
Hadoop 生态圈(十九)- HDFS 核心源码详解
前言
部分内容摘自尚硅谷、黑马等等培训资料
1. HDFS源码结构分析
1.1 IDEA导入HDFS源码工程
解压Hadoop源码在Windows某个目录下(该目录最好没有中文没有空格)。
打开 IDEA,选择Open or Import
选择 HDFS 工程打开
初次导入 IDEA 会自动根据 POM 依赖下载插件和依赖,此时静静等待即可。确保下载完成。
1.2 HDFS工程结构
hadoop-hdfs-project工程目录结构如下:

1.2.1 hadoop-hdfs
在hadoop-hdfs模块中,主要实现了网络、传输协议、JN、安全、server服务等相关功能。是 hdfs 的核心模块。并且提供了 hdfs web UI 页面功能的支撑。
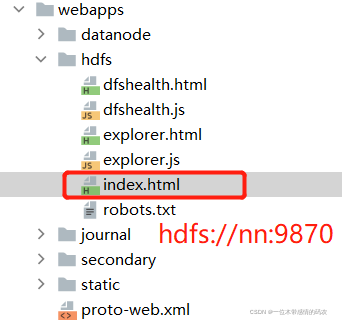
1.2.2 hadoop-hdfs-client
在hadoop-hdfs-client模块中,主要定义实现了和 hdfs 客户端相关的功能逻辑。
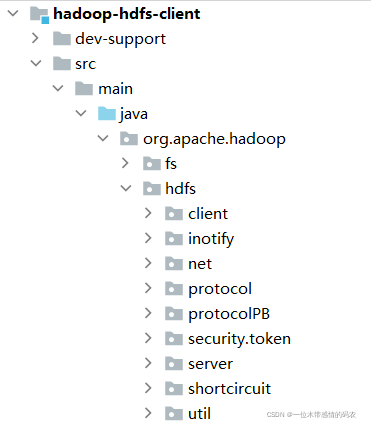
1.2.3 hadoop-hdfs-httpfs
hadoop-hdfs-httpfs模块主要实现了通过HTTP协议操作访问hdfs文件系统的相关功能。HttpFS 是一种服务器,它提供到 HDFS 的 REST HTTP 网关,具有完整的文件系统读写功能。
HttpFS 可用于在运行不同Hadoop版本的群集之间传输数据(克服 RPC 版本问题),例如使用 Hadoop DistCP。
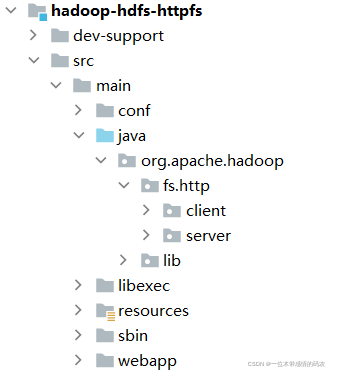
1.2.4 hadoop-hdfs-native-client
hadoop-hdfs-native-client模块定义了hdfs访问本地库的相关功能和逻辑。该模块主要是使用 C 语言进行编写,用于和本地库进行交互操作。
1.2.5 hadoop-hdfs-nfs
hadoop-hdfs-nfs模块是Hadoop HDFS的NFS实现。
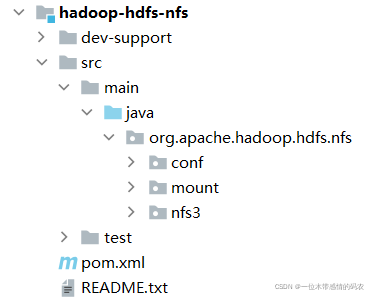
1.2.6 hadoop-hdfs-rbf
hadoop-hdfs-rbf模块是 hadoop3.0 之后的一个新的模块。主要实现了 RBF 功能。RBF 是 Router-based Federation 简称,翻译中文叫做:基于路由的 Federation 方案。
简单来说就是:HDFS 将路由信息放在了服务端来处理,而不是在客户端。以此完全做到对于客户端的透明。
2. HDFS核心源码解析
2.1 HDFS客户端核心类
2.1.1 Configuration
源码注释中对于Configuration类是这么描述的:

Configuration提供对配置参数的访问,通常称之为配置文件类。主要用于加载或者设定程序运行时相关的参数属性。
2.1.1.1 Configuration加载默认配置
在程序中打上断点,看一下新建Configuration对象的时候加载了什么:
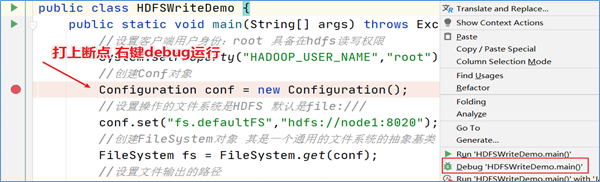
按下F7进入方法内部,再一次次按下F8,执行过程中可以发现,首先加载了静态方法和静态代码块,其中在静态代码块中显示默认加载了两个配置文件:
core-default.xml以及core-site.xml

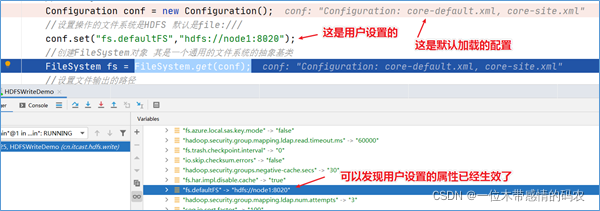
2.1.1.2 Configuration加载用户设置
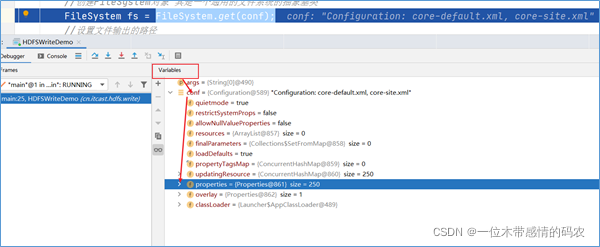
按下shift+F8,跳出Configuration类的创建,按F8执行下一步,当到达FileSystem.get(conf)这一行代码的时候,可以发现用户通过conf.set设置的属性也会被加载。
2.1.2 FileSystem
源码注释中对于FileSystem类是这么描述的:
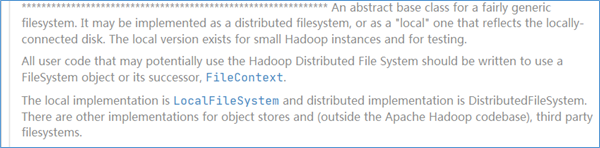
简单翻译下:FileSystem类是一个通用的文件系统的抽象基类。具体来说它可以实现为一个分布式的文件系统,也可以实现为一个本地文件系统。所有的可能会使用到 HDFS 的用户代码在进行编写时都应该使用 FileSystem 对象。
代表本地文件系统的实现是 LocalFileSystem,代表分布式文件系统的实现是DistributedFileSystem。当然针对其他 hadoop 支持的文件系统也有不同的具体实现。
因此 HDFS 客户端在进行读写操作之前,需要创建 FileSystem 对象的实例。
2.1.2.1 获取FileSystem实例
将断点达到如下的位置,debug 运行程序:
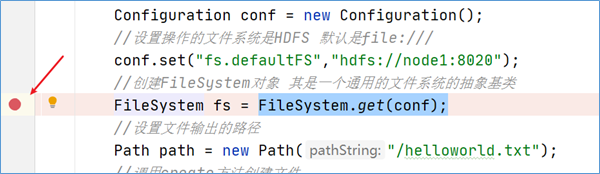
经过方法的层层调用,最终找到了FileSystem对象是通过调用getInternal方法得到的。
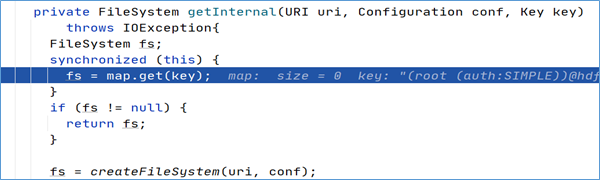
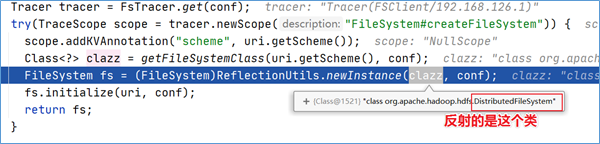
首先在getInternal方法中调用了createFileSystem方法,进去该方法:
原来,FileSystem实例是通过反射的方式获得的,具体实现是通过调用反射工具类ReflectionUtils的newInstance方法并将 class 对象以及Configuration对象作为参数传入最终得到了FileSystem实例。
2.2 HDFS通信协议
2.2.1 概述
HDFS 作为一个分布式文件系统,它的某些流程是非常复杂的(例如读、写文件等典型流程),常常涉及数据节点、名字节点和客户端三者之间的配合、相互调用才能实现。为了降低节点间代码的耦合性,提高单个节点代码的内聚性, HDFS 将这些节点间的调用抽象成不同的接口。
HDFS 节点间的接口主要有两种类型:
Hadoop RPC接口:基于 Hadoop RPC 框架实现的接口;
流式接口:基于TCP或者HTTP实现的接口;
2.2.2 Hadoop RPC接口
2.2.2.1 RPC介绍
RPC全称Remote Procedure Call——远程过程调用。就是为了解决远程调用服务的一种技术,使得调用者像调用本地服务一样方便透明。
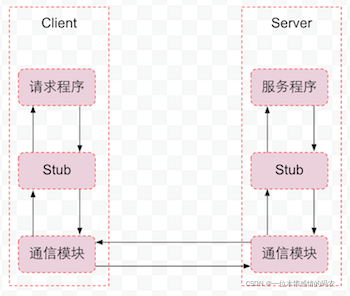
通信模块:传输 RPC 请求和响应的网络通信模块,可以基于 TCP 协议,也可以基于 UDP 协议,可以是同步,也可以是异步的。
客户端 Stub 程序:服务器和客户端都包括 Stub 程序。在客户端,Stub 程序表现的就像本地程序一样,但底层却会将调用请求和参数序列化并通过通信模块发送给服务器。之后 Stub 程序等待服务器的响应信息,将响应信息反序列化并返回给请求程序。
服务器端 Stub 程序:在服务器端,Stub 程序会将远程客户端发送的调用请求和参数反序列化,根据调用信息触发对应的服务程序,然后将服务程序返回的响应信息序列化并发回客户端。
请求程序:请求程序会像调用本地方法一样调用客户端 Stub 程序,然后接收 Stub 程序返回的响应信息。
服务程序:服务器会接收来自 Stub 程序的调用请求,执行对应的逻辑并返回执行结果。
Hadoop RPC调用使得HDFS进程能够像本地调用一样调用另一个进程中的方法,并且可以传递Java基本类型或者自定义类作为参数,同时接收返回值。如果远程进程在调用过程中出现异常,本地进程也会收到对应的异常。目前Hadoop RPC调用是基于Protobuf实现的。
Hadoop RPC 接口主要定义在org.apache.hadoop.hdfs.protocol包和org.apache.hadoop.hdfs.server.protocol包中,核心的接口有:
ClientProtocol、ClientDatanodeProtocol、DatanodeProtocol。
2.2.2.2 ClientProrocol
ClientProtocol定义了客户端与名字节点间的接口,这个接口定义的方法非常多,客户端对文件系统的所有操作都需要通过这个接口,同时客户端读、写文件等操作也需要先通过这个接口与 Namenode 协商之后,再进行数据块的读出和写入操作。
ClientProtocol 定义了所有由客户端发起的、由 Namenode 响应的操作。这个接口非常大,有 80 多个方法,核心的是:HDFS文件读相关的操作、HDFS文件写以及追加写的相关操作。
- 读数据相关的方法
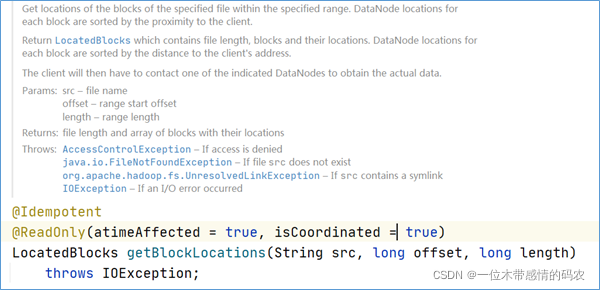
ClientProtocol 中与客户端读取文件相关的方法主要有两个: getBlockLocations()和reportBadBlocks()。
客户端会调用ClientProtocol.getBlockLocations()方法获取 HDFS 文件指定范围内所有数据块的位置信息。这个方法的参数是 HDFS 文件的文件名以及读取范围,返回值是文件指定范围内所有数据块的文件名以及它们的位置信息,使用LocatedBlocks对象封装。每个数据块的位置信息指的是存储这个数据块副本的所有 Datanode 的信息,这些 Datanode 会以与当前客户端的距离远近排序。客户端读取数据时,会首先调用getBlockLocations()方法获取 HDFS 文件的所有数据块的位置信息,然后客户端会根据这些位置信息从数据节点读取数据块。
客户端会调用ClientProtocol.reportBadBlocks()方法向 Namenode 汇报错误的数据块。当客户端从数据节点读取数据块且发现数据块的校验和并不正确时,就会调用这个方法向 Namenode 汇报这个错误的数据块信息。

- 写、追加数据相关方法
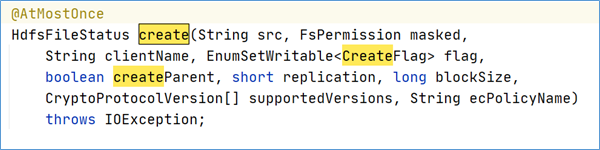
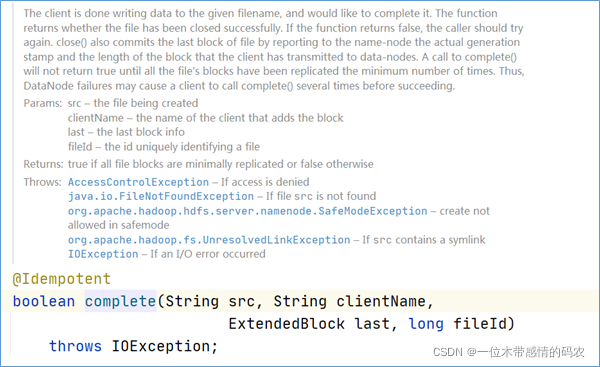
在 HDFS 客户端操作中最重要的一部分就是写入一个新的 HDFS 文件,或者打开一个已有的 HDFS 文件并执行追加写操作。ClientProtocol 中定义了 8 个方法支持 HDFS 文件的写操作: create()、 append()、 addBlock()、 complete(), abandonBlock(),getAddtionnalDatanodes()、updateBlockForPipeline()和updatePipeline()。
create()方法用于在 HDFS 的文件系统目录树中创建一个新的空文件,创建的路径由 src 参数指定。这个空文件创建后对于其他的客户端是 “可读” 的,但是这些客户端不能删除、重命名或者移动这个文件,直到这个文件被关闭或者租约过期。客户端写一个新的文件时,会首先调用create方法在文件系统目录树中创建一个空文件,然后调用addBlock方法获取存储文件数据的数据块的位置信息,最后客户端就可以根据位置信息建立数据流管道,向数据节点写入数据了。
当客户端完成了整个文件的写入操作后,会调用complete()方法通知 Namenode。这个操作会提交新写入 HDFS 文件的所有数据块,当这些数据块的副本数量满足系统配置的最小副本系数(默认值为 1),也就是该文件的所有数据块至少有一个有效副本时, complete()方法会返回true,这时 Namenode 中文件的状态也会从构建中状态转换为正常状态;否则, complete会返回false,客户端就需要重复调用complete操作,直至该方法返回true 。
2.2.2.3 ClientDatanodeProtocol
客户端与数据节点间的接口。ClientDatanodeProtocol中定义的方法主要是用于客户端获取数据节点信息时调用,而真正的数据读写交互则是通过流式接口进行的。
ClientDatanodeProtocol中定义的接口可以分为两部分:一部分是支持 HDFS 文件读取操作的,例如getReplicaVisibleLength()以及getBlockLocalPathInf();另一部分是支持DFSAdmin中与数据节点管理相关的命令。我们重点关注第一部分。
- getReplicaVisibleLength
- 客户端会调用
getReplicaVisibleLength()方法从数据节点获取某个数据块副本真实的数据长度。当客户端读取一个 HDFS 文件时,需要获取这个文件对应的所有数据块的长度,用于建立数据块的输入流,然后读取数据。但是 Namenode 元数据中文件的最后一个数据块长度与 Datanode 实际存储的可能不一致,所以客户端在创建输入流时就需要调用getReplicaVisibleLength()方法从 Datanode 获取这个数据块的真实长度。

- 客户端会调用
- getBlockLocalPathInfo
- HDFS 对于本地读取,也就是 Client 和保存该数据块的 Datanode 在同一台物理机器上时,是有很多优化的。Client 会调用
ClientProtocol.getBlockLocalPathInf()方法获取指定数据块文件以及数据块校验文件在当前节点上的本地路径,然后利用这个本地路径执行本地读取操作,而不是通过流式接口执行远程读取,这样也就大大优化了读取的性能。
- HDFS 对于本地读取,也就是 Client 和保存该数据块的 Datanode 在同一台物理机器上时,是有很多优化的。Client 会调用
2.2.2.4 DatanodeProtocol
数据节点通过这个接口与名字节点通信,同时名字节点会通过这个接口中方法的返回值向数据节点下发指令。注意,这是名字节点与数据节点通信的唯一方式。这个接口非常重要,数据节点会通过这个接口向名字节点注册、汇报数据块的全量以及增量的存储情况。同时,名字节点也会通过这个接口中方法的返回值,将名字节点指令带回该数据块,根据这些指令,数据节点会执行数据块的复制、删除以及恢复操作。
可以将DatanodeProtocol定义的方法分为三种类型: Datanode启动相关、心跳相关以及数据块读写相关。
2.2.3 基于TCP/HTTP流式接口
HDFS 除了定义 RPC 调用接口外,还定义了流式接口,流式接口是 HDFS 中基于 TCP 或者 HTTP 实现的接口。在 HDFS 中,流式接口包括了基于 TCP 的DataTransferProtocol接口,以及 HA 架构中 Active Namenode 和 Standby Namenode 之间的 HTTP 接口。
2.2.3.1 DataTransferProtocol
DataTransferProtocol是用来描述写入或者读出Datanode上数据的基于TCP的流式接口,HDFS 客户端与数据节点以及数据节点与数据节点之间的数据块传输就是基于 DataTransferProtocol 接口实现的。HDFS 没有采用 Hadoop RPC 来实现 HDFS 文件的读写功能,是因为 Hadoop RPC 框架的效率目前还不足以支撑超大文件的读写,而使用基于 TCP 的流式接口有利于批量处理数据,同时提高了数据的吞吐量。
DataTransferProtocol 中最重要的方法就是 readBlock()和writeBlock()。
- readBlock:从当前 Datanode 读取指定的数据块。
- writeBlock:将指定数据块写入数据流管道(pipeLine)中。
DataTransferProtocol 接口调用并没有使用 Hadoop RPC 框架提供的功能,而是定义了用于发送 DataTransferProtocol 请求的 Sender 类,以及用于响应 DataTransferProtocol 请求的 Receiver 类。
Sender 类和 Receiver 类都实现了 DataTransferProtocol 接口。。我们假设 DFSClient 发起了一个 DataTransferProtocol.readBlock() 操作,那么 DFSClient 会调用 Sender 将这个请求序列化,并传输给远端的 Receiver。远端的 Receiver 接收到这个请求后,会反序列化请求,然后调用代码执行读取操作。

2.3 数据写入流程分析
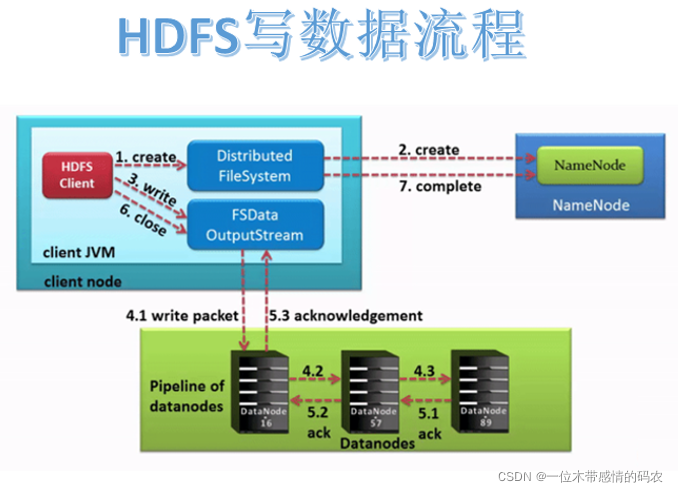
2.3.1 写入流程图
2.3.2 写入数据代码
1 | public class HDFSWriteDemo { |
2.3.3 写入数据流程梳理
2.3.3.1 客户端请求NameNode创建
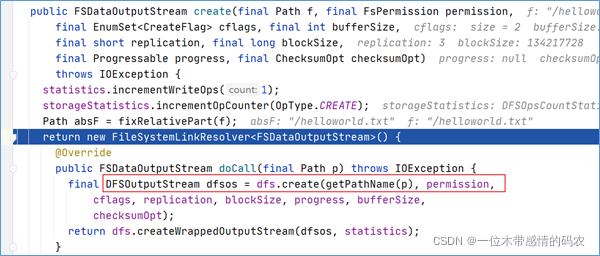
HDFS 客户端通过对DistributedFileSystem对象调用create()请求创建文件。DistributedFileSystem为客户端返回FSDataOutputStream输出流对象。通过源码注释可以发现FSDataOutputStream是一个包装类,所包装的是DFSOutputStream。
可以通过create()方法调用不断跟下去,可以发现最终的调用也验证了上述结论,返回的是DFSOutputStream。
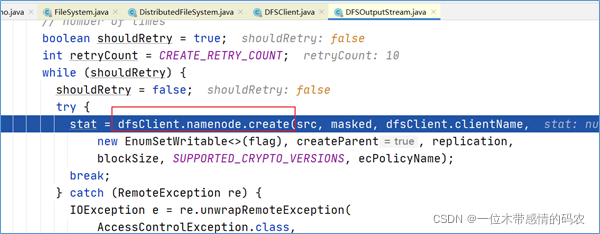
点击进入代码DFSOutputStream dfsos = dfs.create可以发现,DFSOutputStream这个类是从DFSClient类的create方法中返回过来的。
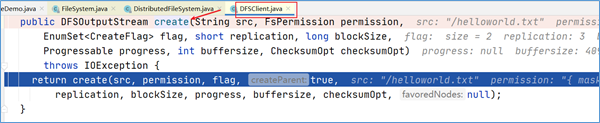
在DFSOutputStream dfsos = dfs.create打上断点,dubug。进来之后点进去发现,DFSClient类中的DFSOutputStream实例对象是通过调用DFSOutputStream类的newStreamForCreate方法产生的。
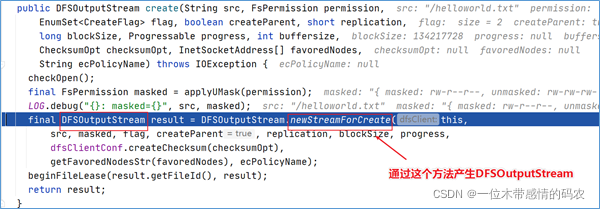
点击进入这个方法,找到了客户端请求 NameNode 新建元数据的关键代码。
2.3.3.2 NameNode执行请求检查
DistributedFileSystem对 namenode 进行RPC调用,请求上传文件。namenode 执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,namenode 就会为创建新文件记录一条记录。否则,文件创建失败并向客户端抛出一个IOException。
2.3.3.3 DataStreamer类
在之前的newStreamForCreate方法中,我们发现了最终返回的是out对象,并且在返回之前,调用了out对象的start方法。
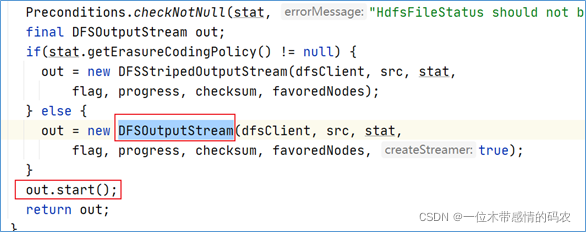
点进start方法,发现调用的是DataStreamer对象的start方法。

DataStreamer类是DFSOutputSteam的一个内部类,在这个类中,有一个方法叫做run方法,数据写入的关键代码就在这个run方法中实现。
2.3.3.4 DataStreamer写数据
在客户端写入数据时,DFSOutputStream将它分成一个个数据包(packet 默认 64kb),并写入一个称之为数据队列(data queue)的内部队列。DataStreamer请求 NameNode 挑选出适合存储数据副本的一组 DataNode。这一组 DataNode 采用pipeline机制做数据的发送。默认是 3 副本存储。
DataStreamer将数据包流式传输到pipeline的第一个 datanode,该 DataNode 存储数据包并将它发送到pipeline的第二个 DataNode。同样,第二个 DataNode 存储数据包并且发送给第三个(也是最后一个) DataNode。
DFSOutputStream也维护着一个内部数据包队列来等待 DataNode 的收到确认回执,称之为确认队列(ack queue),收到pipeline中所有 DataNode 确认信息后,该数据包才会从确认队列删除。
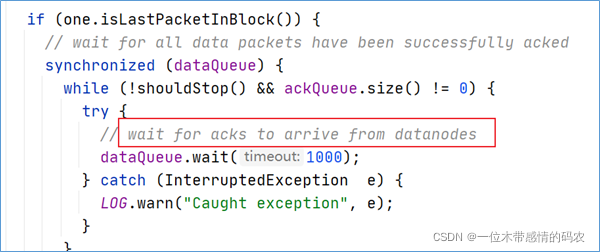
客户端完成数据写入后,将在流上调用close()方法关闭。该操作将剩余的所有数据包写入 DataNode pipeline,并在联系到 NameNode 告知其文件写入完成之前,等待确认。
因为 namenode 已经知道文件由哪些块组成(DataStream 请求分配数据块),因此它仅需等待最小复制块即可成功返回。数据块最小复制是由参数dfs.namenode.replication.min指定,默认是 1。
2.4 数据读取流程分析
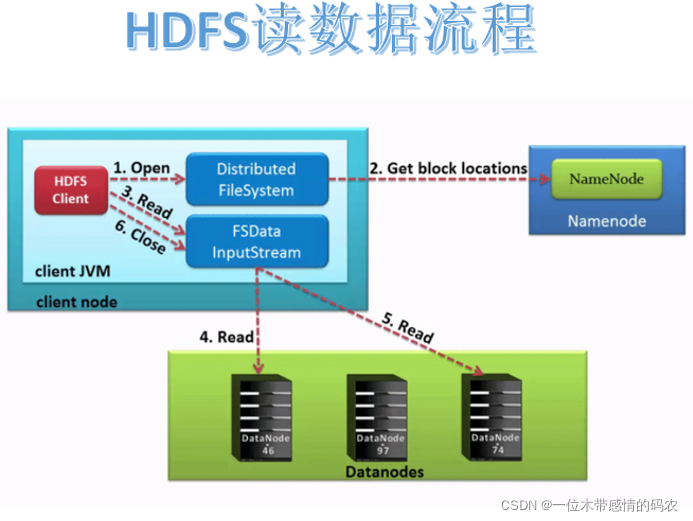
2.4.1 读取流程图
2.4.2 读取数据代码
1 | public class HDFSReadDemo { |
2.4.3 读取数据流程梳理
2.4.3.1 客户端请求NameNode打开open
客户端通过调用DistributedFileSystem对象上的open()来打开希望读取的文件。DistributedFileSystem为客户端返回FSDataInputStream输入流对象。通过源码注释可以发现FSDataInputStream是一个包装类,所包装的是DFSInputStream。
可以通过open方法调用不断跟下去,可以发现最终的调用也验证了上述结论,返回的是DFSInputStream。
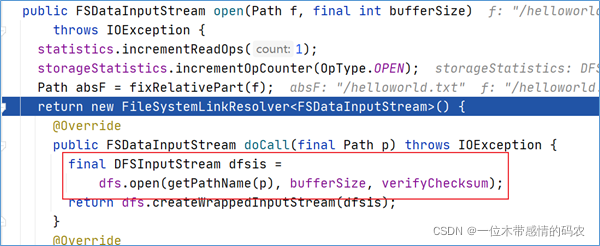
点击进入代码DFSInputStream dfsis = dfs.open()可以发现,DFSInputStream这个类是从DFSClient类的open方法中返回过来的。该输入流从 namenode 获取 block 的位置信息。
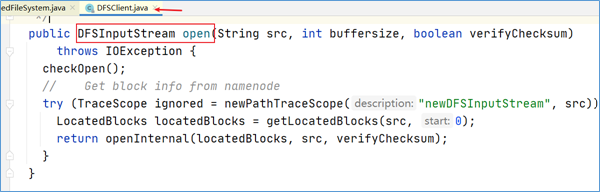
2.4.3.2 getLocatedBlocks
在上述open方法中,有一个核心方法调用叫做getLocatedBlocks,见名知意,该方法是用于获取块位置信息的。
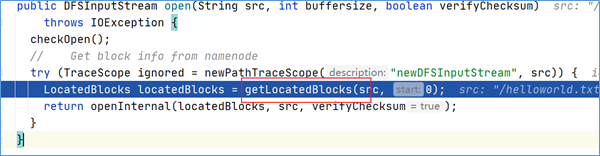
点击方法进去之后发现,最终调用的是callGetBlockLocations:
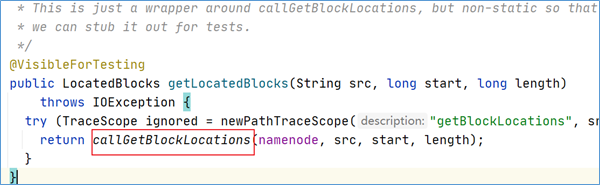
继续点下去,发现最终调用的是getBlockLocations方法。
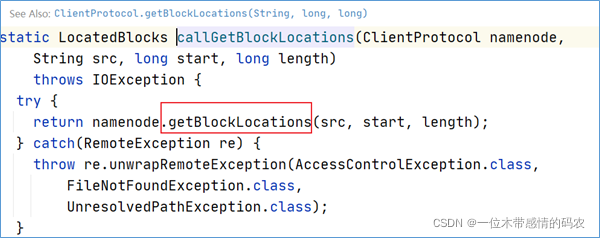
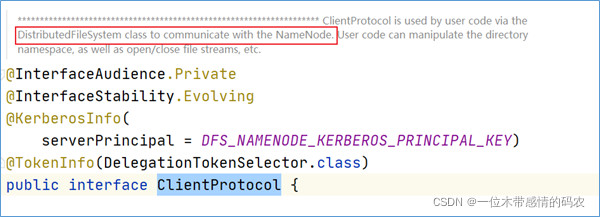
通过源码可以发现,getBlockLocations方法是位于ClientProtocol这个接口中。在ClientProtocol的注释上可以得出信息,这是客户端和 namenode 进行通信的。
2.4.3.3 NameNode返回块信息
DistributedFileSystem使用RPC调用 namenode 来确定文件中前几个块的块位置。对于每个块,namenode 返回具有该块副本的 datanode 的地址,并且 datanode 根据块与客户端的距离进行排序。注意此距离指的是网络拓扑中的距离。比如客户端的本身就是一个 DataNode,那么从本地读取数据明显比跨网络读取数据效率要高。
之前的getBlockLocations方法在源码注释上也描述了这段逻辑。
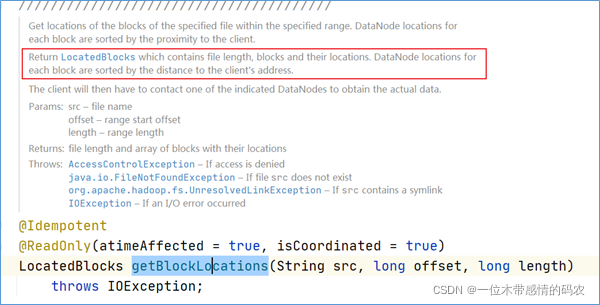
大致意思如下:获取指定范围内指定文件的块位置。 每个块的 DataNode 位置按与客户端的接近程度进行排序。返回LocatedBlocks,其中包含文件长度,块及其位置。 每个块的 DataNode 位置按到客户端地址的距离排序。然后,客户端将必须联系指示的 DataNode 之一以获得实际数据。
2.4.3.4 客户端读数据
DFSClient在获取到 block 的位置信息之后,继续调用openInternal方法。
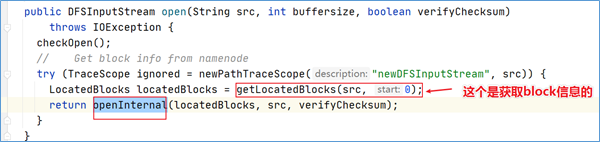
点击进入该方法可以发现,分了两种不同的输入流。这取决于文件的存储策略是否采用 EC 纠删码。如果未使用EC编码策略存储,那么直接创建DFSInputStream。
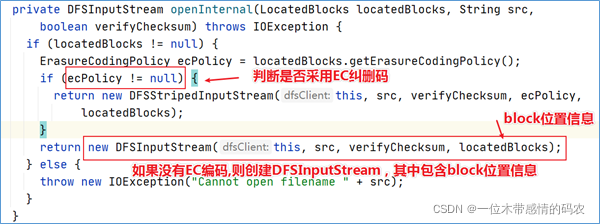
最终将 block 位置信息保存到DFSInputStream输入流对象中的成员变量中返回给客户端。
客户端在DFSInputStream流上调用read()方法。然后DFSInputStream连接到文件中第一个块的最近的 DataNode 节点。通过对数据流反复调用read()方法,将数据从 DataNode 传输到客户端。当该块快要读取结束时,DFSInputStream将关闭与该 DataNode 的连接,然后寻找下一个块的最佳 datanode。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。
客户端从流中读取数据时,也会根据需要询问 NameNode 来检索下一批数据块的 DataNode 位置信息。一旦客户端完成读取,就对FSDataInputStream调用close()方法。
如果DFSInputStream与 DataNode 通信时遇到错误,它将尝试该块的下一个最接近的 DataNode 读取数据。并将记住发生故障的 DataNode,保证以后不会反复读取该 DataNode 后续的块。此外,DFSInputStream也会通过校验和(checksum)确认从 DataNode 发来的数据是否完整。如果发现有损坏的块,DFSInputStream会尝试从其他 DataNode 读取该块的副本,也会将被损坏的块报告给 namenode 。



