
Hadoop 生态圈(五)- HDFS 数据迁移解决方案
前言
部分内容摘自尚硅谷、黑马等等培训资料
1. HDFS数据迁移解决方案
数据迁移指的是一种大规模量级的数据转移,转移的过程中往往会跨机房、跨集群 ,数据迁移规模的不同会导致整个数据迁移的周期也不尽相同 。
在 HDFS 中,同样有许多需要数据迁移的场景,比如冷热数据集群之间的数据转化, 或者 HDFS 数据的双机房备份等等 。因为涉及跨机房 、跨集群,所以数据迁移不会是一个简单的操作。
1.1 数据迁移使用场景
- 冷热集群数据同步、分类存储
- 集群数据整体搬迁
- 当公司的业务迅速的发展,导致当前的服务器数量资源出现临时紧张的时候,为了更高效的利用资源,会将原 A 机房数据整体迁移到 B 机房的,原因可能是 B 机房机器多,而且 B 机房本身开销较 A 机房成本低些等;
- 数据的准实时同步
- 数据准实时同步的目的在于数据的双备份可用,比如某天 A 集群突然宣告不允许再使用了,此时可以将线上使用集群直接切向 B 的同步集群,因为 B 集群实时同步 A 集群数据,拥有完全一致的真实数据和元数据信息,所以对于业务方使用而言是不会受到任何影响的。
1.2 数据迁移要素考量
- Bandwidth——带宽
- 带宽用的多了,会影响到线上业务的任务运行,带宽用的少了又会导致数据同步过慢的问题。
- Performance——性能
- 是采用简单的单机程序?还是多线程的性能更佳的分布式程序?
- Data-Increment——增量同步
- 当 TB,PB 级别的数据需要同步的时候,如果每次以全量的方式去同步数据,结果一定是非常糟糕。如果仅针对变化的增量数据进行同步将会是不错的选择。可以配合 HDFS 快照等技术实现增量数据同步。
- Syncable——数据迁移的同步性
- 数据迁移的过程中需要保证周期内数据是一定能够同步完的,不能差距太大。比如 A 集群 7 天内的增量数据,我只要花半天就可以完全同步到 B 集群,然后我又可以等到下周再次进行同步。最可怕的事情在于 A 集群的 7 天内的数据,我的程序花了 7 天还同步不完,然后下一个周期又来了,这样就无法做到准实时的一致性。其实 7 天还是一个比较大的时间,最好是能达到按天同步。
1.3 HDFS分布式拷贝工具:DistCp
1.3.1 DsitCp介绍
DistCp 是 Apache Hadoop 中的一种流行工具,在 hadoop-tools 工程下,作为独立子工程存在。其定位就是用于数据迁移的,定期在集群之间和集群内部备份数据。(在备份过程中,每次运行 DistCp 都称为一个备份周期)尽管性能相对较慢,但它的普及程度已经越来越高。
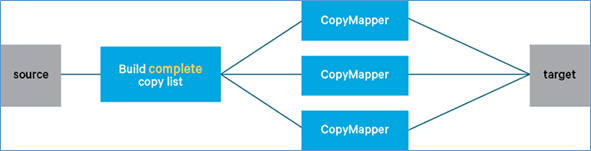
DistCp底层使用MapReduce在群集之间或并行在同一群集内复制文件。执行复制的MapReduce只有mapper阶段。 它涉及两个步骤:
- 构建要复制的文件列表(称为复制列表)
- 运行 MapReduce 作业以复制文件,并以复制列表为输入。
1.3.2 DsitCp特性
- 带宽限流
- DistCp 可以通过命令参数 bandwidth 来为程序进行带宽限流。
- 增量数据同步
- 在 DistCp 中可以通过 update 、append 和 diff 这 3 个参数实现增量同步。
- Update 解决了新增文件、目录的同步;Append 解决己存在文件的增量更新同步;Diff 解决删除或重命名类型文件的同步。
| Update | 只拷贝不存在的文件或者目录 |
| Append | 追加写目标路径下己存在的文件 |
| Diff | 通过快照的diff对比信息来同步源端路径与目标路径 |
- 高效的性能:分布式特性
- DistCp 底层使用 MapReduce 执行数据同步,MapReduce 本身是一类分布式程序。
1.3.3 DistCp命令
1 | # hadoop distcp |
其中 source_path 、target_path 需要带上地址前缀以区分不同的集群,例如 :hadoop distcp hdfs://nn1:8020/foo/a hdfs://nn2:8020/bar/foo
上面的命令表示从nn1集群拷贝/foo/a路径下的数据到nn2集群的/bar/foo路径下。
此文章版权归 程序园 所有,如有转载,请注明来自原作者。
相关推荐

评论
ValineDisqus


