
Hadoop 生态圈(十二)- HDFS 架构深入学习
前言
部分内容摘自尚硅谷、黑马等等培训资料
1. HDFS架构剖析
1.1 HDFS整体概述
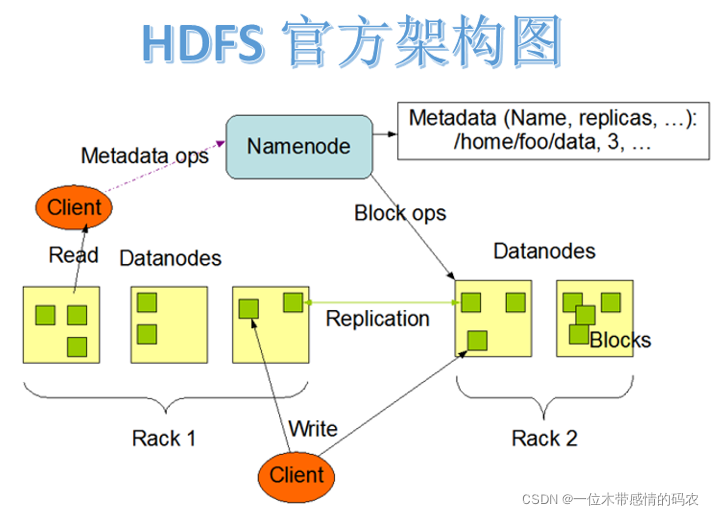
HDFS是 Hadoop Distribute File System 的简称,意为:Hadoop分布式文件系统。是 Hadoop 核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。HDFS解决的问题就是大数据如何存储,它是横跨在多台计算机上的文件存储系统并且具有高度的容错能力。
HDFS集群遵循主从架构。每个群集包括一个主节点和多个从节点。在内部,文件分为一个或多个块,每个块根据复制因子存储在不同的从节点计算机上。主节点存储和管理文件系统名称空间,即有关文件块的信息,例如块位置,权限等。从节点存储文件的数据块。主从各司其职,互相配合,共同对外提供分布式文件存储服务。当然内部细节对于用户来说是透明的。
1.2 角色介绍
1.2.1 概述
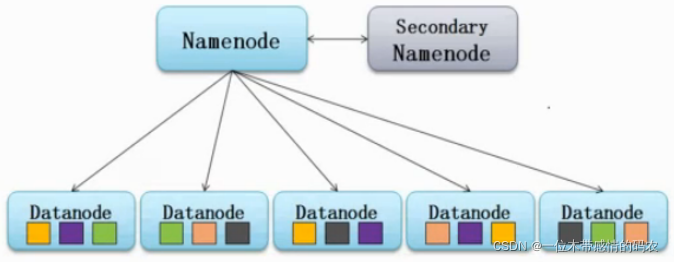
HDFS 遵循主从架构。每个群集包括一个主节点和多个从节点。其中:
NameNode是主节点,负责存储和管理文件系统元数据信息,包括 namespace 目录结构、文件块位置信息等;DataNode是从节点,负责存储文件具体的数据块。
两种角色各司其职,共同协调完成分布式的文件存储服务。
SecondaryNameNode是主角色的辅助角色,帮助主角色进行元数据的合并。
1.2.2 NameNode
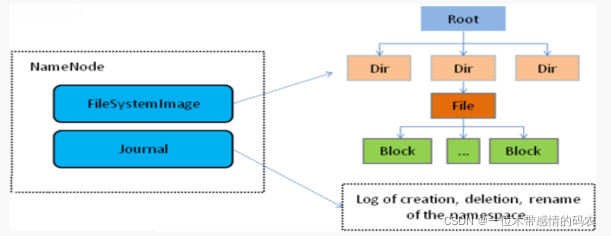
NameNode是 Hadoop 分布式文件系统的核心,架构中的主角色。它维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。基于此,NameNode成为了访问HDFS的唯一入口。
内部通过内存和磁盘两种方式管理元数据。其中磁盘上的元数据文件包括 Fsimage 内存元数据镜像文件和 edits log(Journal)编辑日志。
在 Hadoop2 之前,NameNode 是单点故障。Hadoop 2 中引入的高可用性。Hadoop 集群体系结构允许在集群中以热备配置运行两个或多个 NameNode。
1.2.3 Datanode
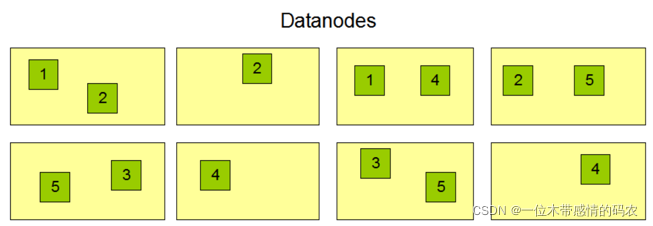
DataNode是 Hadoop HDFS 中的从角色,负责具体的数据块存储。DataNode 的数量决定了 HDFS 集群的整体数据存储能力。通过和 NameNode 配合维护着数据块。
1.2.4 Secondarynamenode
除了 DataNode 和 NameNode 之外,还有另一个守护进程,它称为secondary NameNode。充当NameNode的辅助节点,但不能替代 NameNode。
当 NameNode 启动时,NameNode 合并 Fsimage 和 edits log 文件以还原当前文件系统名称空间。如果 edits log 过大不利于加载,Secondary NameNode 就辅助 NameNode 从 NameNode 下载Fsimage文件和edits log文件进行合并。
1.3 HDFS重要特性
1.3.1 主从架构
HDFS 采用 master/slave 架构。一般一个 HDFS 集群是有一个 Namenode 和一定数目的 Datanode 组成。Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
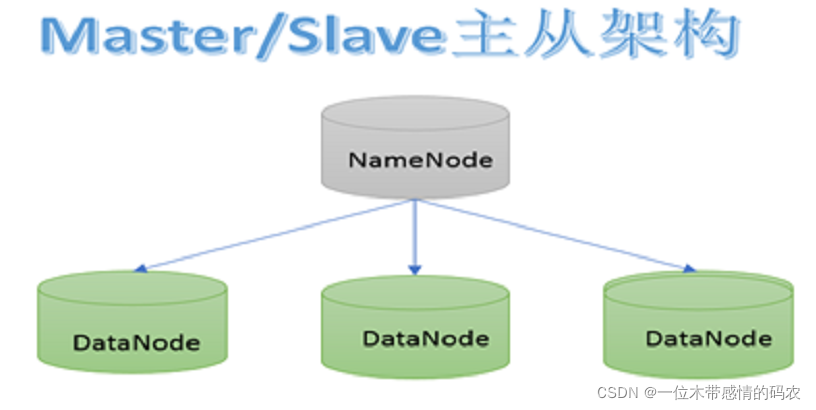
1.3.2 分块机制
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,参数位于 hdfs-default.xml 中:dfs.blocksize。默认大小在 Hadoop2.x/3.x 是128M(134217728),1.x 版本中是 64M。
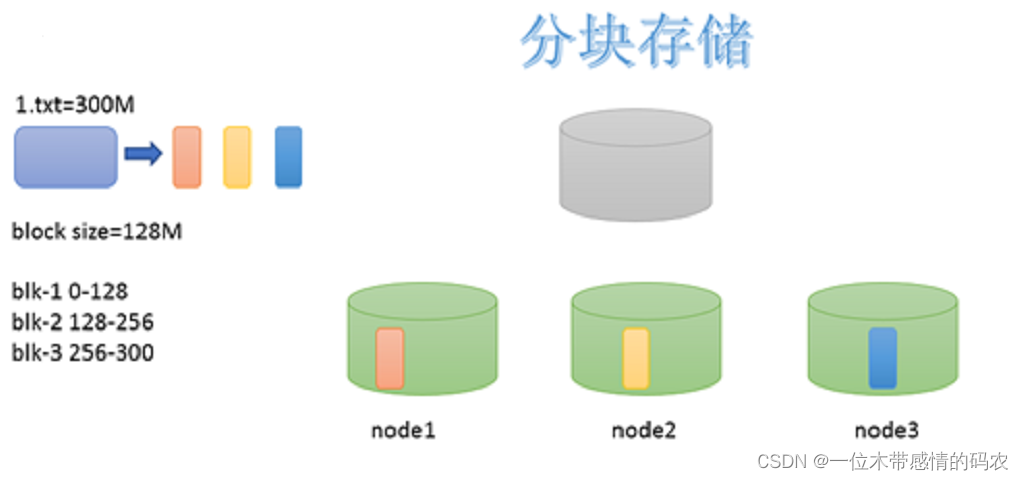
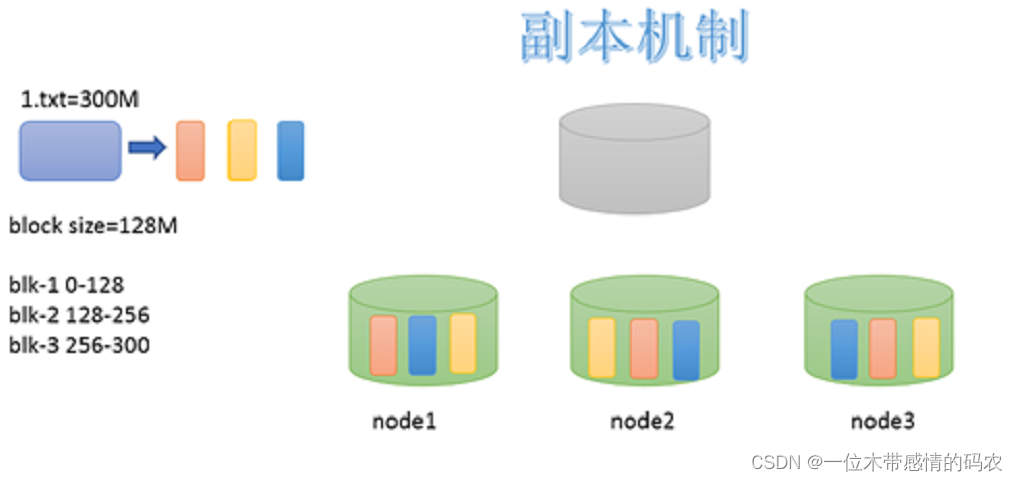
1.3.3 副本机制
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小(dfs.blocksize)和副本系数(dfs.replication)都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
默认dfs.replication的值是3,也就是会额外再复制 2 份,连同本身总共 3 份副本。
1.3.4 Namespace
HDFS 支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode 负责维护文件系统的 namespace 名称空间,任何对文件系统名称空间或属性的修改都将被 Namenode 记录下来。
HDFS 会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
1.3.5 元数据管理
在 HDFS 中,Namenode 管理的元数据具有两种类型:
文件自身属性信息- 文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
文件块位置映射信息- 记录文件块和 DataNode 之间的映射信息,即哪个块位于哪个节点上。
1.3.6 数据块存储
文件的各个 block 的具体存储管理由 DataNode 节点承担。每一个 block 都可以在多个 DataNode 上存储。
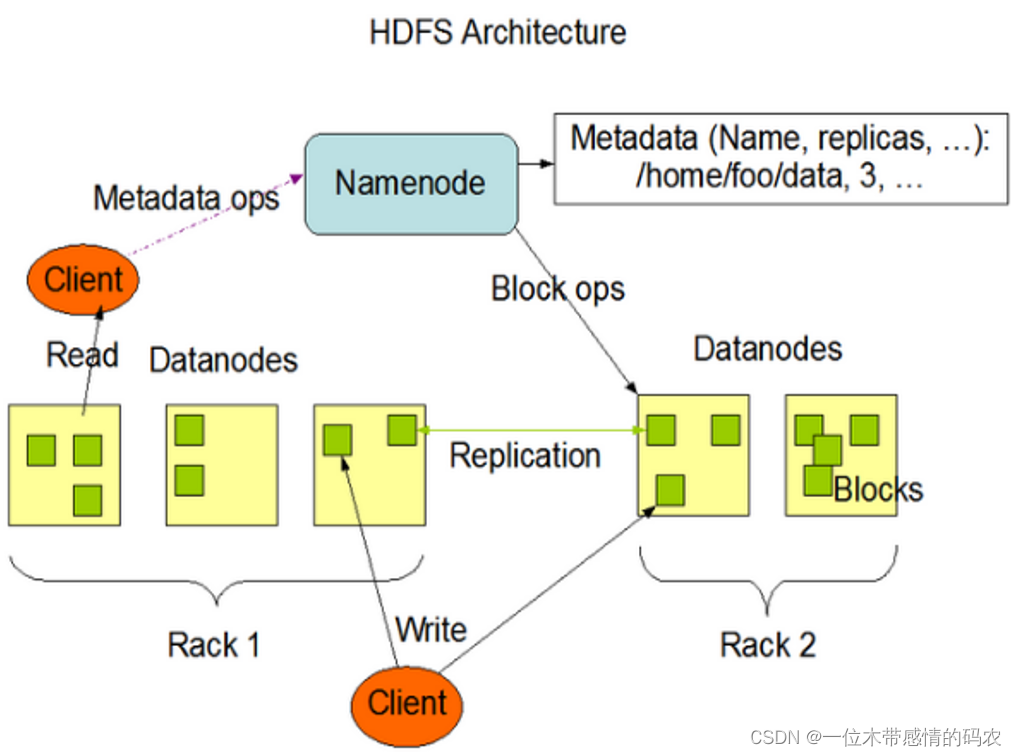
2. HDFS Web Interfaces
2.1 Web Interfaces介绍
除了命令行界面之外,Hadoop 还为 HDFS 提供了 Web 用户界面。用户可以通过 Web 界面操作文件系统并且获取和 HDFS 相关的状态属性信息。
HDFS Web 地址是 http://nn_host:port/,默认端口号9870。
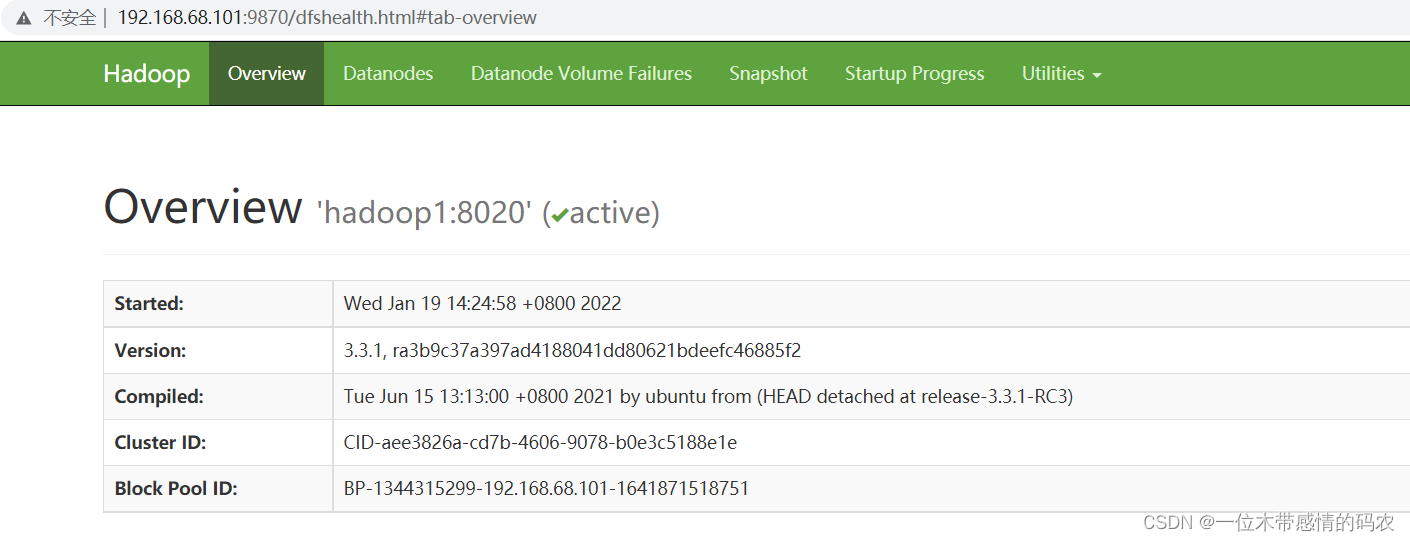
2.2 模块功能解读
2.2.1 Overview
Overview 是总揽模块,默认的主页面。展示了 HDFS 一些最核心的信息。
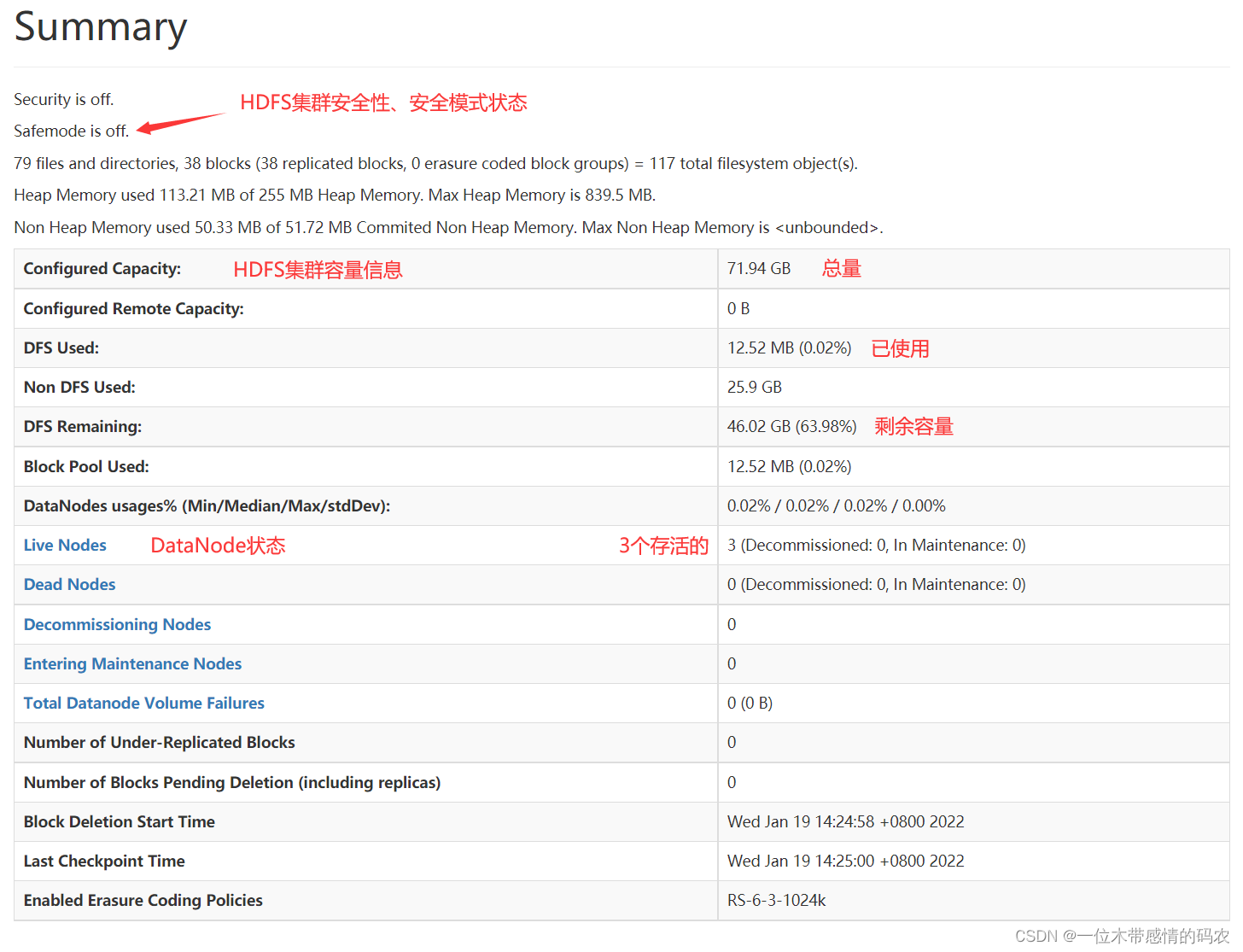
2.2.1.1 Summary
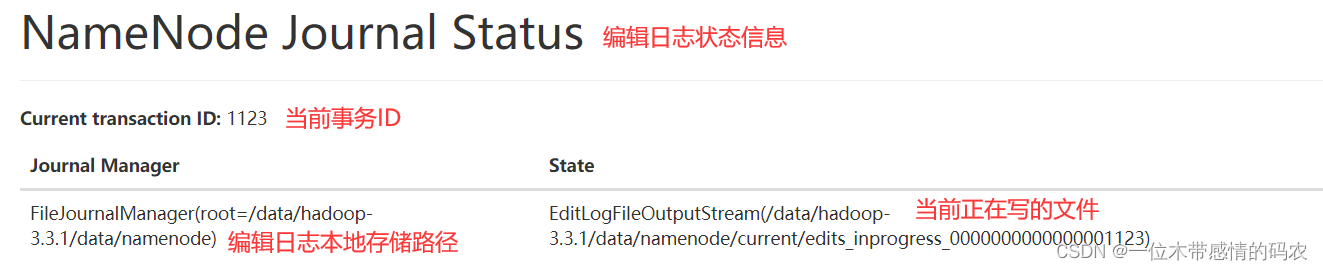
2.2.1.2 NameNode Journal Status
2.2.1.3 NameNode Storage

2.2.1.4 DFS Storage Types

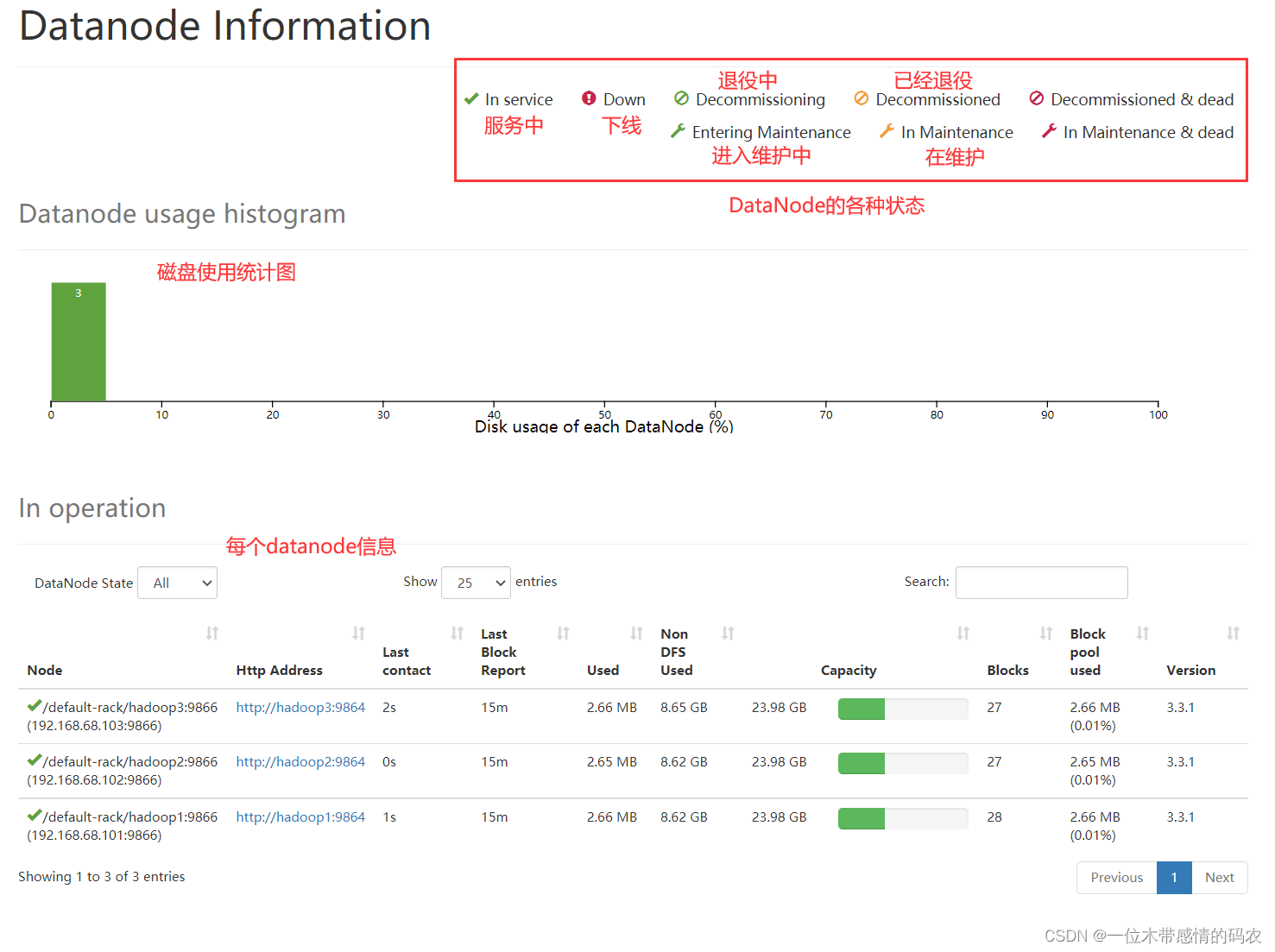
2.2.2 Datanodes
Datanodes 模块主要记录了 HDFS 集群中各个 DataNode 的相关状态信息。
2.2.3 Datanode Volume Failures
此模块记录了 DataNode 卷故障信息。

2.2.4 Snapshot
Snapshot模块记录 HDFS 文件系统的快照相关信息,包括哪些文件夹创建了快照和总共有哪些快照。
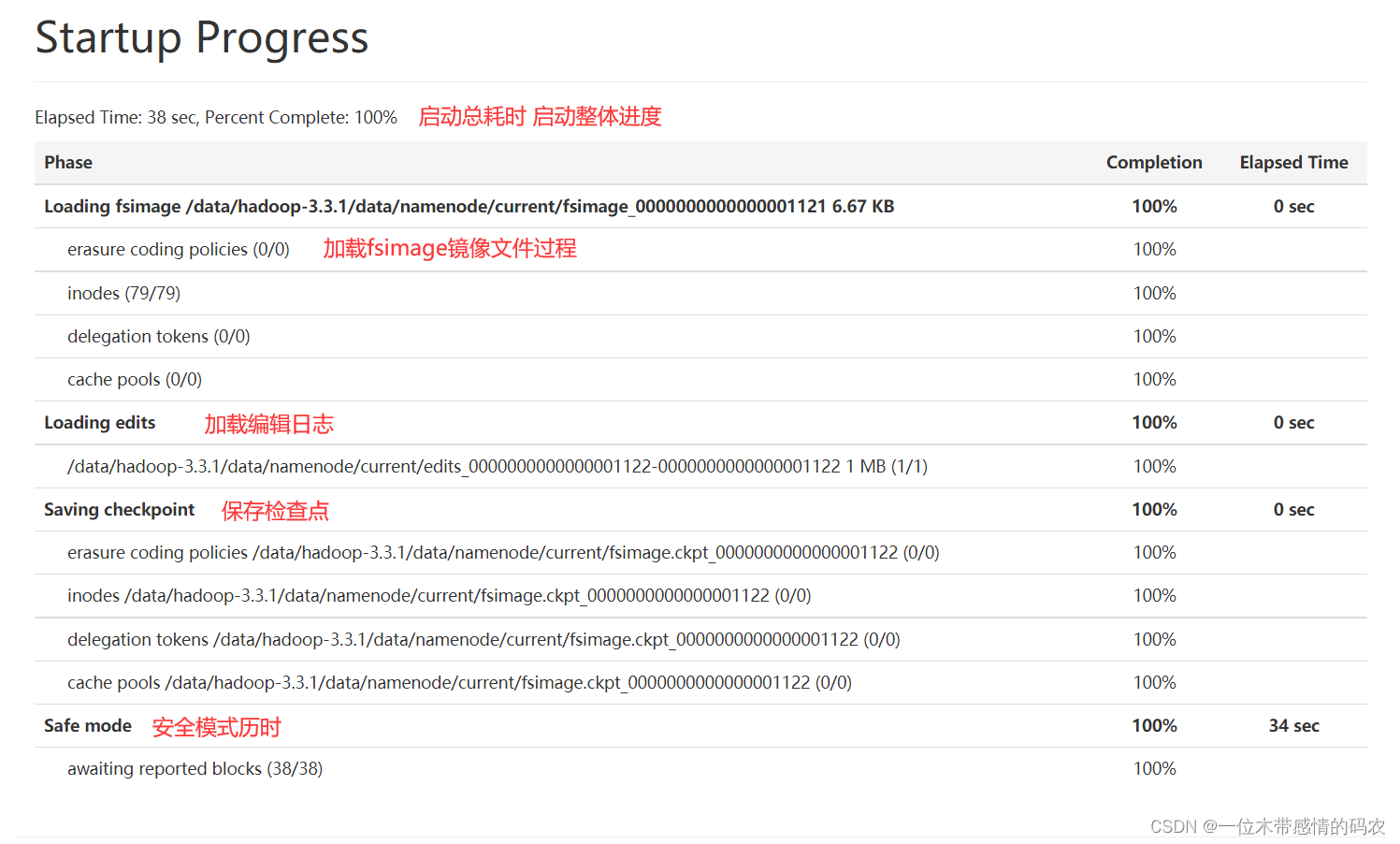
2.2.5 Satartup progress
2.2.6 Utilities
Utilities模块算是用户使用最多的模块了,里面包括了文件浏览、日志查看、配置信息查看等核心功能。
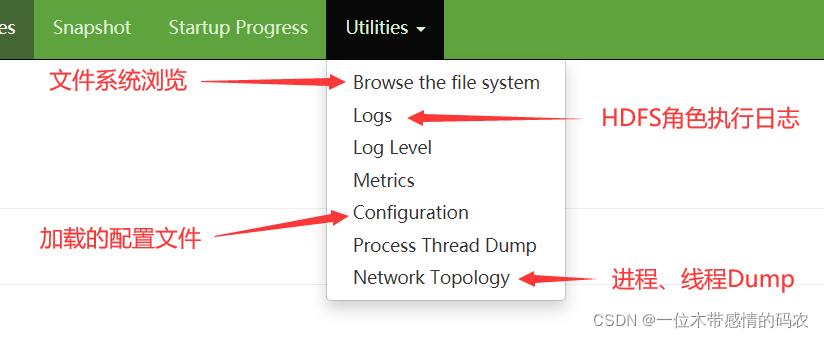
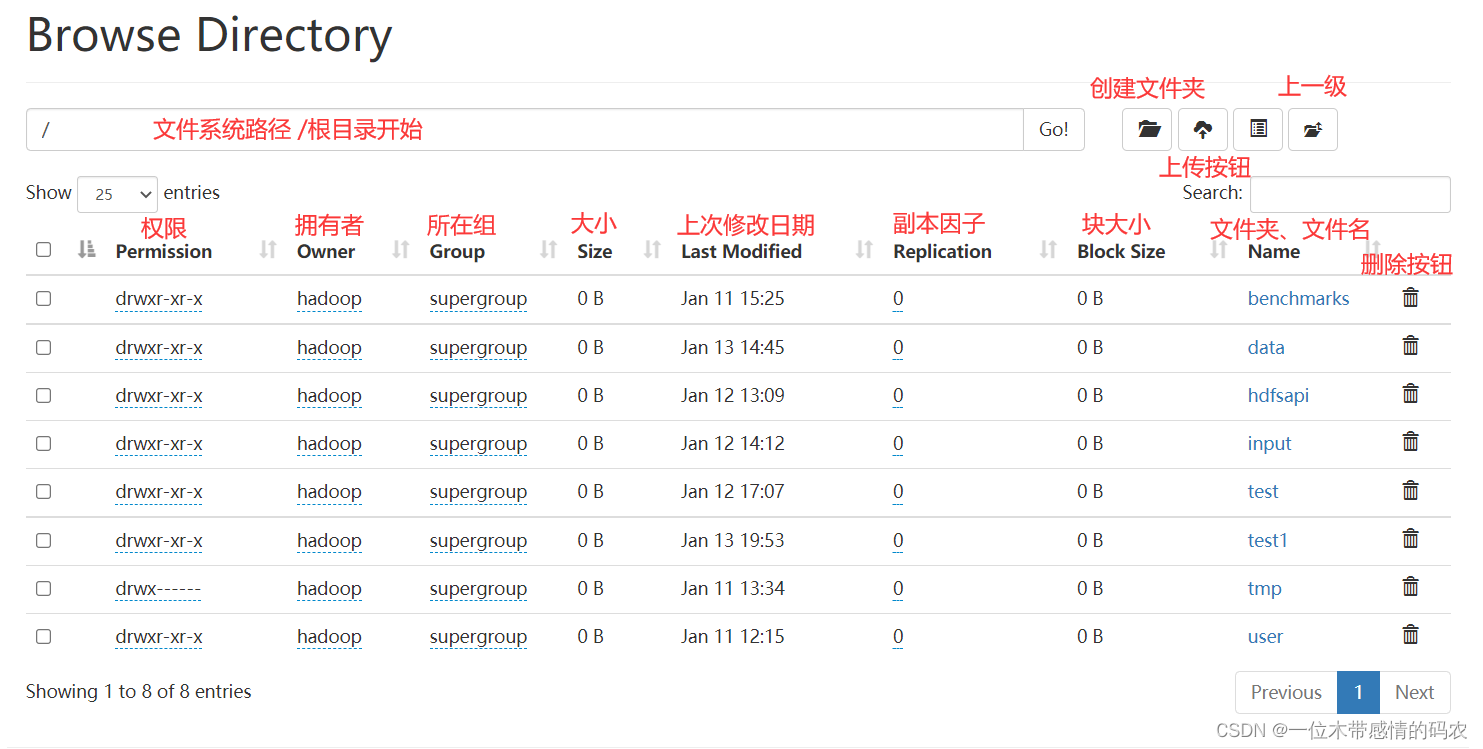
2.2.6.1 Browse the file system
该模块可以说是我们在开发使用 HDFS 过程中使用最多的模块了,提供了一种Web页面浏览操作文件系统的能力,在某些场合下,比使用命令操作更加直观方便。
2.2.6.2 Logs、Log Level
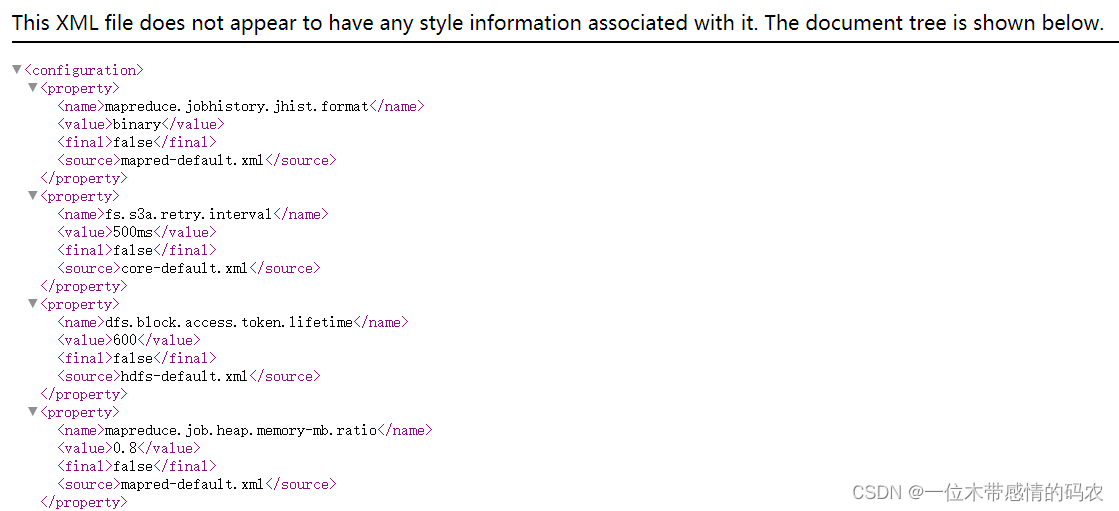
2.2.6.3 Configruation
该模块可以列出当前集群成功加载的所谓配置文件属性,可以从这里来进行判断用户所设置的参数属性是否成功加载生效,如果此处没有,需要检查配置文件或者重启集群加载。
3. HDFS读写流程
因为 namenode 维护管理了文件系统的元数据信息,这就造成了不管是读还是写数据都是基于 NameNode 开始的,也就是说NameNode成为了HDFS访问的唯一入口。入口地址是:http://nn_host:8020。
3.1 写数据流程
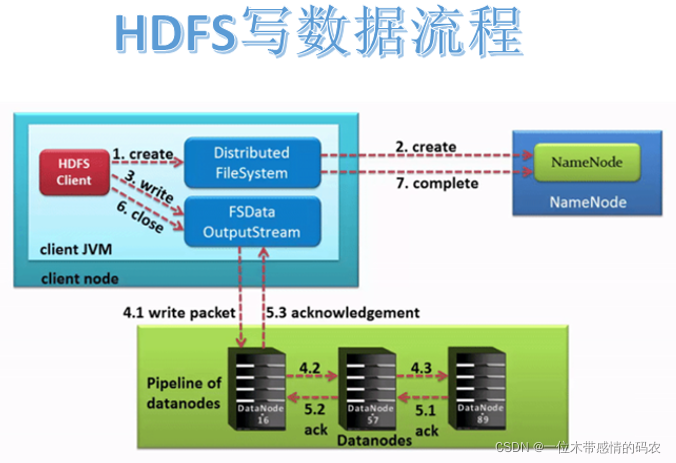
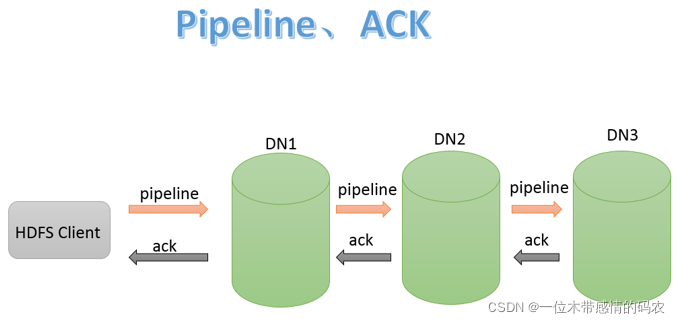
3.1.1 Pipeline管道、ACK应答响应
Pipeline,中文翻译为管道。这是 HDFS 在上传文件写数据过程中采用的一种数据传输方式。客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。通俗描述 pipeline 的过程就是:ClientABC。
为什么 datanode 之间采用 pipeline线性传输,而不是一次给三个 datanode 拓扑式传输呢?因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带。
ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。在 pipeline 管道传输数据的过程中,传输的反方向会进行 ACK 校验,确保数据传输安全。
3.1.2 具体流程
- HDFS 客户端通过对 DistributedFileSystem 对象调用
create()请求创建文件。 - DistributedFileSystem 对 namenode进行
RPC调用,请求上传文件。namenode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,namenode 就会为创建新文件记录一条记录。否则,文件创建失败并向客户端抛出一个 IOException。 - DistributedFileSystem 为客户端返回 FSDataOutputStream 输出流对象。由此客户端可以开始写入数据。FSDataOutputStream 是一个包装类,所
包装的是DFSOutputStream。 - 在客户端写入数据时,DFSOutputStream 将它分成一个个数据包(
packet默认 64kb),并写入一个称之为数据队列(data queue)的内部队列。DFSOutputStream 有一个内部类做 DataStreamer,用于请求 NameNode 挑选出适合存储数据副本的一组 DataNode。这一组 DataNode 采用pipeline机制做数据的发送。默认是 3 副本存储。 - DataStreamer 将数据包流式传输到 pipeline 的第一个 datanode,该 DataNode 存储数据包并将它发送到 pipeline 的第二个 DataNode。同样,第二个 DataNode 存储数据包并且发送给第三个(也是最后一个)DataNode。
- DFSOutputStream 也维护着一个内部数据包队列来等待 DataNode 的收到确认回执,称之为
确认队列(ack queue),收到 pipeline 中所有 DataNode 确认信息后,该数据包才会从确认队列删除。 - 客户端完成数据写入后,将在流上调用 close() 方法关闭。该操作将剩余的所有数据包写入 DataNode pipeline,并在联系到 NameNode 告知其文件写入完成之前,等待确认。
- 因为 namenode 已经知道文件由哪些块组成(DataStream 请求分配数据块),因此它仅需等待最小复制块即可成功返回。
- 数据块最小复制是由参数
dfs.namenode.replication.min指定,默认是1。
3.1.3 默认3副本存储策略
默认副本存储策略是由BlockPlacementPolicyDefault指定。策略如下:
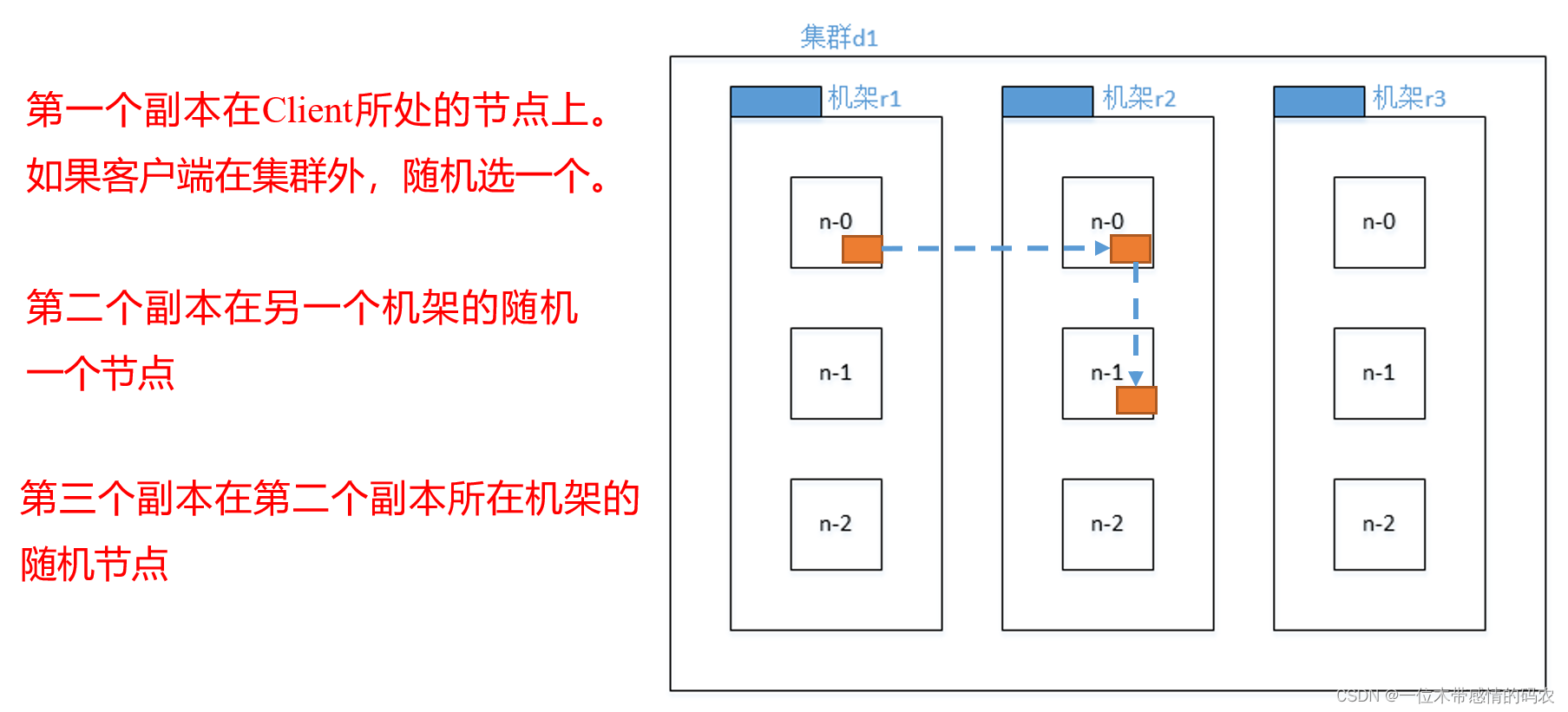
3.1.4 网络拓扑——节点距离计算
在 HDFS 写数据的过程中,NameNode 会选择距离待上传数据最近距离的 DataNode 接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
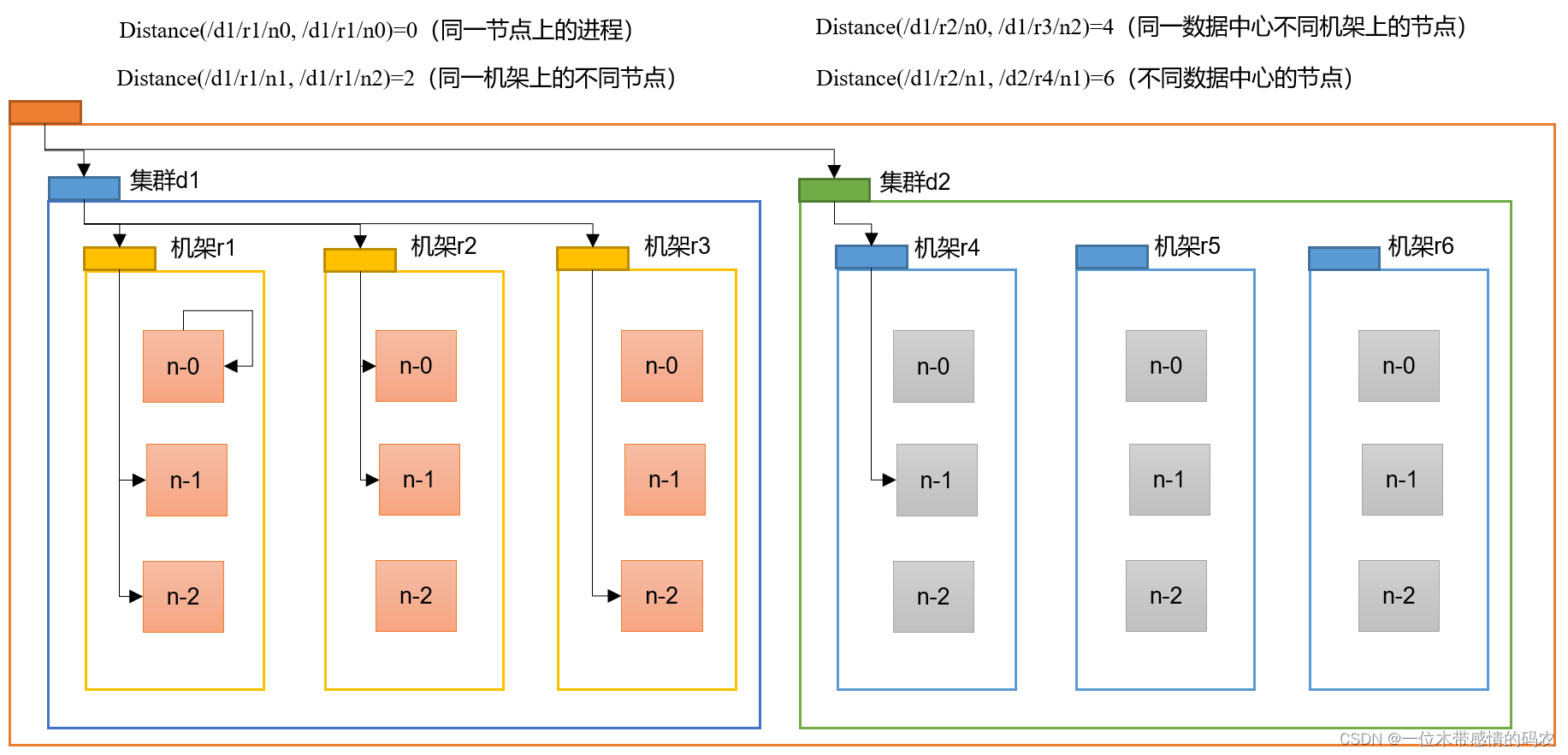
例如,假设有数据中心 d1 机架 r1 中的节点 n1。该节点可以表示为 /d1/r1/n1。利用这种标记,这里给出四种距离描述。
3.2 读数据流程
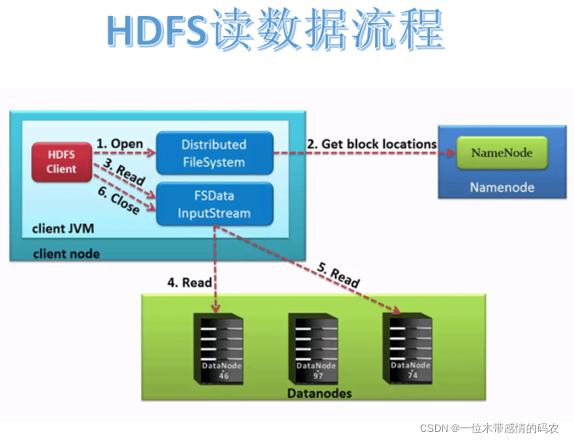
3.2.1 具体流程
- 客户端通过调用 DistributedFileSystem 对象上的 open() 来打开希望读取的文件。
- DistributedFileSystem 使用
RPC调用namenode 来确定文件中前几个块的块位置。对于每个块,namenode 返回具有该块副本的 datanode 的地址,并且 datanode 根据块与客户端的距离进行排序。注意此距离指的是网络拓扑中的距离。比如客户端的本身就是一个 DataNode,那么从本地读取数据明显比跨网络读取数据效率要高。 - DistributedFileSystem 将
FSDataInputStream(支持文件seek定位读的输入流)返回到客户端以供其读取数据。FSDataInputStream 类转而封装为 DFSInputStream 类,DFSInputStream 管理着 datanode 和 namenode 之间的 IO。 - 客户端在流上调用 read() 方法。然后,已存储着文件前几个块 DataNode 地址的 DFSInputStream 随即连接到文件中第一个块的最近的 DataNode 节点。通过对数据流反复调用 read() 方法,可以将数据从 DataNode 传输到客户端。
- 当该块快要读取结束时,DFSInputStream 将关闭与该 DataNode 的连接,然后寻找下一个块的最佳 datanode。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。
- 客户端从流中读取数据时,块是按照打开 DFSInputStream 与 DataNode 新建连接的顺序读取的。它也会根据需要询问 NameNode 来检索下一批数据块的 DataNode 位置信息。一旦客户端完成读取,就对 FSDataInputStream 调用 close() 方法。
- 如果 DFSInputStream 与 DataNode 通信时遇到错误,它将尝试该块的下一个最接近的 DataNode 读取数据。并将记住发生故障的 DataNode,保证以后不会反复读取该 DataNode 后续的块。此外,DFSInputStream 也会通过校验和(checksum)确认从 DataNode 发来的数据是否完整。如果发现有损坏的块,DFSInputStream 会尝试从其他 DataNode 读取该块的副本,也会将被损坏的块报告给 namenode 。
3.3 角色职责概述
3.3.1 Namenode职责
- NameNode 是 HDFS 的核心,集群的主角色,被称为 Master。
- NameNode 仅存储管理 HDFS 的元数据:文件系统 namespace 操作维护目录树,文件和块的位置信息。
- NameNode 不存储实际数据或数据集。数据本身实际存储在 DataNodes 中。
- NameNode 知道 HDFS 中任何给定文件的块列表及其位置。使用此信息 NameNode 知道如何从块中构建文件。
- NameNode 并不持久化存储每个文件中各个块所在的 DataNode 的位置信息,这些信息会在系统启动时从 DataNode 汇报中重建。
- NameNode 对于 HDFS 至关重要,当 NameNode 关闭时,HDFS / Hadoop 集群无法访问。
- NameNode 是 Hadoop 集群中的单点故障。
- NameNode 所在机器通常会配置有大量内存(RAM)。
3.3.2 Datanode职责
- DataNode 负责将实际数据存储在 HDFS 中。是集群的从角色,被称为 Slave。
- DataNode 启动时,它将自己发布到 NameNode 并汇报自己负责持有的块列表。
- 根据 NameNode 的指令,执行块的创建、复制、删除操作。
- DataNode 会定期(
dfs.heartbeat.interval配置项配置,默认是 3 秒)向 NameNode 发送心跳,如果 NameNode 长时间没有接受到 DataNode 发送的心跳, NameNode 就会认为该 DataNode 失效。 - DataNode 会定期向 NameNode 进行自己持有的数据块信息汇报,汇报时间间隔取参数
dfs.blockreport.intervalMsec,参数未配置的话默认为 6 小时。 - DataNode 所在机器通常配置有大量的硬盘空间。因为实际数据存储在 DataNode 中。



