前言
Hadoop搭建时最好重新编译源码,因为Hadoop的某些功能,必须通过JNT来协调Java类文件和Native代码生成的库文件一起才能工作。linux系统要运行Native代码,首先要将Native编译成目标CPU架构的[.so]文件。而不同的处理器架构,需要编译出相应平台的动态库[.so] 文件,才能被正确的执行,所以最好重新编译一次Hadoop源码,让[.so]文件与自己处理器相对应。Hadoop3.x在centos上的完全分布式部署
1. 环境准备
三台虚拟机,192.168.68.111、192.168.68.112、192.168.68.113《win10下VMware15安装CentOS7虚拟机》
JDK(自行准备)
hadoop安装包(官网下载地址:https://hadoop.apache.org/releases.html )
编译安装所需安装包,需要自取:https://pan.baidu.com/s/11adzPBvnq0louRr3qUhfoA
2. 创建用户
创建hadoop用户,并修改hadoop用户的密码
1 2 [root@localhost hadoop-3.3.1]# useradd hadoop [root@localhost hadoop-3.3.1]# passwd hadoop
vim /etc/sudoers配置 hadoop 用户具有 root 权限,方便后期加 sudo 执行 root 权限的命令,在 %whieel 这行下面添加一行,如下所示:
1 2 %wheel ALL=(ALL) ALL hadoop ALL=(ALL) ALL
修改/data目录所有者和所属组
1 chown -R hadoop:hadoop /data/
三台虚拟机依次添加地址映射
1 2 3 4 5 vim /etc/hosts 将下面三行加入文件末尾 192.168.68.111 hadoop1 192.168.68.112 hadoop2 192.168.68.113 hadoop3
关闭防火墙(生产不能这么搞,生产开通几个指定端口即可)
1 2 3 firewall-cmd --state #查看防火墙状态 systemctl stop firewalld.service #停止firewalld服务 systemctl disable firewalld.service #开机禁用firewalld服务
3. 免密登录
到/home/hadoop/.ssh/目录下,使用 hadoop 用户执行ssh-keygen -t rsa,然后回车三次,会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
执行下面的命令将公钥拷贝到要免密登录的机器上,在另外两台机器上一次重复这两个步骤
1 2 3 ssh-copy-id 192.168.68.111 ssh-copy-id 192.168.68.112 ssh-copy-id 192.168.68.113
现在三台机器的 hadoop 用户就可以免密登录了,再添加一个192.168.68.111的 root 用户免密登录到另外两台机器,用192.168.68.111的 root 用户,执行下面的命令
1 2 3 4 5 6 cd ~ cd .ssh ssh-keygen -t rsa ssh-copy-id 192.168.68.111 ssh-copy-id 192.168.68.112 ssh-copy-id 192.168.68.113
.ssh文件夹下的文件功能解释
文件名
功能
known_hosts
记录ssh访问过计算机的公钥(public key)
id_rsa
生成的私钥
id_rsa.pub
生成的公钥
authorized_keys
存放授权过的无密登录服务器公钥
4. 编译安装
先使用root用户安装编译相关的依赖
1 2 3 4 5 yum install -y gcc gcc-c++ yum install -y make cmake yum install -y autoconf automake libtool curl yum install -y lzo-devel zlib-devel openssl openssl-devel ncurses-devel yum install -y snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop libXtst
手动安装cmake,默认安装的 cmake 版本太低,源码无法编译,推荐 3.6 版本以上的,我这里是 3.13 版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 卸载已安装的cmake yum erase cmake # 上传安装包,并解压 tar -zxvf cmake-3.13.5.tar.gz -C /data/ # 编译安装 cd /data/cmake-3.13.5/ ./configure make && make install # 验证 [root@localhost cmake-3.13.5]# cmake -version cmake version 3.13.5 #如果没有正确显示版本,可以断开ssh连接,重新登录查看
手动安装snappy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 卸载已经安装的snappy cd /usr/local/lib rm -rf libsnappy* # 上传解压 cd /data/soft/ tar -zxvf snappy-1.1.3.tar.gz -C /data/ # 编译安装 cd /data/snappy-1.1.3/ ./configure make && make install # 验证是否安装 [root@localhost snappy-1.1.3]# ls -lh /usr/local/lib | grep snappy -rw-r--r--. 1 root root 511K Jan 14 13:07 libsnappy.a -rwxr-xr-x. 1 root root 955 Jan 14 13:07 libsnappy.la lrwxrwxrwx. 1 root root 18 Jan 14 13:07 libsnappy.so -> libsnappy.so.1.3.0 lrwxrwxrwx. 1 root root 18 Jan 14 13:07 libsnappy.so.1 -> libsnappy.so.1.3.0 -rwxr-xr-x. 1 root root 253K Jan 14 13:07 libsnappy.so.1.3.0
安装配置maven
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 # 解压安装 cd /data/soft/ tar -zxvf apache-maven-3.5.4-bin.tar.gz -C /data/ # 配置环境变量 vim /etc/profile # MAVEN_HOME export MAVEN_HOME=/data/apache-maven-3.5.4 export MAVEN_OPTS="-Xms4096m -Xmx4096m" export PATH=:$MAVEN_HOME/bin:$PATH # 验证是否安装成功 [root@localhost apache-maven-3.5.4]# mvn -v Apache Maven 3.5.4 (1edded0938998edf8bf061f1ceb3cfdeccf443fe; 2018-06-18T02:33:14+08:00) Maven home: /data/apache-maven-3.5.4 Java version: 1.8.0_211, vendor: Oracle Corporation, runtime: /usr/java/jdk1.8.0_211/jre Default locale: en_US, platform encoding: UTF-8 OS name: "linux", version: "3.10.0-957.el7.x86_64", arch: "amd64", family: "unix" # 添加maven阿里云仓库地址 vim /data/apache-maven-3.5.4/conf/settings.xml <mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors>
安装ProtocolBuffer 2.5.0
1 2 3 4 5 6 7 8 9 10 11 12 # 解压 cd /data/soft/ tar -zxvf protobuf-2.5.0.tar.gz -C /data/ # 编译安装 cd /data/protobuf-2.5.0/ ./configure make && make install # 验证是否安装成功 [root@localhost protobuf-2.5.0]# protoc --version libprotoc 2.5.0
将安装包上传到虚拟机
执行命令tar -zxvf hadoop-3.3.1.tar.gz -C /data/解压到/data目录下
编译 hadoop(编译很慢,需要一个小时左右)
1 2 3 4 5 6 7 8 9 cd /data/hadoop-3.3.1-src/ mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib #参数说明: Pdist,native :把重新编译生成的hadoop动态库; DskipTests :跳过测试 Dtar :最后把文件以tar打包 Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】 Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径
编译成功之后,安装包路径如下
1 2 3 4 5 6 7 8 9 10 11 [root@hadoop111 target]# pwd /data/hadoop-3.3.1-src/hadoop-dist/target [root@hadoop111 target]# ll total 501664 drwxr-xr-x. 2 root root 28 Jan 14 16:56 antrun drwxr-xr-x. 3 root root 22 Jan 14 16:56 classes drwxr-xr-x. 10 root root 215 Jan 14 16:56 hadoop-3.3.1 -rw-r--r--. 1 root root 513703809 Jan 14 16:56 hadoop-3.3.1.tar.gz drwxr-xr-x. 3 root root 22 Jan 14 16:56 maven-shared-archive-resources drwxr-xr-x. 3 root root 22 Jan 14 16:56 test-classes drwxr-xr-x. 2 root root 6 Jan 14 16:56 test-dir
解压编译后的安装包
1 tar -zxvf hadoop-3.3.1.tar.gz -C /data/
进入/data/hadoop-3.3.1/etc/hadoop路径,执行命令vim core-site.xml,编辑核心配置文件,添加以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://192.168.68.111:8020</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /data/hadoop-3.3.1/data/tmp</value > </property > <property > <name > hadoop.http.staticuser.user</name > <value > hadoop</value > </property > </configuration >
执行命令vim hdfs-site.xml,编辑 HDFS 配置文件,添加以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > dfs.namenode.name.dir</name > <value > /data/hadoop-3.3.1/data/namenode</value > </property > <property > <name > dfs.datanode.data.dir</name > <value > /data/hadoop-3.3.1/data/datanode</value > </property > <property > <name > dfs.namenode.http-address</name > <value > 192.168.68.111:9870</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > 192.168.68.113:9868</value > </property > </configuration >
执行命令vim yarn-site.xml编辑 YARN 配置文件,添加以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 <?xml version="1.0" ?> <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.resourcemanager.hostname</name > <value > 192.168.68.112</value > </property > <property > <name > yarn.scheduler.minimum-allocation-mb</name > <value > 512</value > </property > <property > <name > yarn.scheduler.maximum-allocation-mb</name > <value > 4096</value > </property > <property > <name > yarn.nodemanager.vmem-pmem-ratio</name > <value > 4</value > </property > <property > <name > yarn.nodemanager.env-whitelist</name > <value > JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value > </property > </configuration >
执行命令vim mapred-site.xml编辑 MapReduce 配置文件,添加以下内容:
1 2 3 4 5 6 7 8 9 10 <?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > </configuration >
在/data/hadoop-3.3.1/etc/hadoop路径下,执行命令vim workers配置 workers(注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行)
1 2 3 192.168.68.111 192.168.68.112 192.168.68.113
创建对应目录
1 2 mkdir /data/hadoop-3.3.1/data/datanode mkdir /data/hadoop-3.3.1/data/tmp
更改hadoop安装包所属用户
1 2 chown -R hadoop:hadoop hadoop-3.3.1/ chown -R hadoop:hadoop hadoop-3.3.1/*
切换到hadoop用户,执行以下命令将配置好的 hadoop 安装包分发到另外两台机器(另外两台检查安装包所属用户,安装步骤10更换到hadoop用户)
1 2 scp -r hadoop-3.3.1 root@192.168.68.112:/data/ scp -r hadoop-3.3.1 root@192.168.68.113:/data/
三台虚拟机依次添加环境变量,编辑/etc/profile文件,添加以下内容,然后source /etc/profile保存,执行hadoop version命令检查是否添加成功
1 2 3 4 #HADOOP_HOME export HADOOP_HOME=/data/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
集群第一次启动,需要在主节点格式化 NameNode(均使用 hadoop 用户)(注意:
使用 hadoop 用户启动 HDFS
在192.168.68.112上启动 YARN
jps查看三台虚拟机的服务进程是否如下表所示
192.168.68.111
192.168.68.112
192.168.68.113
HDFS
NameNode
DataNode
SecondaryNameNode
Yarn
NodeManager
ResourceManager
NodeManager
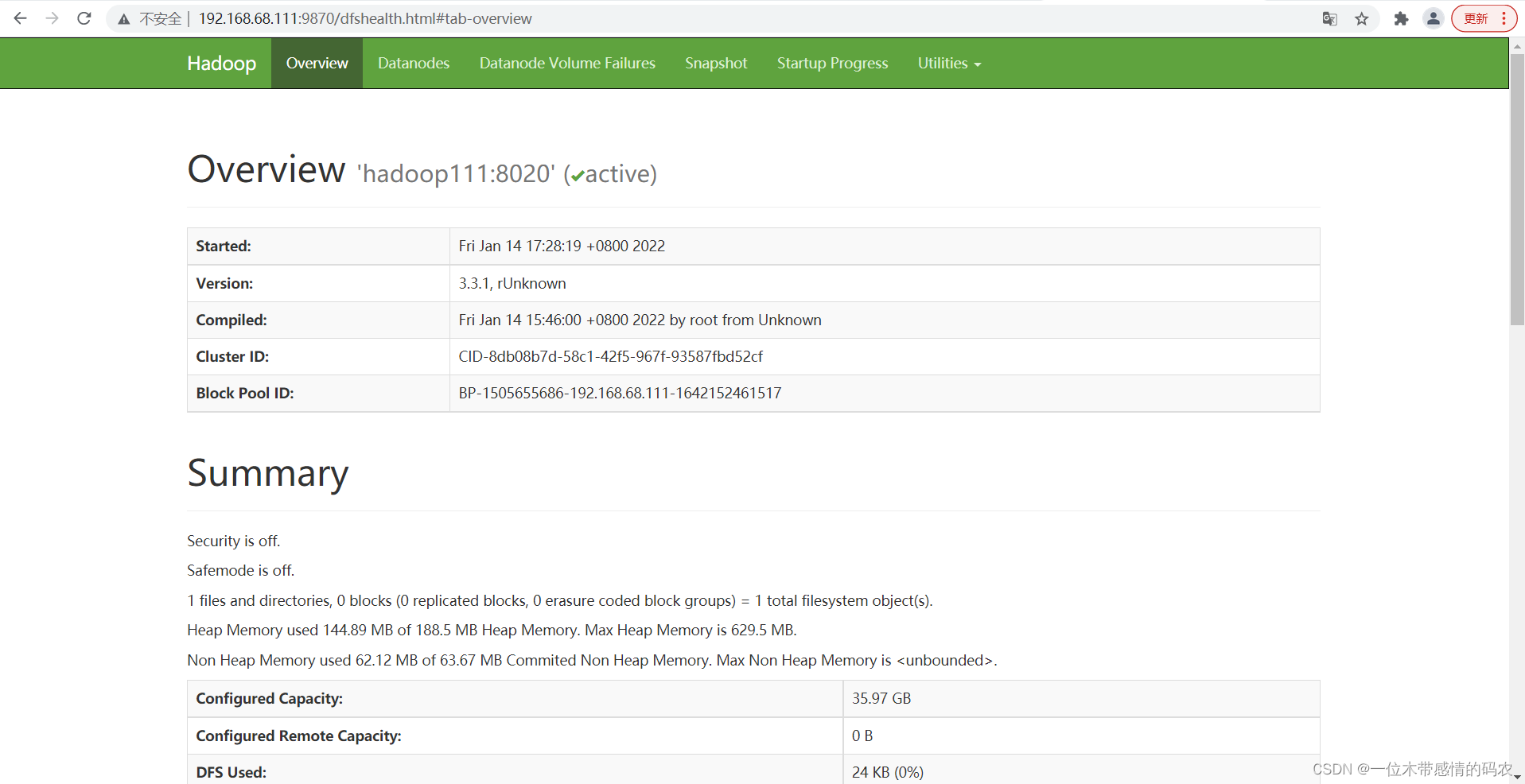
Web 端查看 HDFS 的 NameNode(可以在Utilities=>Browse the file system查看 HDFS 目录结构)
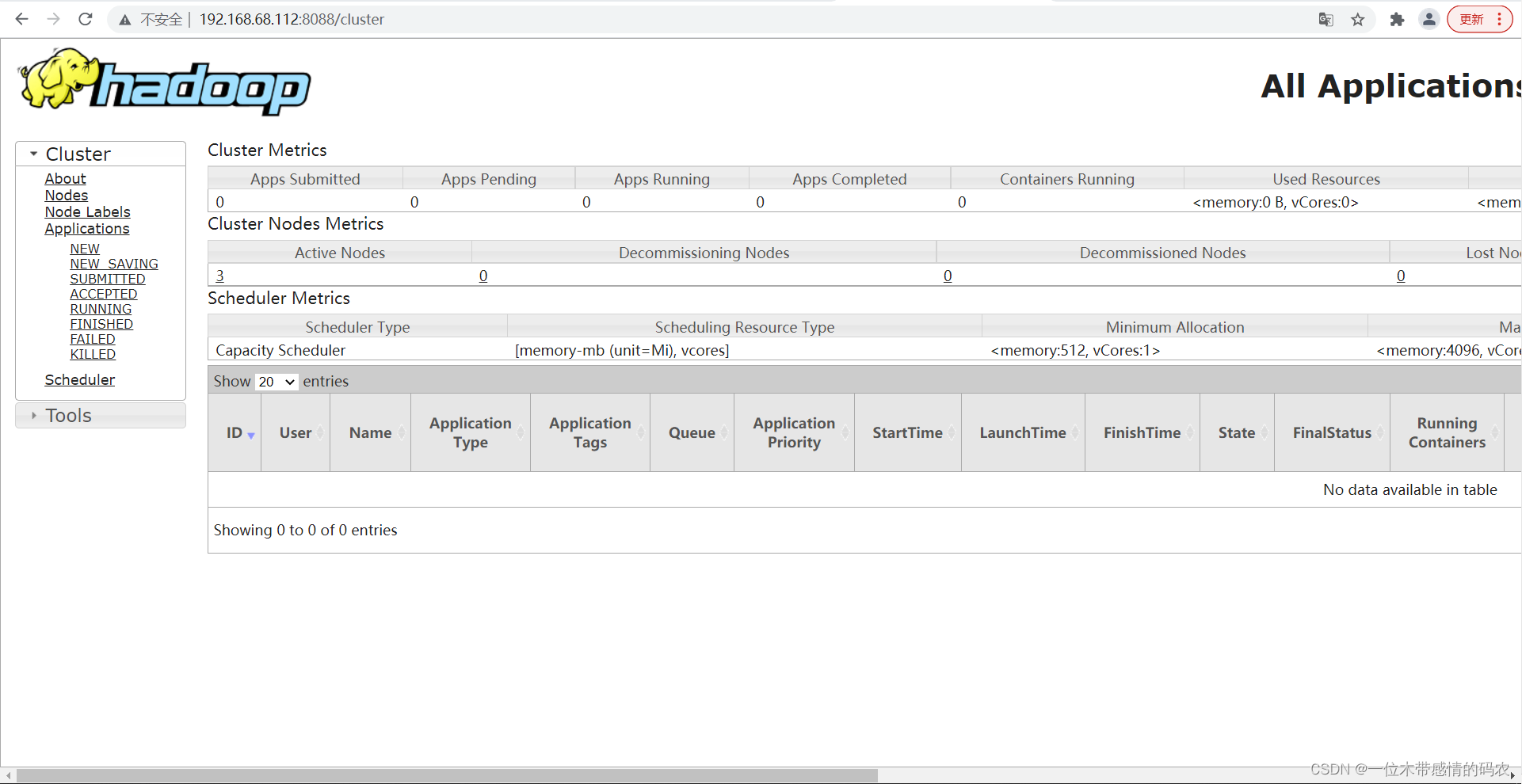
Web 端查看 YARN 的 ResourceManager
5. 集群基本测试
上传文件到集群
1 2 [hadoop@localhost hadoop-3.3.1]$ hadoop fs -mkdir /input [hadoop@localhost hadoop-3.3.1]$ hadoop fs -put /data/input/1.txt /input
前往 HDFS 文件存储路径,查看 HDFS 在磁盘存储文件的内容
1 2 3 4 5 6 7 8 [hadoop@localhost subdir0]$ pwd /data/hadoop-3.3.1/data/dfs/data/current/BP-503073314-127.0.0.1-1641801366580/current/finalized/subdir0/subdir0 [hadoop@localhost subdir0]$ ls blk_1073741825 blk_1073741825_1001.meta [hadoop@localhost subdir0]$ cat blk_1073741825 hello hadoop stream data flink spark
下载文件
1 2 3 4 5 6 7 [hadoop@localhost hadoop-3.3.1]$ hadoop fs -get /input/1.txt /data/output/ [hadoop@localhost hadoop-3.3.1]$ ls /data/output/ 1.txt [hadoop@localhost hadoop-3.3.1]$ cat /data/output/1.txt hello hadoop stream data flink spark
执行 wordcount 程序
1 2 3 4 5 6 7 8 9 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output ----------------------------------------------------------------------------------------------------------- 查看/output/下的文件内容(windows浏览器web页面拉取文件查看时,需在C:\Windows\System32\drivers\etc\hosts中添加 2.4 节说过的地址映射) data 1 flink 1 hadoop 1 hello 1 spark 1 stream 1
计算圆周率(计算命令中 2 表示计算的线程数,50 表示投点数,该值越大,则计算的 pi 值越准确)
1 2 3 4 yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 2 50 ----------------------------------------------------------------------------------------------------------- Job Finished in 23.948 seconds Estimated value of Pi is 3.20000000000000000000
6. 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
vim mapred-site.xml编辑 MapReduce 配置文件,添加以下内容(三台虚拟机均需):
1 2 3 4 5 6 7 8 9 10 <property > <name > mapreduce.jobhistory.address</name > <value > 192.168.68.111:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > 192.168.68.111:19888</value > </property >
在192.168.68.111启动历史服务器
1 2 3 4 5 6 7 8 9 开启:mapred --daemon start historyserver 关闭:mapred --daemon stop historyserver ----------------------------------------------------------------------------------------------------------- #jps 15299 DataNode 15507 NodeManager 15829 Jps 15769 JobHistoryServer 15132 NameNode
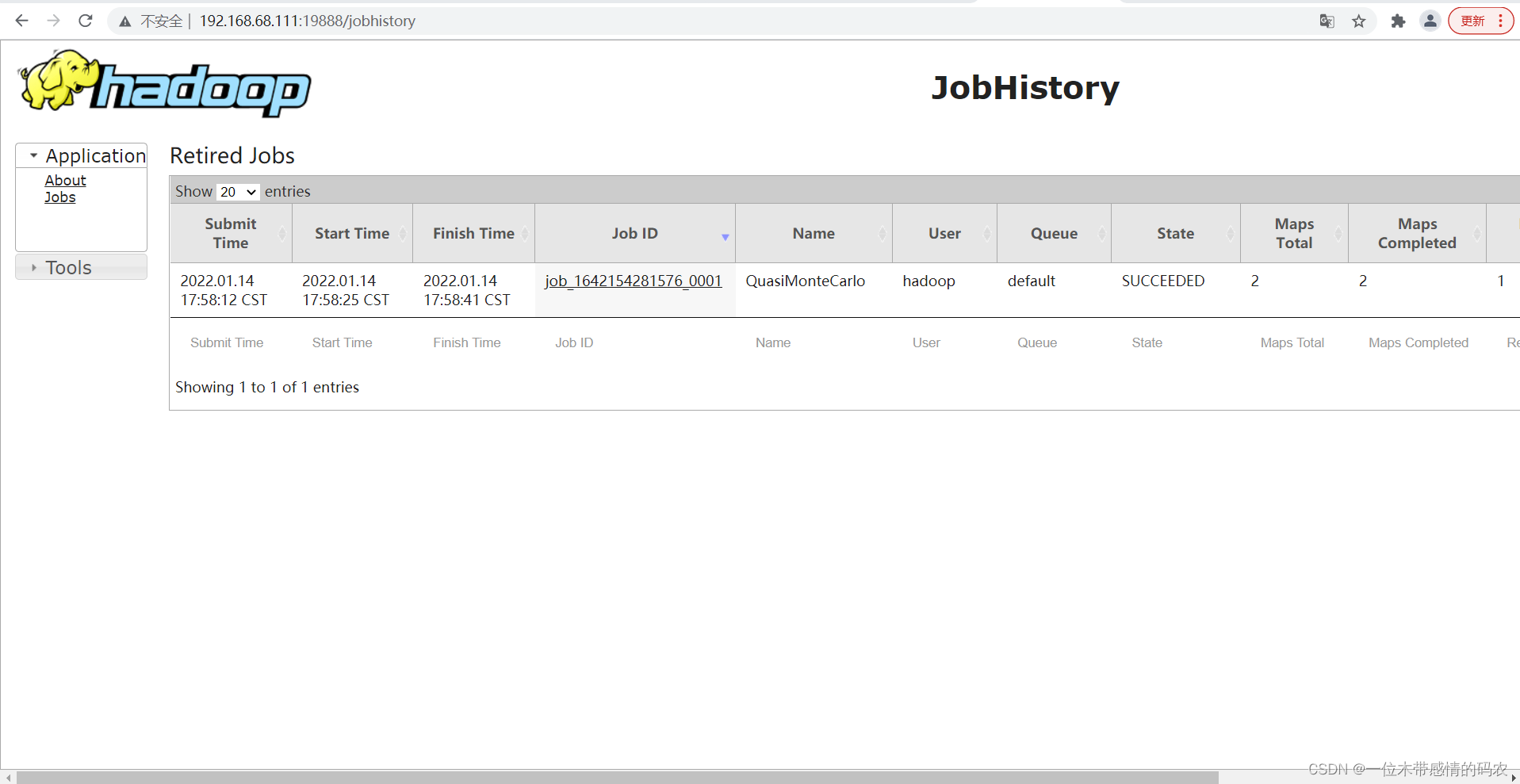
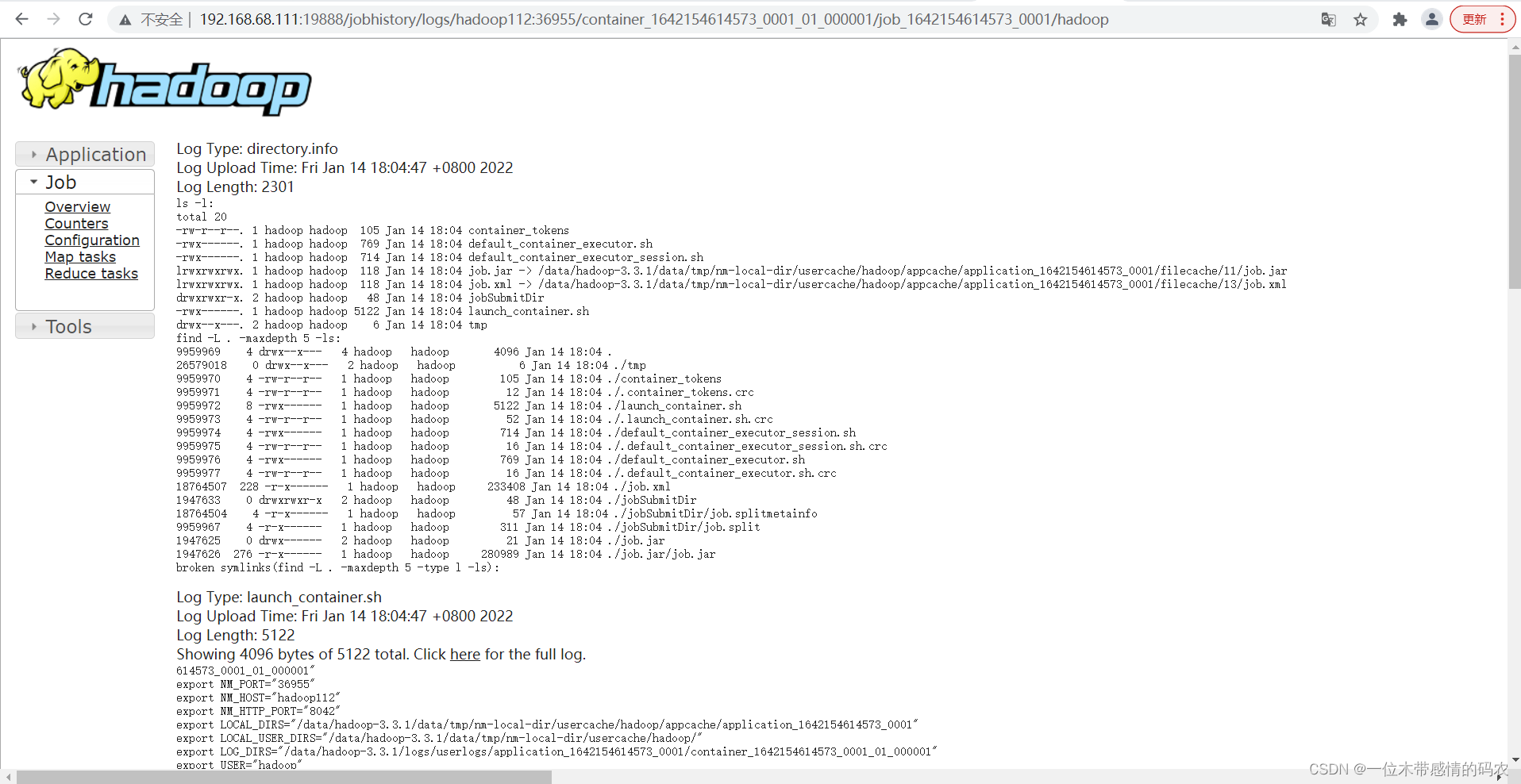
查看JobHistory
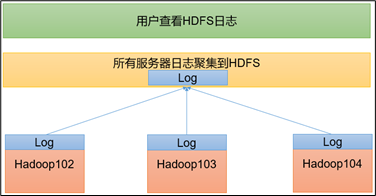
7. 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
vim yarn-site.xml配置 yarn-site.xml,添加下面的内容(三台均需):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log.server.url</name > <value > http://192.168.68.111:19888/jobhistory/logs</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property >
重启服务,执行 wordcount 程序
1 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
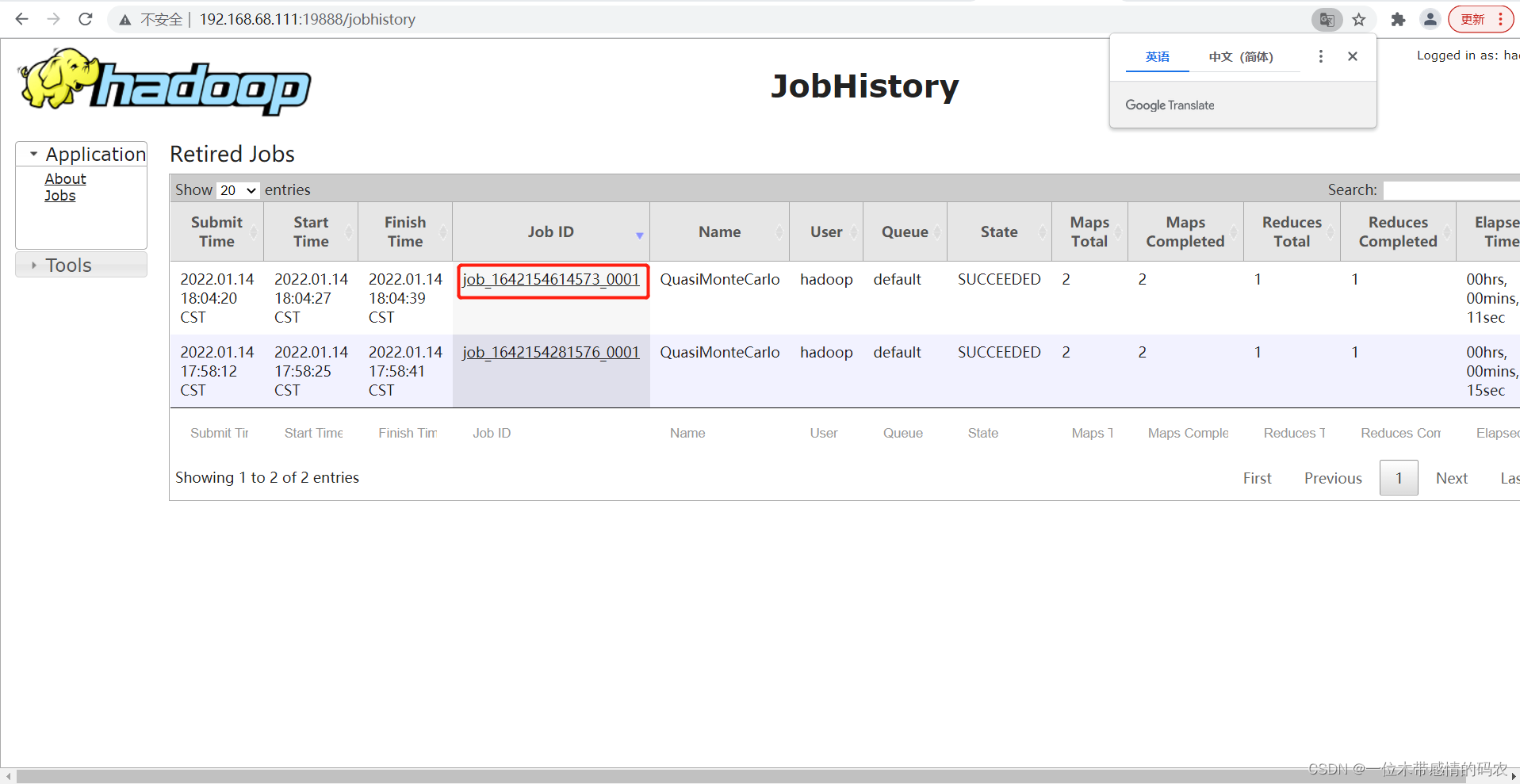
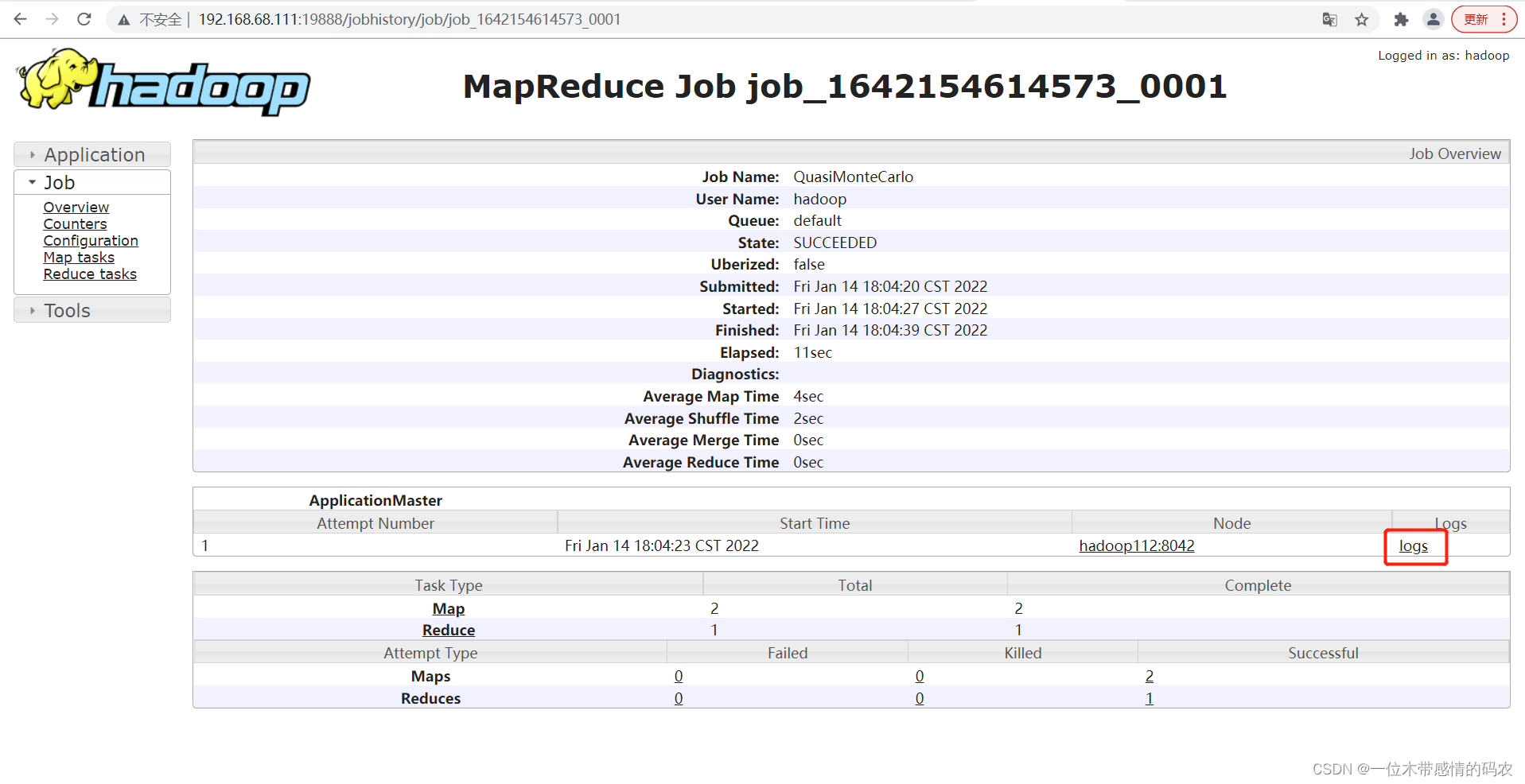
查看日志
8. 集群启动/停止命令总结
整体启动/停止 HDFS
1 start-dfs.sh/stop-dfs.sh
整体启动/停止 YARN
1 start-yarn.sh/stop-yarn.sh
分别启动/停止 HDFS 组件
1 hdfs --daemon start/stop namenode/datanode/secondarynamenode
启动/停止YARN
1 yarn --daemon start/stop resourcemanager/nodemanager
9. 集群群起脚本
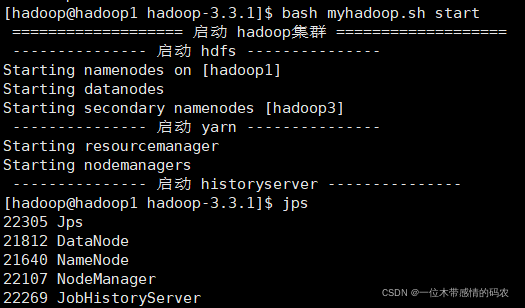
vim myhadoop.sh添加下面内容并保存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh 192.168.68.111 "/data/hadoop-3.3.1/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh 192.168.68.112 "/data/hadoop-3.3.1/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh 192.168.68.111 "/data/hadoop-3.3.1/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh 192.168.68.111 "/data/hadoop-3.3.1/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh 192.168.68.112 "/data/hadoop-3.3.1/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh 192.168.68.111 "/data/hadoop-3.3.1/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac
chmod +x myhadoop.sh赋予脚本执行权限启动/停止集群
10. 常用端口号说明
端口名称
Hadoop2.x
Hadoop3.x
NameNode内部通信端口
8020 / 9000
8020 / 9000 / 9820
NameNode HTTP UI
50070 9870
MapReduce查看执行任务端口
8088
8088
历史服务器通信端口
19888
19888