
Hadoop 生态圈(三十)- Hadoop 数据压缩
前言
部分内容摘自尚硅谷、黑马等等培训资料
1. 概述
可以对map的输出进行压缩(map 输出到 reduce 输入的过程,可以压缩 shuffle 过程中网络传输的数据量)
可以对reduce的输出结果进行压缩(最终保存到 hdfs 上的数据,主要是减少占用 HDFS 存储)
- 压缩的好处和坏处
压缩的优点:以减少磁盘 IO、减少磁盘存储空间;压缩的缺点:增加 CPU 开销;
- 压缩原则
- 运算密集型的 Job,少用压缩;
- IO 密集型的 Job,多用压缩;
2. Hadoop支持的压缩算法
使用hadoop checknative来查看 hadoop 支持的各种压缩算法,如果出现 openssl 为 false,那么就在线安装一下依赖包。
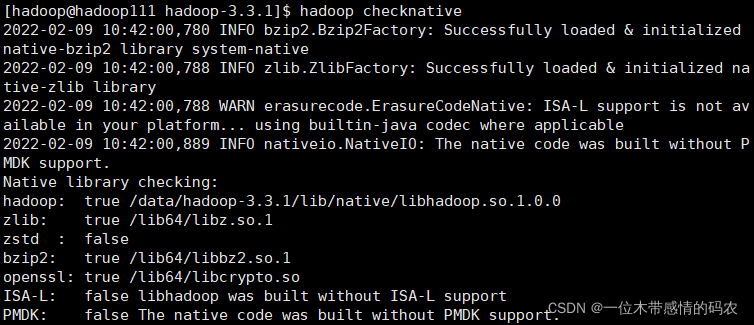
压缩算法对比介绍:
| 压缩格式 | Hadoop自带? | 算法 | 文件扩展名 | 是否可切片 | 换成压缩格式后,原来的程序是否需要修改 |
|---|---|---|---|---|---|
| DEFLATE | 是,直接使用 | DEFLATE | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip | 是,直接使用 | DEFLATE | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO | 否,需要安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| LZ4 | 是,直接使用 | LZ4 | .lz4 | 否 | - |
| Snappy | 是,直接使用 | Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |
各种压缩算法对应使用的java类:
| 压缩格式 | 对应使用的java类 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DeFaultCodec |
| gzip | org.apache.hadoop.io.compress.GZipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
3. 压缩方式选择
压缩方式选择时重点考虑:压缩/解压缩速度、压缩率(压缩后存储大小)、压缩后是否可以支持切片。
- Gzip压缩
- 优点:压缩率比较高;
- 缺点:不支持Split;压缩/解压速度一般;
- Bzip2压缩
- 优点:压缩率高;支持Split;
- 缺点:压缩/解压速度慢。
- Lzo压缩
- 优点:压缩/解压速度比较快;支持Split;
- 缺点:压缩率一般;想支持切片需要额外创建索引。
- Snappy压缩
- 优点:压缩和解压缩速度快;
- 缺点:不支持Split;压缩率一般;
4. 压缩位置选择

5. 压缩的设置方式
5.1 方式一:代码中设置
5.1.1 设置map输出数据压缩
1 | Configuration configuration = new Configuration(); |
5.1.2 设置reduce输出数据压缩
1 | configuration.set("mapreduce.output.fileoutputformat.compress","true"); |
5.2 方式二:配置文件全局设置
可以修改mapred-site.xml配置文件,然后重启集群,以便对所有的 mapreduce 任务进行压缩。
5.2.1 设置map输出数据压缩
1 | <property> |
5.2.2 设置reduce输出数据压缩
1 | <property> |
所有节点都要修改mapred-site.xml,修改完成之后记得重启集群。
此文章版权归 程序园 所有,如有转载,请注明来自原作者。
相关推荐

评论
ValineDisqus


