前言
部分内容摘自尚硅谷、黑马等等培训资料
1. MapReduce工作流
使用 Hadoop 里面的 MapReduce 来处理海量数据是非常简单方便的,但有时候我们的应用程序,往往需要多个 MR 作业,来计算结果,比如说一个最简单的使用 MR 提取海量搜索日志的 TopN 的问题,注意,这里面,其实涉及了两个 MR 作业,第一个是词频统计,第两个是排序求 TopN,这显然是需要两个 MapReduce 作业来完成的。其他的还有,比如一些数据挖掘类的作业,常常需要迭代组合好几个作业才能完成,这类作业类似于 DAG 类的任务,各个作业之间是具有先后,或相互依赖的关系,比如说,这一个作业的输入,依赖上一个作业的输出等等。
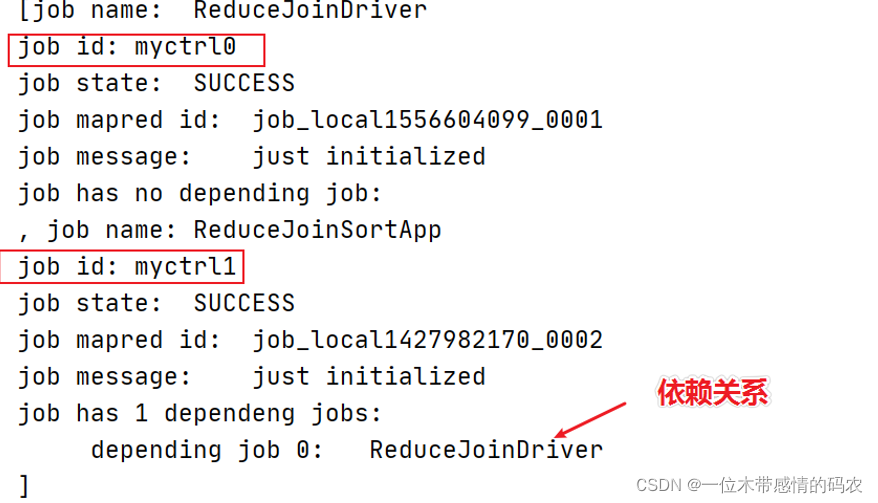
在 Hadoop 里实际上提供了,JobControl类,来组合一个具有依赖关系的作业,在新版的API里,又新增了ControlledJob类,细化了任务的分配,通过这两个类,我们就可以轻松的完成类似DAG作业的模式,这样我们就可以通过一个提交来完成原来需要提交 2 次的任务,大大简化了任务的繁琐度。具有依赖式的作业提交后,hadoop 会根据依赖的关系,先后执行的 job 任务,每个任务的运行都是独立的。
1.1 需求
针对 MapReduce reduce join 方式处理订单和商品数据之间的关联,需要进行两步程序处理,首先把两个数据集进行join操作,然后针对join的结果进行排序,保证同一笔订单的商品数据聚集在一起。(具体可见上一篇《Hadoop生态圈(二十五)- MapReduce Join操作》)
两个程序带有依赖关系,可以使用工作流进行任务的设定,依赖的绑定,一起提交执行。
1.2 代码实现
1.2.1 reduce join、result sort程序
详细可见上一篇《Hadoop生态圈(二十五)- MapReduce Join操作》的 Join 案例,这里不再重复说。
1.2.2 作业流程控制类
该驱动类主要负责建立 reduce join 与 result sort 两个 ControlledJob,最终通过 JobControl 实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| public class MrJobFlow {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job1 = Job.getInstance(conf, ReduceJoinDriver.class.getSimpleName());
job1.setJarByClass(ReduceJoinDriver.class);
job1.setMapperClass(ReduceJoinMapper.class);
job1.setReducerClass(ReduceJoinReducer.class);
job1.setMapOutputKeyClass(Text.class);
job1.setMapOutputValueClass(Text.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job1, new Path("D:\\datasets\\mr_join\\input"));
FileOutputFormat.setOutputPath(job1, new Path("D:\\datasets\\mr_join\\rjout"));
ControlledJob ctrljob1 = new ControlledJob(conf);
ctrljob1.setJob(job1);
Job job2 = Job.getInstance(conf, ReduceJoinSortApp.class.getSimpleName());
job2.setJarByClass(ReduceJoinSortApp.class);
job2.setMapperClass(ReduceJoinSortApp.ReduceJoinMapper.class);
job2.setReducerClass(ReduceJoinSortApp.ReduceJoinReducer.class);
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(Text.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job2, new Path("D:\\datasets\\mr_join\\rjout"));
FileOutputFormat.setOutputPath(job2, new Path("D:\\datasets\\mr_join\\rjresult"));
ControlledJob ctrljob2 = new ControlledJob(conf);
ctrljob2.setJob(job2);
ctrljob2.addDependingJob(ctrljob1);
JobControl jobCtrl = new JobControl("myctrl");
jobCtrl.addJob(ctrljob1);
jobCtrl.addJob(ctrljob2);
Thread t = new Thread(jobCtrl);
t.start();
while(true) {
if (jobCtrl.allFinished()) {
System.out.println(jobCtrl.getSuccessfulJobList());
jobCtrl.stop();
break;
}
}
}
}
|
1.3 运行结果