
Hadoop生态圈(二十八)- MapReduce Map 阶段核心源码分析
前言
部分内容摘自尚硅谷、黑马等等培训资料
1. Map阶段整体概述
input File 通过 split 被逻辑切分为多个 split 文件,通过 Record 按行读取内容给 map(用户自己实现的)进行处理,数据被 map 处理结束之后交给 OutputCollector 收集器,对其结果 key 进行分区(默认使用 hash 分区),然后写入 buffer,每个 map task 都有一个内存缓冲区,存储着 map 的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个 map task 结束后再对磁盘中这个 map task 产生的所有临时文件做合并,生成最终的正式输出文件,然后等待 reduce task 来拉数据。
2. 前置:解读MapTask类
在 MapReduce 程序中,初登场的 task 叫做 maptask。MapTask类作为 maptask 的一个载体,调用的就是里面的 run 方法,开启 map 任务。
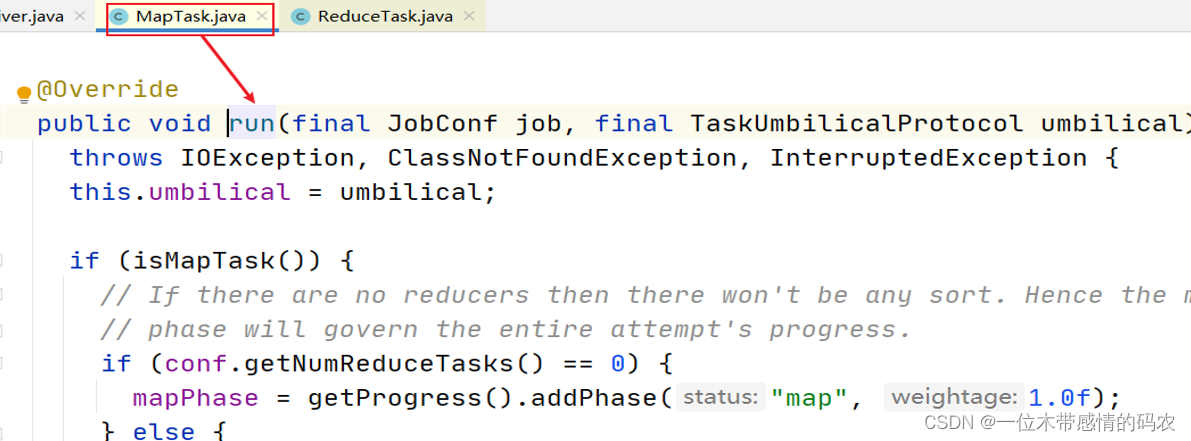
2.1 第一层调用(run)
在 MapTask.run 方法的第一层调用中,有下面两个重要的代码段。
2.1.1 map阶段的任务划分
1 | if (isMapTask()) { // 判断当前的task是否为maptask |
2.1.2 运行Mapper
在提交任务的时候 MR 框架会自己进行选择使用什么 API。默认情况下,使用的都是新的API,除非特别指定了使用 old API 详细见job.setUseNewAPI()。

2.2 第二层调用(runNewMapper)准备部分
默认情况下,框架使用 new API 来运行,所以将执行runNewMapper()。
runNewMapper 内第一大部分代码我们称之为 maptask 运行的准备部分,其主要逻辑是创建 maptask 运行时需要的各种依赖:包括 Split 切片信息、inputFormat、LineRecordReader、用户写的 map 函数(位于自定义 mapper 中)、taskContext 上下文、输出收集器 OutputCollector,用于 maptask 处理完数据输出结果。
2.2.1 TaskContext
TaskContext 为 Task 的上下文对象,基于此对象可以获取到 Task 执行期间的相关状态信息。
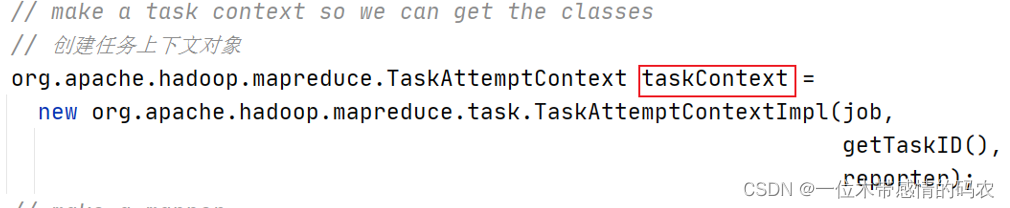
2.2.2 split
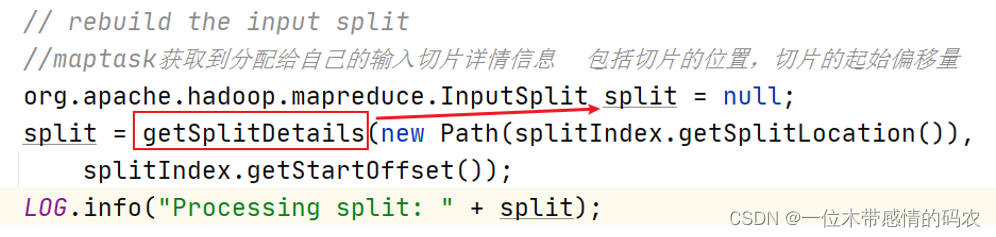
2.2.3 inputFormat

2.2.4 RecordReader

在 NewTrackingRecordReader 方法中,最终创建了 RecordReader

2.2.5 mapper

2.2.6 OutputCollector

2.3 第二层调用(runNewMapper)工作部分
runNewMapper 内第二大部分代码我们称之为 maptask 工作干活的部分,其主要逻辑是:如何从切片读取数据,如何调用map处理数据,如何调用OutputCollector收集输出的数据。
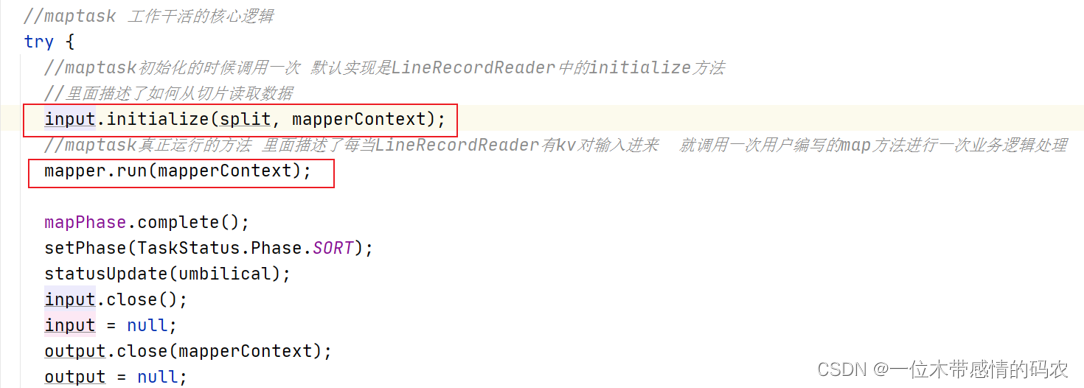
2.3.1 RecoderReader.initialize
默认情况下的实现逻辑位于 LineRecorderReader 中。核心逻辑:
打开文件定位切片的位置,判断文件是否压缩,如果切片不是第一个切片那么读取数据的时候舍去第一行数据不要读取。

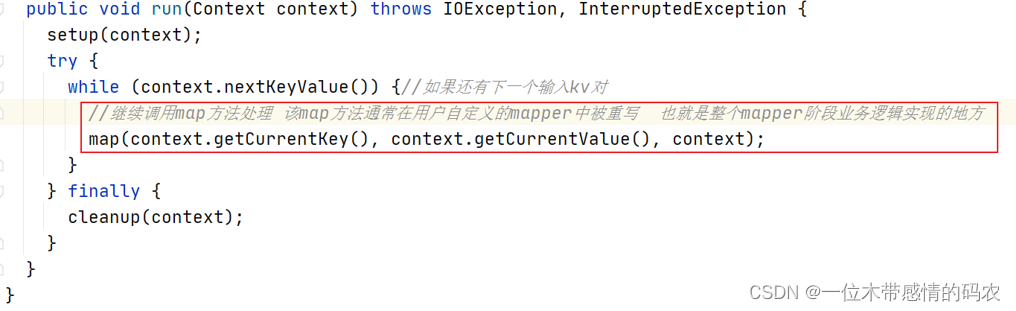
2.3.2 mapper.run

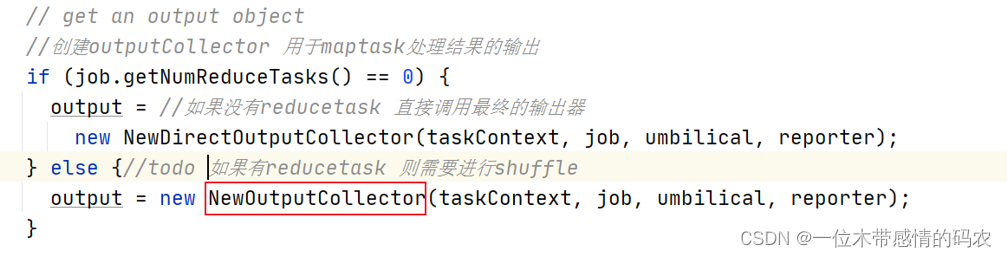
2.3.3 NewOutputCollector
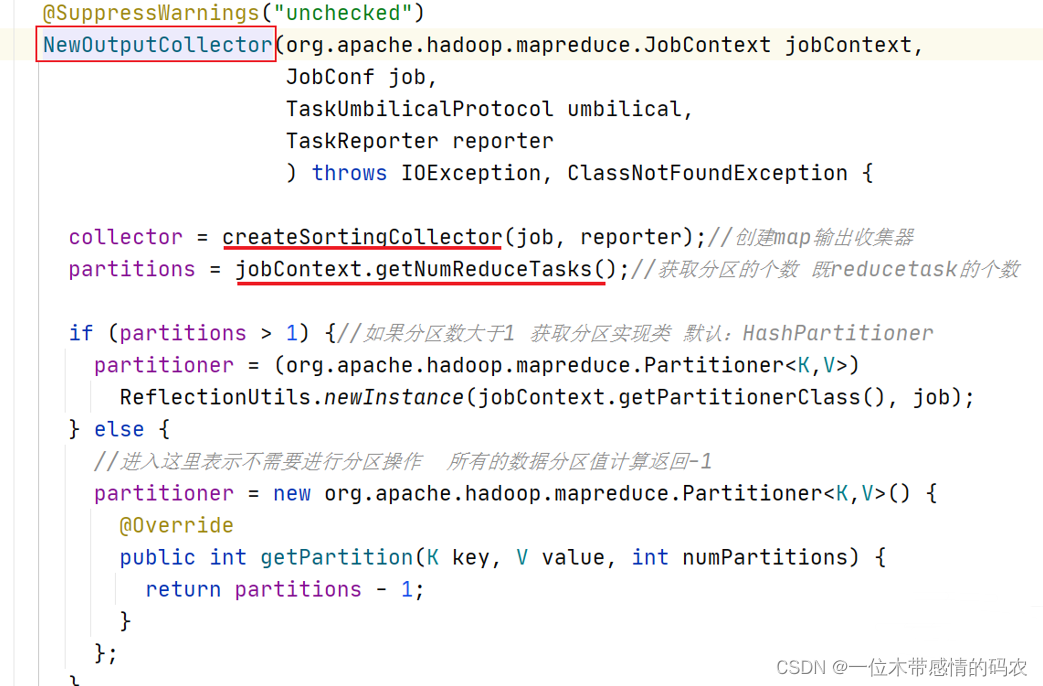
在这段程序中,createSortingCollector创建map输出收集器是最复杂的一部分,因为和后续环形缓冲区操作有关。进入 createSortingCollector 方法。
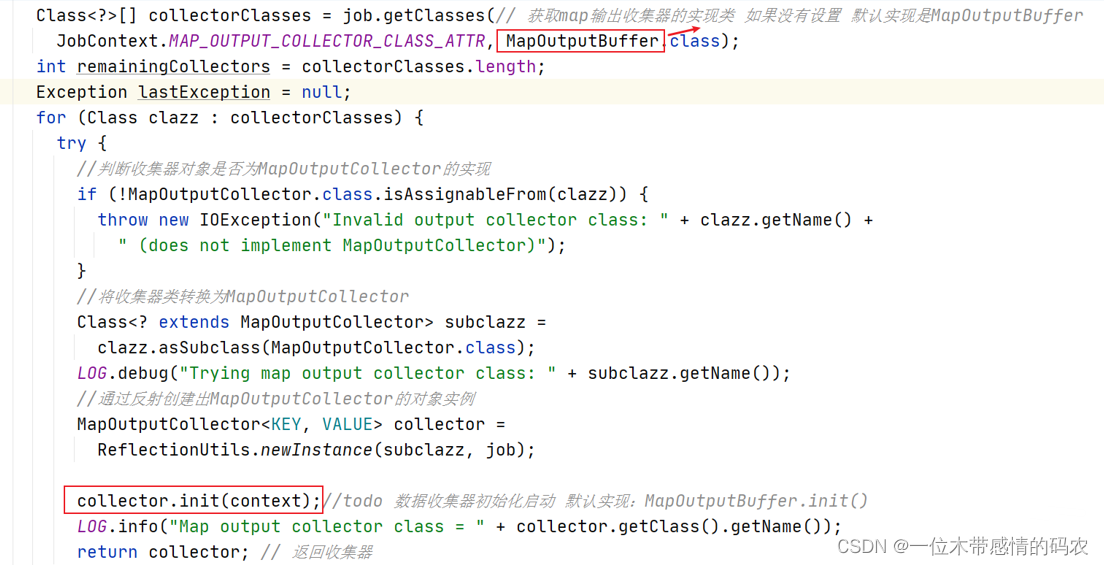
注意此处的默认实现是 MapOutputBuffer。
关于输出收集器和环形缓冲区的细节后面再描述。
3. InputFormat
整个 MapReduce 以 InputFormat 开始,其负责读取待处理的数据。默认的实现叫做TextInputFormat。
InputFormat 核心逻辑体现在两个方面:
- 如何读取待处理目录下的文件。一个一个读?还是一起读?
- 读取数据的行为是什么以及返回什么样的结果?一行一行读?按字节读?
3.1 getSplits
对于待处理的目录文件,MapReduce 程序面临的首要问题就是:究竟启动多少个 MapTask 来处理本次 job。
该问题也叫做maptask的并行度问题,指的是map阶段有多少个并行的task共同处理任务。
map 阶段并行度由客户端在提交 job 时决定,即客户端提交job之前会对待处理数据进行逻辑切片。切片完成会形成切片规划文件(job.split),每个逻辑切片最终对应启动一个 maptask。
逻辑切片机制由FileInputFormat实现类的getSplits()方法完成。
首先需要计算出 split size 切片大小,其计算方法如下:


其中 maxSize,minSize 的默认值为:



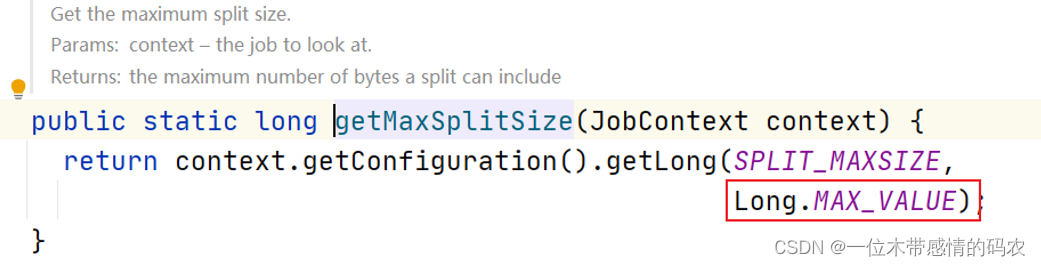
因此,通过计算,默认情况下,最终split size= block size =128M。
以切片大小逐个遍历待处理的文件,形成逻辑规划文件,比如待处理目录下有下面几个文件:
1 | a.txt 300M |
将会生成如下几个逻辑切片信息:
1 | split0 -> a.txt 0~128M |
默认情况下,有多少个split就对应启动多少个MapTask。
在 getSplits 方法中,创建了一个集合 splits,用于保存最终的切片信息。

集合中的每个元素就是一个切片的具体信息:
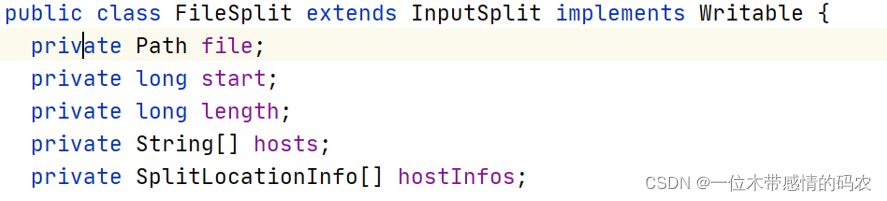
生成的切片信息在客户端提交 job 中,也就是 JobSubmitter.writeSplits 方法中,把所有切片进行排序,大的切片在前,然后序列化到一个文件中,此文件叫做逻辑切片文件。
3.1.1 bytesRemaining
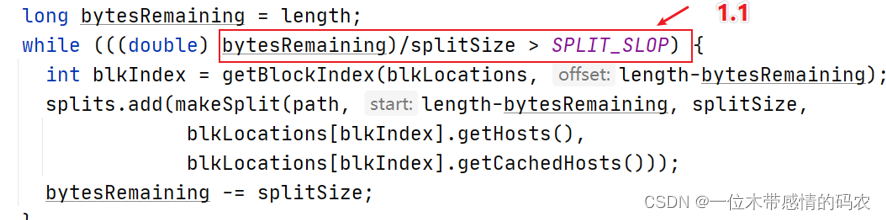
在进行逻辑切片的时候,假如说一个文件恰好是 129M 大小,那么根据默认的逻辑切片规则将会形成一大一小两个切片(0-128 128-129),并且将启动两个 maptask。这明显对资源的利用效率不高。
因此在设计中,MapReduce 时刻会进行 bytesRemaining,剩下文件大小,如果剩下的不满足 bytesRemaining/splitSize > SPLIT_SLOP,那么将不再继续split,而是剩下的所有作为一个切片整体。

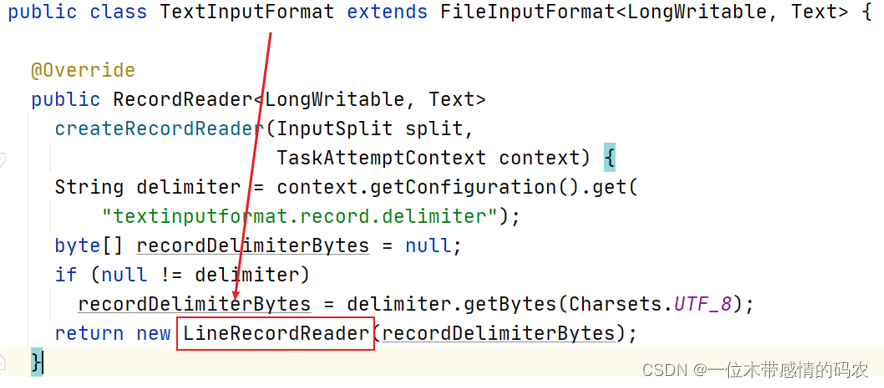
3.2 createRecordReader
最终负责读取切片数据的是 RecordReader 类,默认实现是LineRecordReader。其名字已经透露出来其读取数据的行为是:一行一行按行读取数据。
在 LineRecordReader 中,核心的方法有: initialize 初始化方法,nextKeyValue 读取数据方法。
3.2.1 initialize
initialize 属于 LineRecordReader 的初始化方法,会被 MapTask 调用且调用一次。里面描述了如何从切片读取数据。
1 | public void initialize(InputSplit genericSplit, TaskAttemptContext context) throws IOException { |
3.2.2 nextKeyValue
nextKeyValue 方法用于判断是否还有下一行数据以及定义了按行读取数据的逻辑:
一行一行读取,返回<key,value>键值对类型数据
其中key是每行起始位置的offset偏移量,value为这一行的内容。
1 | public boolean nextKeyValue() throws IOException { |
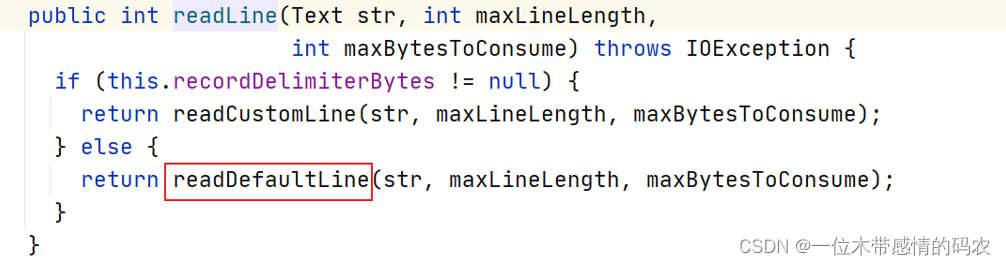

3.2.3 优化措施
由于文件在 HDFS 上进行存储的时候,物理上会进行分块存储,可能会导致文件内容的完整性被破坏。为了避免这个问题,在实际读取 split 数据的时候,每个 maptask 会进行读取行为的调整,具体来说:
一是:每个maptask都多处理下一个split的第一行数据;
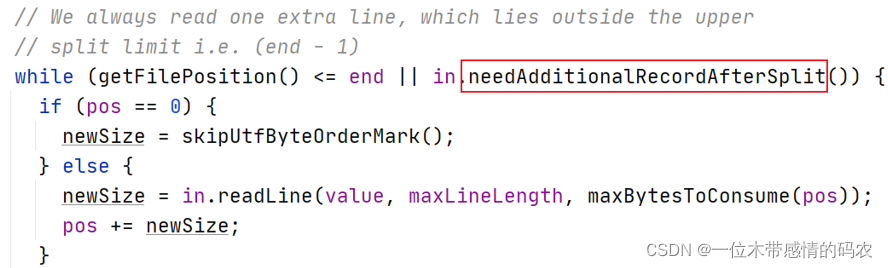
二是:除了第一个,每个maptask都舍去自己的第一行数据不处理。

4. Mapper
mapper 中有 3 个方法,分别是setup初始化方法、map方法、cleanup扫尾清理方法。而 maptask 的业务处理核心是在 map 方法中定义的。用户可以在自定义的 mapper 中重写父类的 map 方法逻辑。
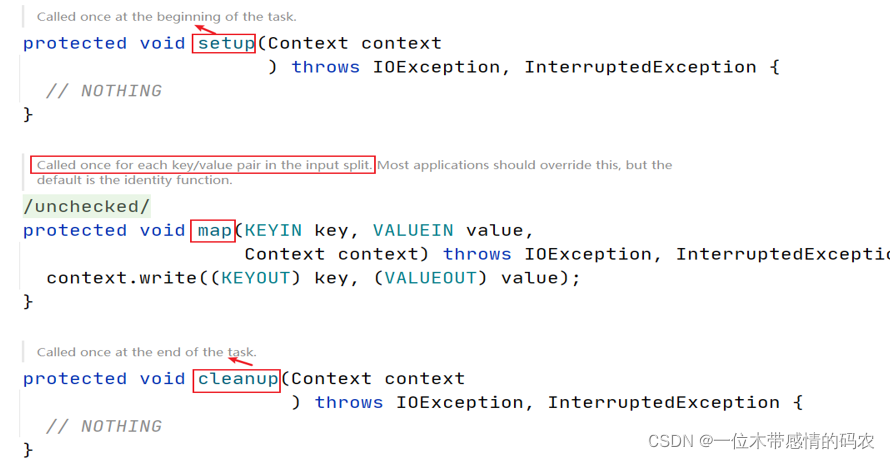
4.1 map
对于 map 方法,如果用户不重写,父类中也有默认实现逻辑。其逻辑为:输入什么,原封不动的输出什么,也就意味着不对数据进行任何处理。
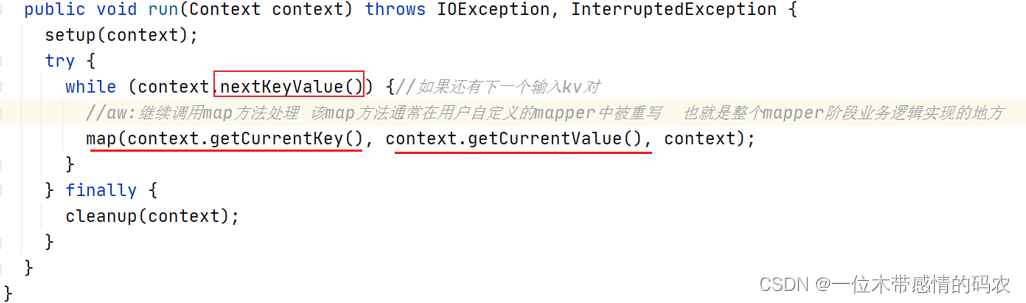
此外还要注意,map 方法的调用周期、次数取决于父类中 run 方法。当 LineRecordReader.nextKeyValue 返回 true 时,意味着还有数据,LineRecordReader每读取一行数据,返回一个kv键值对,就调用一次map方法。
因此得出结论:mapper 阶段默认情况下是基于行处理输入数据的。
5. OutputCollector
map 方法中根据业务逻辑一行行处理完之后,最终是调用的是 context.write() 方法将结果输出。至于输出的数据到哪里,在 MapTask 类中定义了两种情况,即:MR 程序是否有 Reducer 阶段?
如果有reducer阶段,则创建输出收集器。
如果没有reducer阶段,则创建outputFormat,默认实现是TextOutputFormat,直接将处理的结果输出到指定目录文件中。
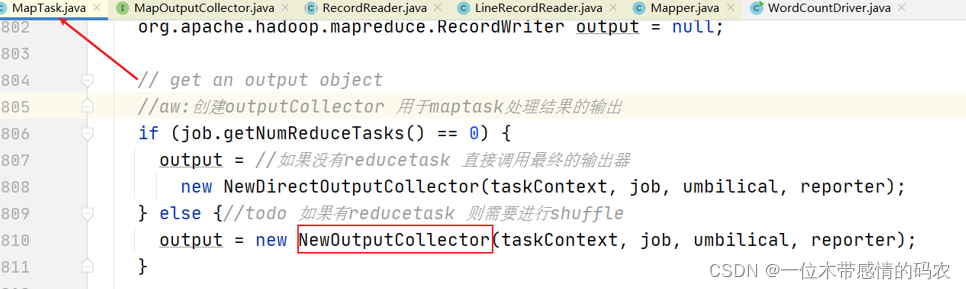
我们关注的重点当然是带有 reducer 阶段的 MR 程序,否则程序到此就结束了。
进入 NewOutputCollector 构造方法,核心方法是createSortingCollector。此外还确定了程序是否需要进行分区以及分区的实现类是什么。
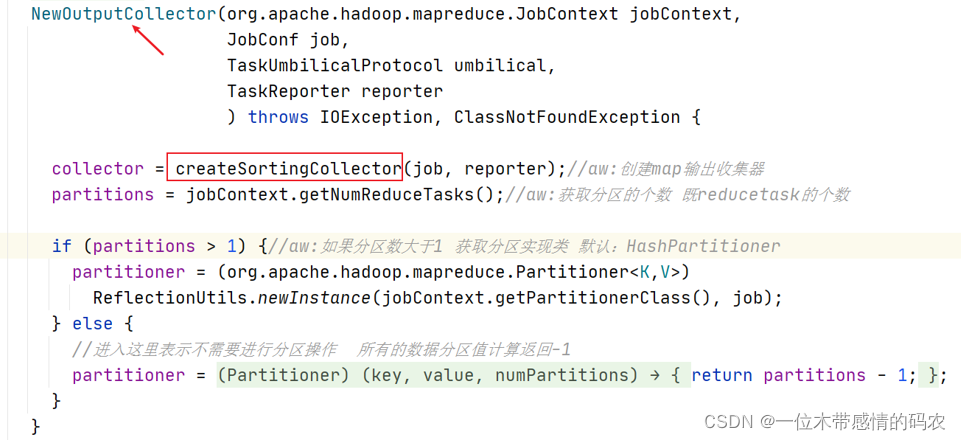
在 createSortingCollector 方法内部,核心是创建具体的输出收集器MapOutputBuffer。
MapOutputBuffer 就是口语中俗称的map输出的缓冲区,即在有 reduce 阶段的情况下,map 的输出结果不是直接写入磁盘的,还是先写入内存的缓冲区中。

当创建好 MapOutputBuffer 之后,在返回给 MapTask 之前对其进行了 init 初始化。关于初始化的细节我们在环形缓冲区中细说。
5.1 Partitioner
在程序的 mapper 阶段 context.write 打上断点,追踪一下输出的数据进行了哪些操作。
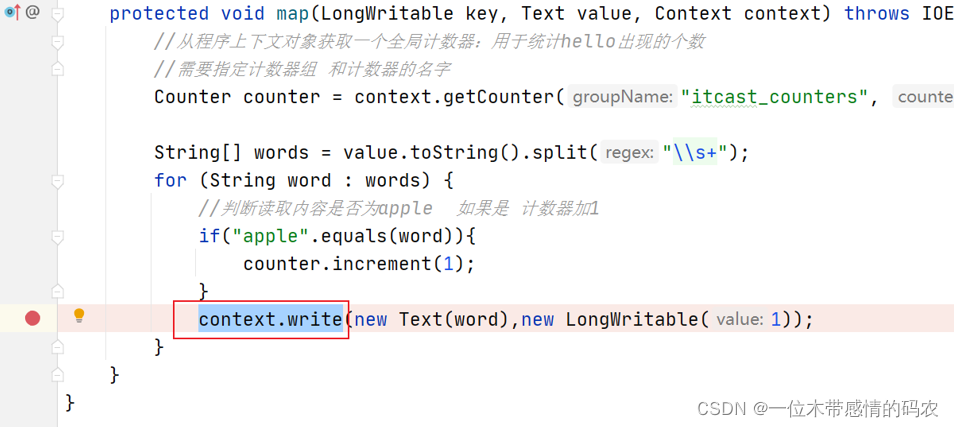
不断进入发现,最终调用的是 MapTask 中的 Write 方法。Write 方法中把输出的数据 kv 通过收集器写入了环形缓冲区,在写入之前这里还进行了数据分区计算。

partitioner.getPartition(key, value, partitions) 就是计算每个 mapper 的输出分区编号是多少。注意,只有当reducetask>1的时候。才会进行分区的计算。
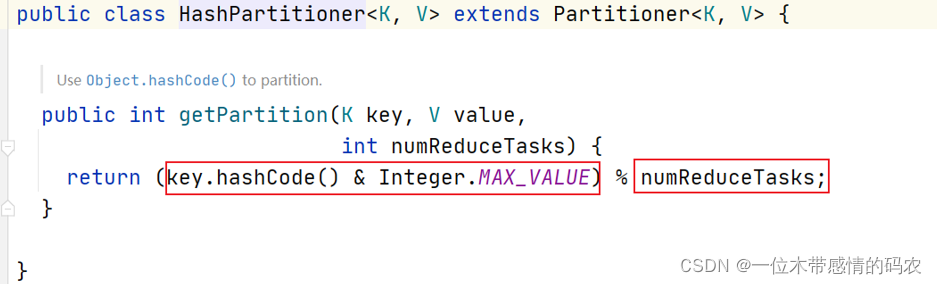
默认的分区器在 JobContextImpl 中定义,是HashPartitioner。

默认的分区规则也很简单:key.hashCode() % numReduceTasks
为了避免hashcode值为负数,通过和Integer最大值进行与计算修正hashcode为正。
5.2 Circular buffer
5.2.1 环形缓冲区概念及意义
环形缓冲区(Circular buffer)的环形是一个抽象概念。缓冲区的作用是批量收集 mapper 的输出结果,减少磁盘 IO 的影响。想一下,一个一个写和一个批次一个批次写,哪种效率高?
环形缓冲区本质是 byte 数组,里面存放着key、value的序列化数据和key、value的元数据信息。
其中kvbuffer字节数组存储真正的 kv 数据,kvmeta存储对应的元数据。
每个 key/value 对应一个元数据,元数据由 4 个 int 组成:第一个 int 存放 value 的起始位置,第二个存放 key 的起始位置,第三个存放 partition,最后一个存放 value 的长度。
因为 key/value 写入 kvbuffer 时是要经过序列化的,所以我们要记录每一个 key 和 value 序列化后在 kvbuffer 中的起始和终止位置。
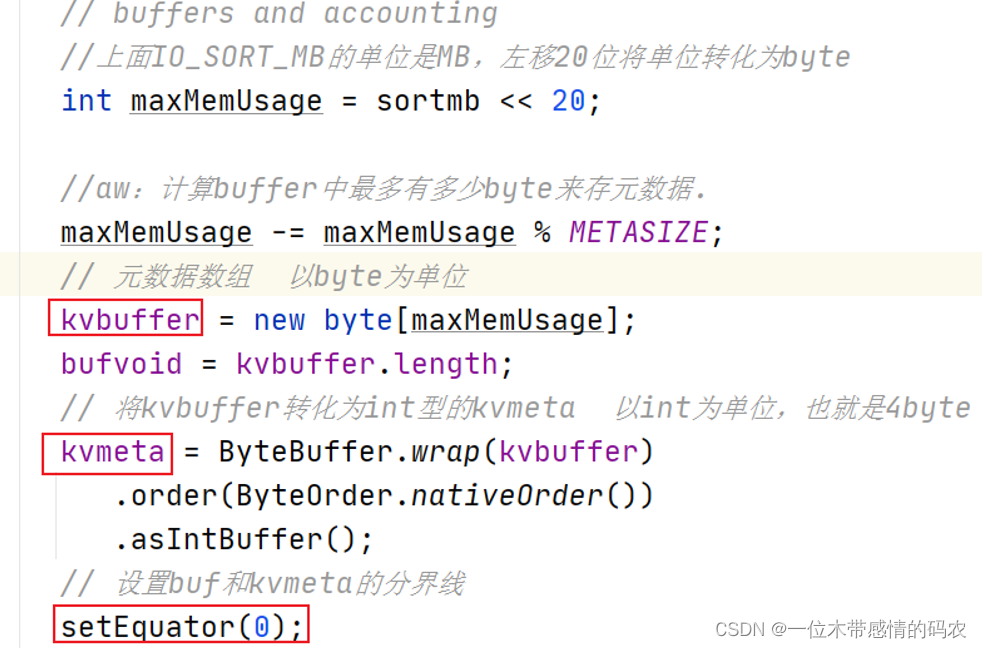
1 | //aw:存储元数据信息 注意这是一个intbuffer |
key/value 序列化的数据和元数据在环形缓冲区中的存储是由 equator(赤道)分隔的。
key/value 按照索引递增的方向存储,meta 则按照索引递减的方向存储,将其数组抽象为一个环形结构之后,以 equator 为界,key/value 顺时针存储,meta 逆时针存储。
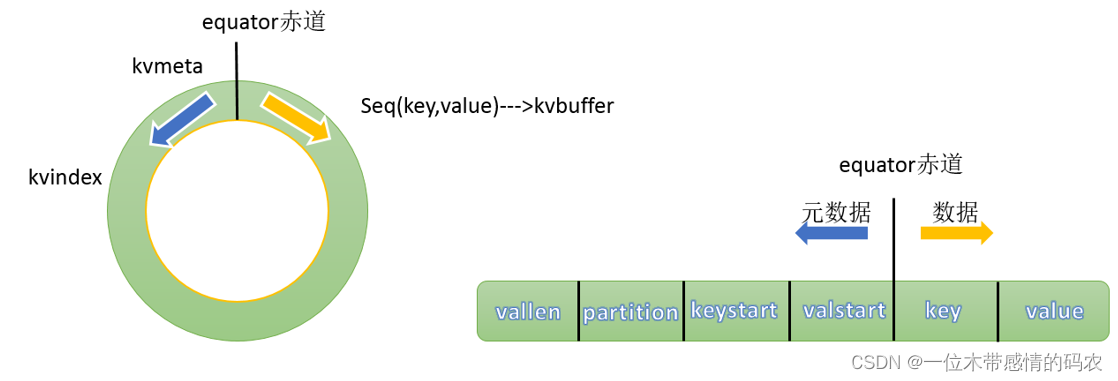
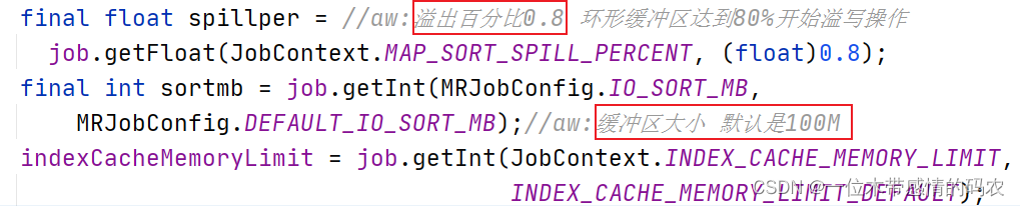
环形缓冲区是有大小限制,默认是100MB。由参数mapreduce.task.io.sort.mb控制。
5.2.2 环形缓冲区的初始化
在 MapTask 中创建 OutputCollector 的时候,对环形缓冲区进行了初始化的动作。

初始化的过程中,主要是构造环形缓冲区的抽象数据结构。包括不限于:设置缓冲区大小、溢出比、初始化kvbuffer|kvmeta、设置Equator标识分界线、构造排序的实现类、combiner、压缩编码等。


5.2.3 环形缓冲区的数据收集
mapper 的 map 方法处理完数据之后,是调用 context.write 方法将结果进行输出。debug 不断进入发现,最终调用的是 MapTask 中的 Write 方法。

在 write 方法中,调用collector.collect向环形缓冲区中写入数据,数据写入之前也进行了分区 partition 计算。在有 reducer 阶段的情况下,collector的实现是MapOutputBuffer。
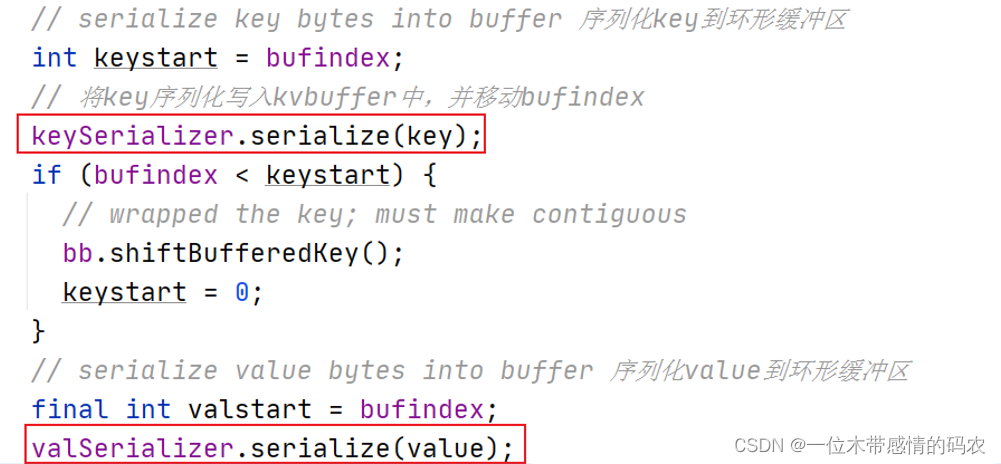
收集数据到环形缓冲区核心逻辑有:序列化key到字节数组,序列化value到字节数组,写入该条数据的元数据(起始位置、partition、长度)、更新kvindex。

5.3 Spill、Sort
5.3.1 Spill溢写
环形缓冲区虽然可以减少 IO 次数,但是总归有容量限制,不能把所有数据一直写入内存,数据最终还是要落入磁盘上存储的,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。
这个溢写是由单独线程来完成,不影响往缓冲区继续写数据。整个缓冲区有个溢写的比例 spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),spill 线程启动。
spill线程是由startSpill()方法唤醒的,在进行 spill 操作的时候,此时 map 向 buffer 的写入操作并没有阻塞,剩下 20M 可以继续使用。
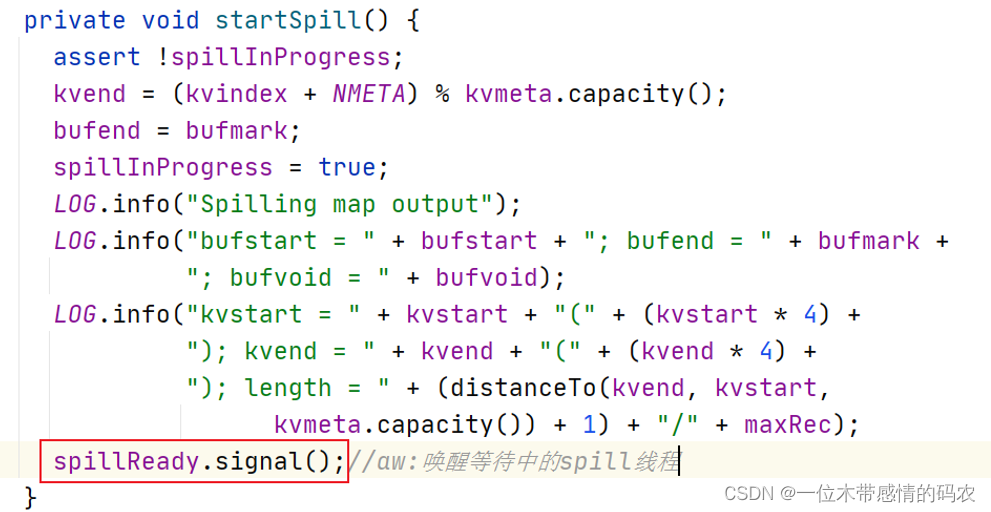
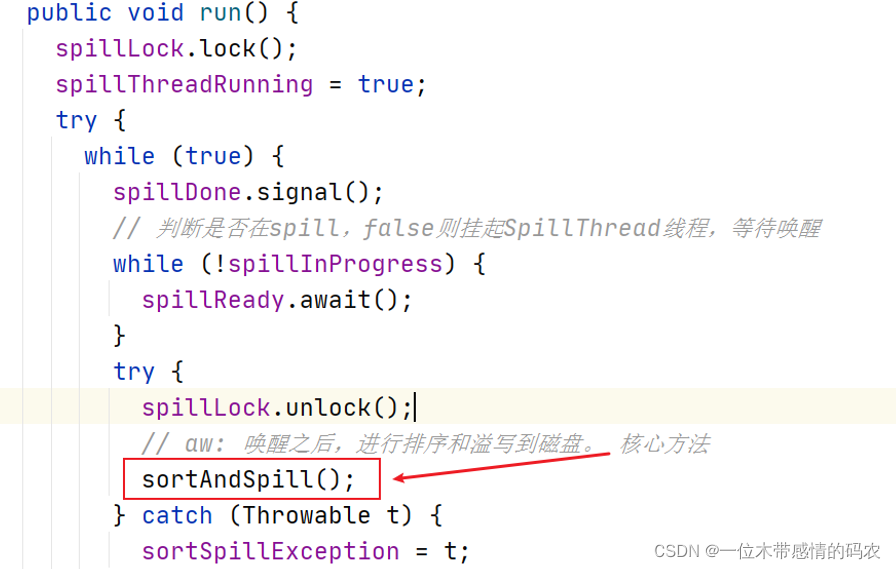
溢写的线程叫做SpillThread,查看其 run 方法,run 中主要是 sortAndSpill。
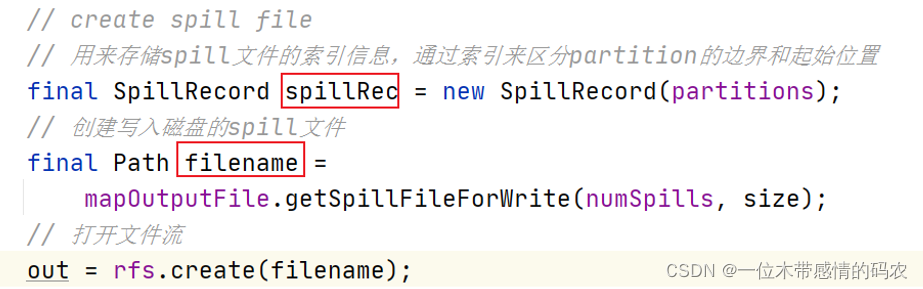
创建溢写记录(索引)、溢写文件(该文件位于机器的本地文件系统,而不是 HDFS)。
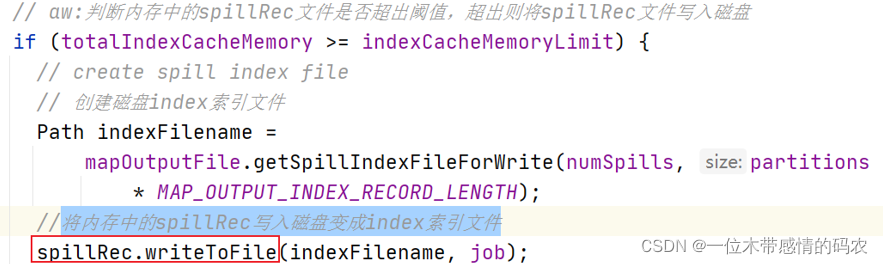
SpillThread输出的每个 spill 文件都有一个索引,其中包含有关每个文件中分区的信息-分区的开始位置和结束位置。这些索引存储在内存中,叫做SpillRecord溢写记录,可使用内存量为mapreduce.task.index.cache.limit.bytes,默认情况下等于 1MB。
如果不足以将索引存储在内存中,则所有下一个创建的溢出文件的索引都将与溢出文件一起写入磁盘。
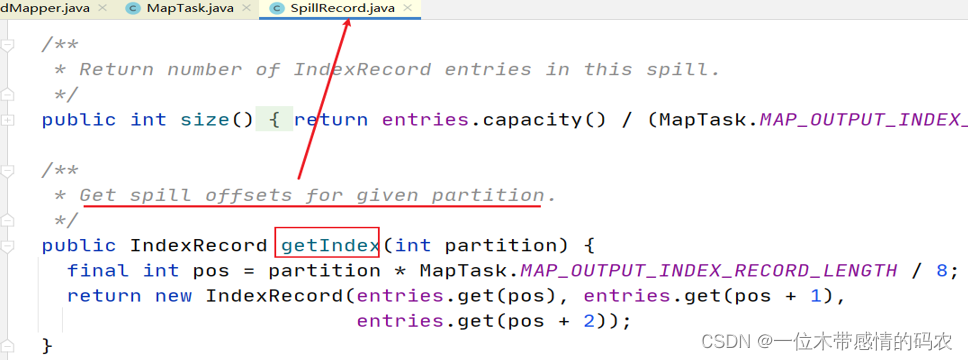
溢写数据到临时文件中:
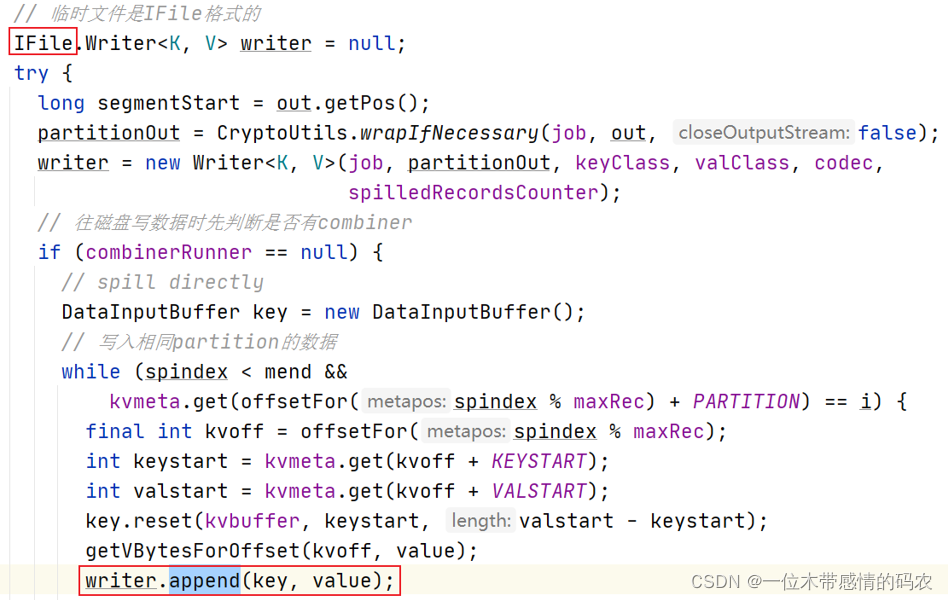
更新 spillRec:

将内存中的 spillRec 写入磁盘变成索引文件。
在 spill 的同时,map 往 buffer 的写操作并没有停止,依然在调用 collect。满足条件继续 spill,以此往复。
5.3.2 Sort排序
在溢写的过程中,会对数据进行排序。
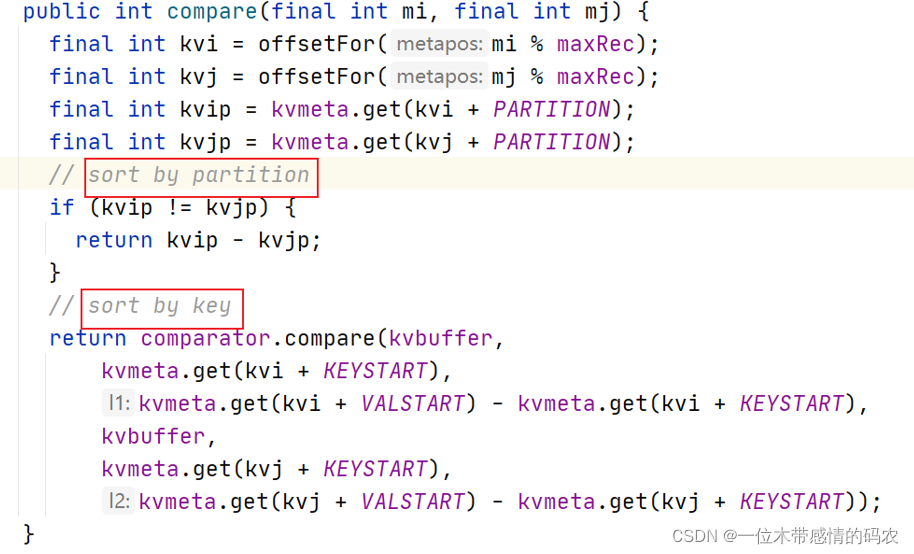
排序规则是 MapOutputBuffer.compare,采用的是QuickSort快速排序。
先对 partition 进行排序其次对 key 值排序。这样,数据按分区排序,并且在每个分区内按键对数据排序。

5.4 Merge
每次 spill 都会在磁盘上生成一个临时文件,如果 map 的输出结果真的很大,有多次这样的 spill 发生,磁盘上相应的就会有多个临时文件存在。这样将不利于 reducetask 处理数据。
当 mapper 和最后一次溢出都结束时,溢出线程终止,合并(merge)阶段开始。
在合并阶段,应将所有溢出文件合并在一起以形成一个map输出文件。
默认情况下,一个合并过程最多可以处理 100 个溢出文件(负责此操作的参数是mapreduce.task.io.sort.factor)。如果超过,将进行多次 merge 合并。
最终一个 maptask 的结果是一个输出文件,其中包含 map 的所有输出数据以及索引文件,索引文件描述了 ReduceTask 的分区开始-停止信息,以便能够轻松获取与其将运行的相关分区数据。
6. Combiner
Combiner(规约)的作用就是对 map 端的输出先做一次合并,以减少在 map 和 reduce 节点之间的数据传输量,以提高网络 IO 性能,是 MapReduce 的一种优化手段之一。默认情况下不开启。
当 job 设置了 Combiner,可能会在 spill 和 merge 的两个阶段执行。
spill 时 combiner 执行情况源码:

merge 时 combiner 执行情况源码:MapTask 中搜 mergeParts 方法。




