- Hadoop3 之前的配置,在
mapred-site.xml中添加以下参数
mapreduce.job.jvm.numtasks=10 - Hadoop3 中已不再支持该选项
5. 重试机制
5.1 功能
当 MapReduce 运行过程中,如果出现 MapTask 或者 ReduceTask 由于网络、资源等外部因素导致 Task 失败,AppMaster 会检测到 Task 的任务失败,会立即重新分配资源,重新运行该失败的 Task,默认情况下会重试 4 次,如果重试 4 次以后依旧没有运行成功,那么整个 Job 会终止,程序运行失败。我们可以根据实际的情况来调节重试的次数。
5.2 使用
- 可以在
mapred-site.xml中修改 - MapTask 失败后的重试次数:默认 4 次
mapreduce.map.maxattempts=4 - ReduceTask 失败后的重试次数:默认 4 次
mapreduce.reduce.maxattempts=4
6. 推测执行
6.1 功能
MapReduce 模型将 Job 作业分解成 Task 任务,然后并行的运行 Task 任务,使整个 Job 作业整体执行时间少于各个任务顺序执行时间。这会导致作业执行时间多,但运行缓慢的任务很敏感,因为运行一个缓慢的 Task 任务会使整个 Job 作业所用的时间远远长于其他 Task 任务的时间。
当一个 Job 有成百上千个 Task 时,可能会出现拖后腿的 Task 任务。Task 任务执行缓慢可能有多种原因,包括硬件老化或软件配置错误,但检测问题具体原因很难,因为任务总能成功执行完,尽管比预计时间长。Hadoop 不会尝试诊断或修复执行慢的任务。
推测执行时指在一个 Task 任务运行比预期慢时,程序会尽量检测并启动另一个相同的任务作为备份,这就是推测执行(speculative execution),但是如果同时启动两个相同的任务他们会相互竞争,导致推测执行无法正常工作,这对集群资源是一种浪费。
只有在一个 Job 作业的所有 Task 任务都启动之后才会启动推测任务,并只针对已经运行一段时间(至少一分钟)且比作业中其他任务平均进度慢的任务。一个任务成功完成后任何正在运行的重复任务都将中止。如果原任务在推测任务之前完成则推测任务就会被中止,同样,如果推测任务先完成则原任务就会被中止。
推测任务只是一种优化措施,它并不能使 Job 作业运行的更加可靠。如果有一些软件缺陷造成的任务挂起或运行速度慢,依靠推测执行是不能成功解决的。默认情况下推测执行是启用的,可根据集群或每个作业,单独为 map 任务或 reduce 任务启用或禁用该功能。
6.2 使用
- 在
mapred-site.xml中修改默认属性 - MapTask 的推测执行机制:默认开启
mapreduce.map.speculative=false - ReduceTask 的推测执行机制:默认开启
mapreduce.reduce.speculative=false
7. 其他属性优化
7.1 开启小文件合并优化
- 针对于小文件,默认每个小文件会构建一个分片,可以使用 CombineTextInputFormat 代替 TextInputFormat,将多个小文件合并为一个分片;
- 实现:
1 | //设置输入类 |
7.2 减少Shuffle的Spill和Merge
- 减少 spill,默认每个缓冲区大小为 100M,每次达到 80% 开始 spill,如果调大这两个值,可以减少数据 spill 的次数,从而减少磁盘 IO
- 修改 mapred-site.xml:
mapreduce.task.io.sort.mb=200
mapreduce.map.sort.spill.percent=0.9
- 修改 mapred-site.xml:
- 减少 merge,默认每次生成 10 个小文件开始进行合并,如果增大文件个数,可以减少 merge 的次数,从而减少磁盘 IO
- 修改 mapred-site.xml:
mapreduce.task.io.sort.factor=15
- 修改 mapred-site.xml:
7.3 开启Reduce端缓存
- 默认情况下 Reduce 端会将数据从 Buffer 缓存写入磁盘,然后再从磁盘读取数据进行处理,Buffer 中不会存储数据,如果内存允许的情况下,我们可以直接将 Buffer 的数据缓存在内存中,读取时直接从内存中获取数据。
- 修改
mapred-site.xml,指定 20% 内存空间用来存储 Buffer 的数据,默认为 0:
mapreduce.reduce.input.buffer.percent=0.2



