
《数据结构与算法》(十三)- 图的应用:最小生成树
前言
部分内容摘自程杰的《大话数据结构》
1. 最小生成树
假设你是电信的实施工程师,需要为一个镇的九个村庄架设通信网络做设计,村庄位置大致如下图,其中 v~v 是村庄,之间连线的数字表示村与村间的可通达的直线距离,比如 v 至 v 就是 10 公里(个别如 v 与 v,v 与v,v 与 v 未测算距离是因为有高山或湖泊,不予考虑)。你们领导要求你必须用最小的成本完成这次任务。你说怎么办?
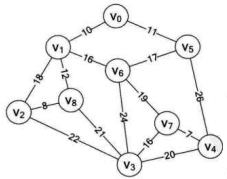
显然这是一个带权值的图,即网结构。所谓的最小成本,就是n个顶点,用n-1条边把一个连通图连接起来,并且使得权值的和最小。在这个例子里,每多一公里就多一份成本,所以只要让线路连线的公里数最少,就是最少成本了。
如果你加班加点,没日没夜设计出的结果是如下图的方案一(粗线为要架设线路),我想你离被炒鱿鱼应该是不远了。因为这个方案比后两个方案多出 60% 的成本会让老板气晕过去的。
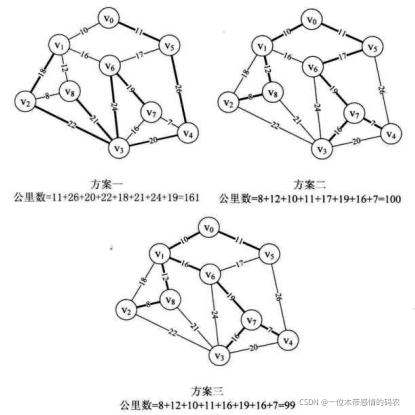
方案三设计得非常巧妙,但也只以极其微弱的优势对方案二胜出,应该说很是侥幸。我们有没有办法可以精确计算出这种网图的最佳方案呢?答案当然是可以。
我们在讲图的定义和术语时,曾经提到过,一个连通图的生成树是一个极小的连通子图,它含有图中全部的顶点,但只有足以构成一棵树的n-1条边。显然上图的三个方案都是上上图的网图的生成树。那么我们把构造连通网的最小代价生成树称为最小生成树(Minimum Cost SpanningTree)。
找连通网的最小生成树,经典的有两种算法,普里姆算法和克鲁斯卡尔算法。我们分别来介绍一下。
1.1 普里姆(Prim)算法
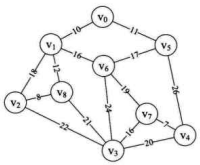
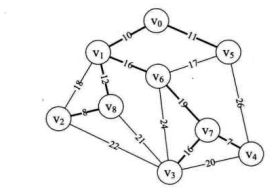
为了能讲明白这个算法,我们先构造上面相同图的邻接矩阵,如右下图所示。
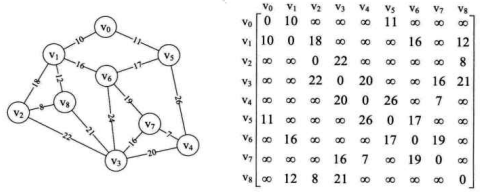
也就是说,现在我们已经有了一个存储结构为MGragh的G。G有 9 个顶点,它的arc二维数组如右上图所示。数组中的我们用 65535 来代表∞。
于是普里姆(Prim)算法代码如下。其中INFINITY为权值极大值,不妨是 65535,MAXVEX为顶点个数最大值,此处大于等于 9 即可。现在假设我们自己就是计算机,在调用MiniSpanTree_Prim()函数,输入上述的邻接矩阵后,看看它是如何运行并打印出最小生成树的。
1 | /* Prim算法生成最小生成树 */ |
- 程序开始运行,我们由第5行和第6行,创建了两个一维数组
lowcost和adjvex,长度都为顶点个数 9。它们的作用我们慢慢细说。 - 第 7 行和第 8 行我们分别给这两个数组的第一个下标位赋值为 0,
adjvex[0]=0其实意思就是我们现在从顶点 v 开始(事实上,最小生成树从哪个顶点开始计算都无所谓,我们假定从 v 开始),lowcost[0]=0就表示 v 已经被纳入到最小生成树中,之后凡是lowcost数组中的值被设置为 0 就是表示此下标的顶点被纳入最小生成树。 - 第 9~12 行表示我们读取上图的右图邻接矩阵的第一行数据。将数值赋值给
lowcost数组,所以此时lowcost数组值为 {0,10,65535,65535,11,65535, 65535, 65535},而adjvex则全部为 0。此时,我们已经完成了整个初始化的工作,准备开始生成。 - 第 14~37 行,整个循环过程就是构造最小生成树的过程。
- 第 16 行和第 17 行,将
min设置为了一个极大值 65535,它的目的是为了之后找到一定范围内的最小权值。j是用来做顶点下标循环的变量,k是用来存储最小权值的顶点下标。 - 第 18~26 行,循环中不断修改
min为当前lowcost数组中最小值,并用k保留此最小值的顶点下标。经过循环后,min=10,k=1。注意 19 行if判断的lowcost[j]!=0表示已经是生成树的顶点不参与最小权值的查找。 - 第 27 行,因
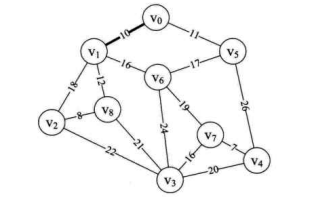
k=1,adjvex[1]=0,所以打印结果为 (0, 1),表示 v 至 v 边为最小生成树的第一条边。如下图所示。
- 第 28 行,此时因
k=1我们将lowcost[k]=0就是说顶点 v 纳入到最小生成树中。此时lowcost数组值为 {0,0,65535,65535,65535,11,65535,65535,65535}。 - 第 29~36 行,
j循环由 1 至 8,因k=1,查找邻接矩阵的第 v 行的各个权值,与lowcost的对应值比较,若更小则修改lowcost值,并将k值存入adjvex数组中。因第 v 行有 18、16、 12 均比 65535 小,所以最终lowcost数组的值为:{0,0,18,65535,65535,11,16,65535,12}。adjvex数组的值为:{0,0,1,0,0,0,1,0,1}。这里第 30 行if判断的lowcost[j]!=0也说明 v 和 v 已经是生成树的顶点不参与最小权值的比对了。 - 再次循环,由第 16 行到第 27 行,此时
min=11,k=5,adjvex[5]=0。 因此打印结构为 (0, 5)。表示 v 至 v 边为最小生成树的第二条边,如下图所示。
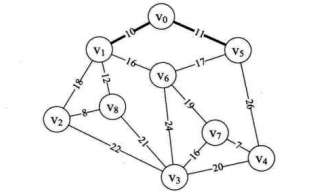
- 接下来执行到 37 行,
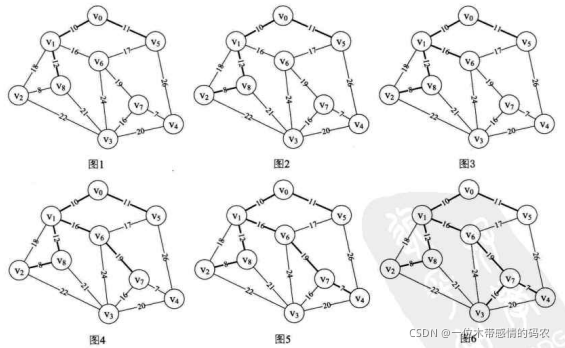
lowcost数组的值为:{0,0,18,65535,26,0,16,65535,12}。adjvex数组的值为:{0,0,1,0,5,0,1,0,1}。 - 之后,相信大家也都会自己去模拟了。通过不断的转换,构造的过程如下图中图1~图6所示。
有了这样的讲解,再来介绍普里姆(Prim)算法的实现定义可能就容易理解一些。
假设 N=(V,{E}) 是连通网,TE是N上最小生成树中边的集合。算法从 U={u}(u∈V),TE={} 开始。重复执行下述操作:在所有 u∈U,v∈V-U 的边 (u,v)∈E 中找一条代价最小的边 (u,v) 并入集合TE,同时 v 并入U,直至U=V为止。此时TE中必有n-1条边,则T=(V,{TE})为N的最小生成树。
由算法代码中的循环嵌套可得知此算法的时间复杂度为。
1.2 克鲁斯卡尔(Kruskal)算法
现在我们来换一种思考方式, 普里姆(Prim)算法是以某顶点为起点,逐步找各顶点上最小权值的边来构建最小生成树的。这就像是我们如果去参观某个展会,例如世博会,你从一个入口进去,然后找你所在位置周边的场馆中你最感兴趣的场馆观光,看完后再用同样的办法看下一个。可我们为什么不事先计划好,进园后直接到你最想去的场馆观看呢?事实上,去世博园的观众,绝大多数都是这样做的。
同样的思路,我们也可以直接就以边为目标去构建,因为权值是在边上,直接去找最小权值的边来构建生成树也是很自然的想法,只不过构建时要考虑是否会形成环路而已。此时我们就用到了图的存储结构中的边集数组结构。以下是edge边集数组结构的定义代码:
1 | /* 对边集数组Edge结构的定义 */ |
我们将同样的图的邻接矩阵通过程序转化为右下图的边集数组,并且对它们按权值从小到大排序。
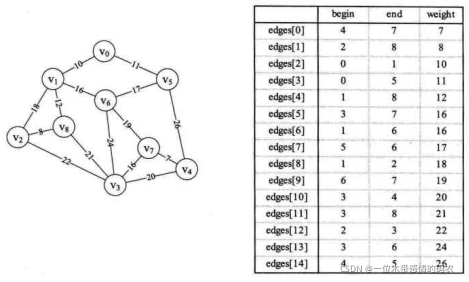
于是克鲁斯卡尔(Kruskal)算法代码如下。其中MAXEDGE为边数量的极大值,此处大于等于 15 即可,MAXVEX为顶点个数最大值,此处大于等于 9 即可。现在假设我们自己就是计算机,在调用MiniSpanTree_Kruskal函数,输入下图的邻接矩阵后,看看它是如何运行并打印出最小生成树的。
1 | /* Kruskal算法生成最小生成树 */ |
- 程序开始运行,第 6 行之后,我们省略掉颇占篇幅但却很容易实现的将邻接矩阵转换为边集数组,并按权值从小到大排序的代码,也就是说,在第 6 行开始,我们已经有了结构为
edge,数据内容是上图的一维数组edges。 - 第 6~11 行,我们声明一个数组
parent,并将它的值都初始化为 0,它的作用我们后面慢慢说。 - 第 12~21 行,我们开始对边集数组做循环遍历,开始时,
i=0。 - 第 14 行,我们调用了第 25~32 行的函数
Find(),传入的参数是数组parent和当前权值最小边 (v,v) 的begin:4。因为parent中全都是 0 所以传出值使得n=4。 - 第 15 行,同样作法,传入 (v,v) 的
end:7,传出值使得m=7。 - 第 16~20 行,很显然
n与m不相等,因此parent[4]=7。此时parent数组值为 {0,0, 0, 0, 7, 0, 0, 0, 0},并且打印得到 “(4, 7) 7”。此时我们已经将边 (v,v) 纳入到最小生成树中,如下图所示。
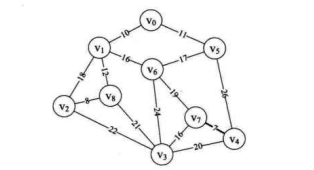
- 循环返回,执行 14~20 行,此时
i=1,edge[1]得到边 (v,v),n=2,m=8,parent[2]=8,打印结果为 “(2, 8) 8",此时parent数组值为 {0, 0, 8, 0,7, 0, 0, 0, 0},这也就表示边 (v,v) 和边 (v,v) 已经纳入到最小生成树,如下图所示。
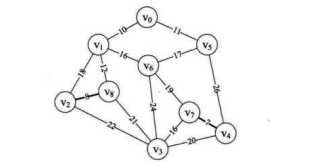
- 再次执行 14~20 行,此时
i=2,edge[2]得到边 (v,v),n=0,m=1,parent[0]=1,打印结果为 “(0, 1) 10”,此时parent数组值为 {1, 0, 8, 0, 7, 0, 0, 0, 0},此时边 (v,v)、 (v,v)和 (v,v) 已经纳入到最小生成树,如下图所示。
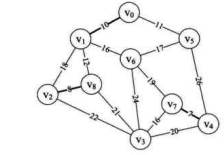
- 当
i=3、4、5、6时,分别将边 (v,v)、(v,v)、(v,v)、(v,v)纳入到最小生成树中,如下图所示。此时parent数组值为 {1, 5, 8, 7, 7, 8,0, 0, 6},怎么去解读这个数组现在这些数字的意义呢?
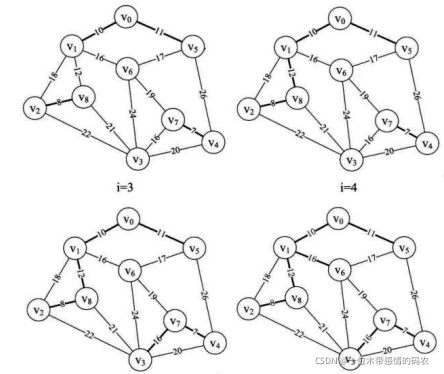
从上图的右下图i=6的粗线连线可以得到,我们其实是有两个连通的边集合A与B中纳入到最小生成树中的,如下图所示。当parent(0]=1,表示 v 和 v 已经在生成树的边集合A中。此时将parent[0]=1的 1 改为下标,由parent[1]=5,表示 v 和 v 在边集合·A·中,parent[5]=8表示 v 与 v 在边集合A中,parent[8]=6表示 v 与 v 在边集合A中,parent[6]=0表示集合A暂时到头,此时边集合A有v、v、v、v、v。我们查看parent中没有查看的值,parent[2]=8表示 v 与 v 在一个集合中,因此 v 也在边集合A中。再由parent[3]=7、parent[4]=7和parent[7]=0可知 v、v、v 在另一个边集合B中。
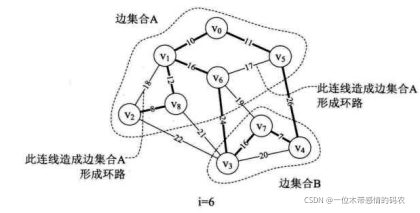
- 当
i=7时,第 14 行,调用Find函数,会传入参数edges[7].begin=5。此时第 27 行,parent[5]=8>0,所以f=8,再循环得parent[8]=6。因parent[6]=0所以Find返回后第 14 行得到n=6。而此时第 12 行,传入参数edges[7].end=6得到m=6。此时n=m,不再打印,继续下一循环。这就告诉我们,因为边 (v,v) 使得边集合A形成了环路。因此不能将它纳入到最小生成树中,如上图所示。 - 当
i=8时,与上面相同,由于边 (v,v) 使得边集合A形成了环路。因此不能将它纳入到最小生成树中,如上图所示。 - 当
i=9时,边(v,v),第 14 行得到n=6,第 15 行得到m=7,因此parent[6]=7,打印 “(6, 7) 19"。此时parent数组值为 {1, 5, 8, 7, 7, 8, 7, 0, 6},如下图所示。 - 此后边的循环均造成环路,最终最小生成树即为下图所示。
假设N=(V{E})是连通网,则令最小生成树的初始状态为只有n个顶点而无边的非连通图T={V,{}},图中每个顶点自成一-个连通分量。在E中选择代价最小的边,若该边依附的顶点落在T中不同的连通分量上,则将此边加入到T中,否则舍去此边而选择下一条代价最小的边。依次类推,直至T中所有顶点都在同一连通分量上为止。
此算法的Find函数由边数e决定,时间复杂度为,而外面有一个for循环e次。所以克鲁斯卡尔算法的时间复杂度为。
对比两个算法,克鲁斯卡尔算法主要是针对边来展开,边数少时效率会非常高,所以对于稀疏图有很大的优势;而普里姆算法对于稠密图,即边数非常多的情况会更好一些。
2. 总结
最小生成树,我们讲了两种算法:普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法。普里姆算法像是走一步看一步的思维方式,逐步生成最小生成树。而克鲁斯卡尔算法则更有全局意识,直接从图中最短权值的边入手,找寻最后的答案。



