
《数据结构与算法》(五)- 链表详解
前言
部分内容摘自程杰的《大话数据结构》
1. 线性表链式存储结构
1.1 链表的定义
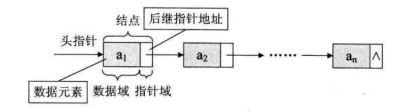
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的。这就意味着,这些数据元素可以存在内存未被占用的任意位置。
以前在顺序结构中,每个数据元素只需要存数据元素信息就可以了。现在链式结构中,除了要存数据元素信息外,还要存储它的后继元素的存储地址。
因此,为了表示每个数据元素 a 与其直接后继数据元素 a 之间的逻辑关系,对数据元素 a 来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称做指针或链。这两部分信息组成数据元素 a 的存储映像,称为结点(Node)。
n个结点(a的存储映像)链结成一个链表,即为线性表(a,a,…,a)的链式存储结构,因为此链表的每个结点中只包含一个指针域,所以叫做单链表。单链表正是通过每个结点的指针域将线性表的数据元素按其逻辑次序链接在一起。
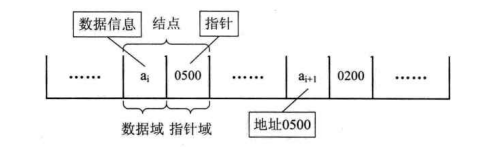
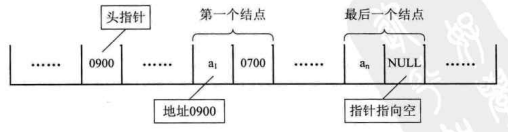
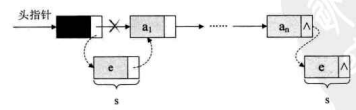
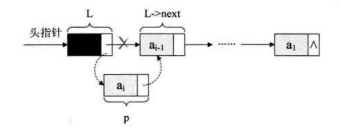
对于线性表来说,总得有个头有个尾,链表也不例外。我们把链表中第一个结点的存储位置叫做头指针,那么整个链表的存取就必须是从头指针开始进行了。之后的每一个结点,其实就是上一个的后继指针指向的位置。想象一下,最后一个结点,它的指针指向哪里?
最后一个,当然就意味着直接后继不存在了,所以我们规定,线性链表的最后一个结点指针为“空”(通常用NULL或“^”符号表示,如下图所示)。
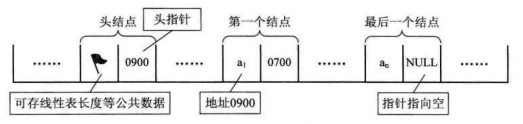
有时,我们为了更加方便地对链表进行操作,会在单链表的第一个结点前附设一个结点,称为头结点。头结点的数据域可以不存储任何信息,谁叫它是第一个呢,有这个特权。也可以存储如线性表的长度等附加信息,头结点的指针域存储指向第一个结点的指针,如下图所示。
1.2 头指针与头结点的异同
头指针:
- 头指针是指链表指向第一个结点的指针,若链表有头结点,则是指向头结点的指针
- 头指针具有标识作用,所以常用头指针冠以链表的名字
- 无论链表是否为空,头指针均不为空。头指针是链表的必要元素
头结点:
- 头结点是为了操作的统一和方便而设立的,放在第一元素的结点之前,其数据域一般无意义(也可存放链表的长度)
- 有了头结点,对在第一元素结点前插入结点和删除第一结点,其操作与其它结点的操作就统一了
- 头结点不一定是链表必须要素
1.3 代码描述
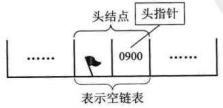
若线性表为空,则头结点的指针域为“空”,如下图:
这里我们大概地用图示表达了内存中单链表的存储状态。看着满图的省略号 “……”,你就知道是多么不方便。而我们真正关心的:它是在内存中的实际位置吗?不是的,这只是它所表示的线性表中的数据元素及数据元素之间的逻辑关系。所以我们改用更方便的存储示意图来表示单链表,如下图所示。
若带有头结点的单链表,则如下图所示:

空链表如下图所示:
单链表中,我们在C语言中可用结构指针来描述:
1 | /* 线性表的单链表存储结构 */ |
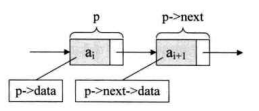
从这个结构定义中,我们也就知道,结点由存放数据元素的数据域存放后继结点地址的指针域组成。假设p是指向线性表第i个元素的指针,则该结点 a 的数据域我们可以用p->data来表示,p->data的值是一个数据元素,结点 a 的指针域可以用p->next来表示,p->next的值是一个指针。p->next指向谁呢?当然是指向第i+1个元素,即指向 a 的指针。也就是说,如果p->data等于 a,那么p->next>data等于 a(如下图所示)
2. 单链表的读取
在线性表的顺序存储结构中,计算任意一个元素的存储位置是很容易的。但在单链表中,由于第i个元素到底在哪?没办法一开始就知道,必须得从头开始找。因此,对于单链表实现获取第i个元素的数据的操作GetElem,在算法上,相对要麻烦一些。
获得链表第i个数据的算法思路:
- 声明一个结点
p指向链表第一个结点,初始化j从1开始; - 当
j<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1; - 若到链表末尾
p为空,则说明第i个元素不存在; - 否则查找成功,返回结点
p的数据。
实现代码算法如下:
1 | /* 初始条件:链式线性表L已存在,1≤i≤ListLength(L) */ |
说白了,就是从头开始找,直到第i个元素为止。由于这个算法的时间复杂度取决于i的位置,当i=1时,则不需遍历,第一个就取出数据了,而当i=n时则遍历n-1次才可以。因此最坏情况的时间复杂度是O(n)。
由于单链表的结构中没有定义表长,所以不能事先知道要循环多少次,因此也就不方便使用for来控制循环。其主要核心思想就是“工作指针后移",这其实也是很多算法的常用技术。
3. 单链表的插入与删除
3.1 单链表的插入
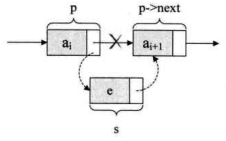
假设存储元素e的结点为s,要实现结点p、p->next和s之间逻辑关系的变化,只需将结点s插入到结点p和p->next之间即可。可如何插入呢 ?
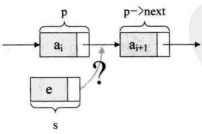
根本用不着惊动其他结点,只需要让s->next和p->next的指针做一点改变即可。
1 | s->next=p->next; /* 将p的后继节点赋值给s的后继 */ |
解读这两句代码,也就是说让p的后继结点改成s的后继结点,再把结点s变成p的后继结点。
考虑一下,这两句的顺序可不可以交换?
如果先p->next=s; 再s->next=p->next;会怎么样?因为此时第一句会将·p->nex·t给覆盖成s的地址了。那么s->next=p->next,其实就等于s->next=s,这样真正的拥有 a 数据元素的结点就没了上级。这样的插入操作就是失败的,造成了临场掉链子的尴尬局面。所以这两句是无论如何不能反的,这点初学者一定要注意。
插入结点s后,链表如下图所示。
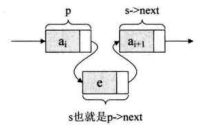
对于单链表的表头和表尾的特殊情况,操作是相同的,如下图所示。
单链表第i个数据插入结点的算法思路:
- 声明一结点
p指向链表第-一个结点, 初始化j从1开始; - 当
j<i时, 就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1; - 若到链表末尾
p为空,则说明第i个元素不存在; - 否则查找成功,在系统中生成-一个空结点
s; - 将数据元素
e赋值给s->data; - 单链表的插入标准语句
s->next=p->next;p->next=s; - 返回成功。
实现代码算法如下:
1 | /* 初始条件:链式线性表L已存在,1≤i≤ListLength(L) */ |
在这段算法代码中,我们用到了C语言的malloc标准函数,它的作用就是生成一个新的结点,其类型与Node是一样的, 其实质就是在内存中找了一小块空地, 准备用来存放数据e的s结点。
3.2 单链表的删除
设存储元素 a 的结点为q,要实现将结点q删除单链表的操作,其实就是将它的前继结点的指针绕过,指向它的后继结点即可,如图下图所示。
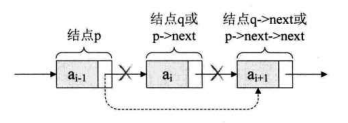
我们所要做的,实际上就是一步,p->next=p->next->next,用q来取代p->next,即
1 | q=p->next; |
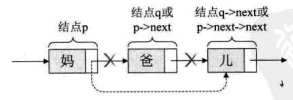
解读这两句代码,也就是说把p的后继结点改成p的后继的后继结点。打个形象的比方:本来是爸爸左手牵着妈妈的手,右手牵着宝宝的手在马路边散步。突然迎面走来一美女,爸爸一下子看呆了 ,此情景被妈妈逮个正着,于是她生气地甩开牵着的爸爸的手,绕过他,扯开父子俩,拉起宝宝的左手就快步朝前走去。此时妈妈是p结点,妈妈的后继是爸爸p->next,也可以叫q结点,妈妈的后继的后继是儿子p->next->next,即q->next。 当妈妈去牵儿子的手时,这个爸爸就已经与母子俩没有牵手联系了,如下图所示。
单链表第i个数据删除结点的算法思路:
- 声明一指针
p指向链表头结点,初始化j从1开始; - 当
j<i时,就遍历链表,让p的指针向后移动,不断指向下一个结点,j累加1;
1; - 若到链表末尾
p为空,则说明第i个结点不存在; - 否则查找成功,将欲删除的结点
p->next赋值给q; - 单链表的删除标准语句
p->next=q->next; - 将
q结点中的数据赋值给e,作为返回; - 释放
q结点; - 返回成功。
实现代码算法如下:
1 | /* 初始条件:链式线性表L已存在,1≤i≤ListLength(L) */ |
这段算法代码里,我们又用到了另一个C语言的标准函数free。它的作用就是让系统回收一个Node结点,释放内存。
分析一下刚才讲解的单链表插入和删除算法,可以发现,它们其实都是由两部分组成:第一部分就是遍 历查找第i个元素;第二部分就是插入和删除元素。
从整个算法来说,我们很容易推导出:它们的时间复杂度都是O(N)。如果我们不知道第i个元素的指针位置,单链表数据结构在插入和删除操作上,与线性表的顺序存储结构是没有太大优势的。但如果我们希望从第i个位置,插入10个元素,对于顺序存储结构意味着,每一次插入都需要移动n-i个元素,每次都是O(n)。 而单链表,我们只需要在第一次时, 找到第i个位置的指针,此时为O(n),接下来只是简单地通过赋值移动指针而已,时间复杂度都是O(1)。显然,对于插入或删除数据越频繁的操作,单链表的效率优势就越明显。
4. 单链表的整表创建
顺序存储结构的创建,其实就是一个数组的初始化,即声明一个类型和大小的数组并赋值的过程。而单链表和顺序存储结构就不一样,它不像顺序存储结构这么集中,它可以很散,是一种动态结构。对于每个链表来说,它所占用空间的大小和位置是不需要预先分配划定的,可以根据系统的情况和实际的需求即时生成。
所以创建单链表的过程就是一个动态生成链表的过程。即从“空表”的初始状态起,依次建立各元素结点,并逐个插入链表。
单链表整表创建的算法思路:
- 声明一指针
p和计数器变量i; - 初始化一空链表
L; - 让
L的头结点的指针指向NULL,即建立一个带头结点的单链表。 - 循环:
①生成一新结点赋值给p;
②随机生成一数字赋值给p的数据域p->data;
③将p插入到头结点与前一新结点之间。
实现代码算法如下:
1 | /* 随机产生n个元素的值,建立带表头姑点的单链线性表L(头插法) */ |
这段算法代码里,用的其实是插队的办法,就是始终让新结点在第一的位置。我也可以把这种算法简称为头插法。
事实上,我们还可以不这样干,为什么不把新结点都放到最后呢,这才是排队时的正常思维,所谓的先来后到。我们把每次新结点都插在终端结点的后面,这种算法称之为尾插法。
实现代码算法如下:
1 | /* 随机产生n个元素的值,建立带表头结点的单链线性表L(尾插法) */ |
注意L与r的关系,L是指整个单链表,而r是指向尾结点的变量,r会随着循环不断地变化结点,而L则是随着循环增长为一个多结点的链表。
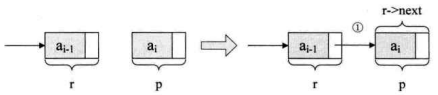
这里需解释一下,r->next=p;的意思, 其实就是将刚才的表尾终端结点r的指针指向新结点p,如下图所示,当中①位置的连线就是表示这个意思。
r->next=p;这一句 应该还好理解,很多人不理解的就是后面这一句r=p;是什么意思,看下图。
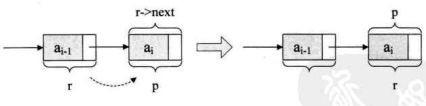
它的意思,就是本来r是在 a 元素的结点,可现在它已经不是最后的结点了,现在最后的结点是 a,所以应该要让将p结点这个最后的结点赋值给r。此时r又是最终的尾结点了。
循环结束后,那么应该让这个结点的指针域置空,因此有了r->next=NULL;,以便以后遍历时可以确认其是尾部。
5. 单链表的整表删除
当我们不打算使用这个单链表时,我们需要把它销毁,其实也就是在内存中将它释放掉,以便于留出空间给其他程序或软件使用。
单链表整表删除的算法思路如下:
- 声明一指针p和q;
- 将第一个结点赋值给p;
- 循环:
①将下一结点赋值给q;
②释放p;
③将q赋值给p。
实现代码算法如下:
1 | /* 初始条件:链式线性表L已存在。操作结果:将L重置为空表 */ |
这段算法代码里,常见的错误就是有人会觉得q变量没有存在的必要。在循环体内直接写free(p);p=p->next即可。可这样会带来什么问题?
要知道p是一个结点,它除了有数据域,还有指针域。你在做free(p);时, 其实是在对它整个结点进行删除和内存释放的工作。这就好比皇帝快要病死了,却还没有册封太子,他儿子五六个,你说要是你脚一蹬倒是解脱了,这国家咋办,你那几个儿子咋办?这要是为了皇位,什么亲兄弟血肉情都成了浮云,一定会打起来。所以不行,皇帝不能马上死,得先把遗嘱写好,说清楚,哪个儿子做太子才行。而这个遗嘱就是变量q的作用,它使得下一个结点是谁得到了记录,以便于等当前结点释放后,把下一-结点拿回来补充。
6. 单链表结构与顺序存储结构的优缺点
简单地对单链表结构和顺序存储结构做对比:
- 存储分配方式:
- 顺序存储结构用一段连续的存储单元依次存储线性表的数据元素
- 单链表采用链式存储结构,用一组任意的存储单元存放线性表的元素
- 时间性能
- 查找
- 顺序存储结构O(1)
- 单链表O(n)
- 插入和删除
- 顺序存储结构需要平均移动表长一半的元素,时间为O(n)
- 单链表在找出某位置的指针后,插入和删除时间复杂度仅为O(1)
- 查找
- 空间性能
- 顺序存储结构需要预分配存储空间,分大了,浪费,分小了易发生上溢
- 单链表不需要分配存储空间,只要有就可以分配,元素个数也不受限制
通过上面的对比,我们可以得出一些经验性的结论:
- 若线性表需要频繁查找,很少进行插入和删除操作时,宜采用顺序存储结构。若需要频繁插入和删除时,宜采用单链表结构。比如说游戏开发中,对于用户注册的个人信息,除了注册时插入数据外,绝大多数情况都是读取,所以应该考虑用顺序存储结构。而游戏中的玩家的武器或者装备列表,随着玩家的游戏过程中,可能会随时增加或删除,此时再用顺序存储就不太合适了,单链表结构就可以大展拳脚。当然,这只是简单的类比,现实中的软件开发,要考虑的问题会复杂得多。
- 当线性表中的元素个数变化较大或者根本不知道有多大时,最好用单链表结构。这样可以不需要考虑存储空间的大小问题。而如果事先知道线性表的大致长度,比如一年12个月,一周就是星期一至星期日共七天,这种用顺序存储结构效率会高很多。
总之,线性表的顺序存储结构和单链表结构各有其优缺点,不能简单的说哪个好,哪个不好,需要根据实际情况,来综合平衡采用哪种数据结构更能满足和达到需求和性能。
7. 静态链表
C语言具有的指针能力,使得它可以非常容易地操作内存中的地址和数据,这比其他高级语言更加灵活方便。后来的面向对象语言,如Java、 C#等,虽不使用指针,但因为启用了对象引用机制,从某种角度也间接实现了指针的某些作用。但对于一些语言,如Basic、Fortran等早期的编程高级语言,由于没有指针,链表结构按照前面我们的讲法,它就没法实现了。怎么办呢?
有人就想出来用数组来代替指针描述单链表。真是不得不佩服他们的智慧,我们来看看他是怎么做到的。
首先我们让数组的元素都是由两个数据域组成,data和cur。也就是说,数组的每个下标都对应一个data和一个cur。数据域data,用来存放数据元素,也就是通常我们要处理的数据;而cur相当于单链表中的next指针,存放该元素的后继在数组中的下标,我们把cur叫做游标。
我们把这种用数组描述的链表叫做静态链表,这种描述方法还有起名叫做游标实现法。
为了方便插入数据,我们通常会把数组建立得大一些,以便有一些空闲空间可以便于插入时不至于溢出。
1 |
|
另外我们对数组第一个和最后一 个元素作为特殊元素处理,不存数据。我们通常把未被使用的数组元素称为备用链表。而数组第一个元素,即下标为0的元素的cur就存放备用链表的第一个结点的下标;而数组的最后一个元素的cur则存放第一个有数值的元素的下标,相当于单链表中的头结点作用,当整个链表为空时,则为0。如下图所示。
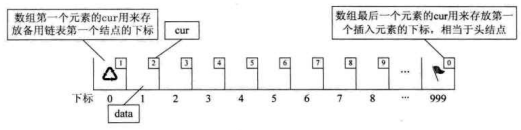
此时的图示相当于初始化的数组状态,见下面代码:
1 | /* 将一维数组space中各分量链成一个备用链表,space[0].cur为头指针,"0"表示空指针 */ |
假设我们已经将数据存入静态链表,比如分别存放着“甲”、“乙”、丁”、“戊”、“已"、庚”等数据,则它将处于如下图所示这种状态。
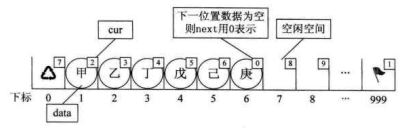
此时“甲”这里就存有下一元素“乙"的游标 2,,"乙"则存有下一元素“丁”的下标 3。而“庚"是最后一个有值元素,所以它的cur设置为 0。而最后一个元素的cur则因“甲”是第一有值元素而存有它的下标为 1。而第一个元素则因空闲空间的第一个元素下标为 7,所以它的cur存有 7。
7.1 静态链表的插入操作
现在我们来看看如何实现元素的插入。
静态链表中要解决的是:如何用静态模拟动态链表结构的存储空间的分配,需要时申请,无用时释放。
前面说过,在动态链表中,结点的申请和释放分别借用malloc ()和free()两个函数来实现。在静态链表中,操作的是数组,不存在像动态链表的结点申请和释放问题,所以我们需要自己实现这两个函数,才可以做插入和删除的操作。
为了辨明数组中哪些分量未被使用,解决的办法是将所有未被使用过的及已被删除的分量用游标链成一个备用的链表,每当进行插入时,便可以从备用链表上取得第一个结点作为待插入的新结点。
1 | /* 若备用空间链表非空,则返回分配的结点下标,否则返回0 */ |
这段代码有意思,一方面它的作用就是返回一个下标值,这个值就是数组头元素的cur存的第一个空闲的下标。从上面的图示例子来看,其实就是返回7。
那么既然下标为7的分量准备要使用了,就得有接替者,所以就把分量7的cur值赋值给头元素,也就是把8给space[0].cur, 之后就可以继续分配新的空闲分量,实现类似malloc()函数的作用。
现在我们如果需要在“乙"和“丁”之间,插入一个值为“丙"的元素,按照以前顺序存储结构的做法,应该要把“丁”、“戊"、“己”、“庚"这些元素都往后移一位。但目前不需要,因为我们有了新的手段。
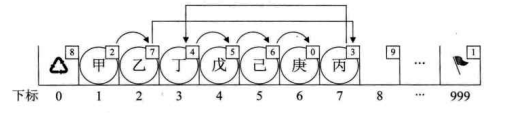
新元素“丙”, 想插队是吧?可以,你先悄悄地在队伍最后一排第7个游标位置待着,我一会就能帮你搞定。我接着找到了“乙”, 告诉他,你的cur不是游标为3的“丁”了,这点小钱,意思意思,你把你的下一位的游标改为7就可以了。"乙”把cur值改了。此时再回到“丙"那里,说你把你的cur改为3。就这样,在绝大多数人都不知道的情况下,整个排队的次序发生了改变(如下图所示)。
实现代码如下:
1 | Status ListInsert(StaticLinkList L, int i, ElemType e) |
- 当我们执行插入语句时,我们的目的是要在“乙"和“丁”之间插入“丙"。调用代码时,输入
i值为3。 - 第 4 行让
k=MAX_SIZE- 1=999。 - 第 7 行,
j=Malloc._SSL (L) =7。此时下标为 0 的cur也因为 7 要被占用而更改备用链表的值为 8。 - 第 11~12 行,
for循环由 1 到 2,执行两次。代码k = L[k].cur;使得k=999,得到k=L[999].cur=1,再得到k=L[1].cur=2。 - 第 13 行,
L[j].cur = L[k].cur;,因j=7,而k=2得到L[7].cur=L[2].cur=3。这就是刚才我说的让“丙"把它的cur改为 3 的意思。 - 第 14 行,
L[k].cur = j;意思就是L[2].cur=7。 也就是让“乙”把它的cur改为指向“丙"的下标 7。
就这样,我们实现了在数组中,实现不移动元素,却插入了数据的操作(如下图所示)。没理解可能觉得有些复杂,理解了,也就那么回事。
7.2 静态链表的删除操作
和前面一样,删除元素时,原来是需要释放结点的函数free()。 现在我们也得自己实现它:
1 | /* 删除在L中第i个数据元素e */ |
有了刚才的基础,这段代码就很容易理解了。前面代码都一样,for循环因为i=1而不操作,j=k[999].cur=1,L[k].cur=L[j].cur也就是L[999]cur=L[1].cur=2。 这其实就是告诉计算机现在“甲” 已经离开了,“乙”才是第一个元素。FreSSL(L, j);是什么意思呢?来看代码:
1 | /* 将下标为k的空闲结点回收到备用链表 */ |
意思就是“甲”现在要走,这个位置就空出来了,也就是,未来如果有新人来,最优先考虑这里,所以原来的第一一个空位分量,即下标是 8 的分量,它降级了,把 8 给“甲”所在下标为 1 的分量的cur,也就是space[1].cur=space[0].cur=8,而space[0].cur=k=1其实就是让这个删除的位置成为第一个优先空位,把它存入第一个元素的cur中,如下图所示。

当然,静态链表也有相应的其他操作的相关实现。比如我们代码中的ListLength就是一个,来看代码。
1 | /* 初始条件:静态链表L已存在。操作结果:返回L中数据元素的个数 */ |
另外一些操作和线性表的基本操作相同,实现也不复杂,在这里就不讲解了。
7.3 静态链表的优缺点
优点:
- 在插入和删除操作时,只需要修改游标,不需要移动元素,从而改进了在顺序存储结构中的插入和删除操作需要移动大量元素的缺点
缺点:
- 没有解决连续存储分配带来的表长难以确定的问题
- 失去了顺序存储结构随机存取的特性
总的来说,静态链表其实是为了给没有指针的高级语言设计的一种实现单链表能力的方法。尽管大家不一定会用得上,但这样的思考方式是非常巧妙的,应该理解其思想,以备不时之需。
8. 循环链表
对于单链表,由于每个结点只存储了向后的指针,到了尾标志就停止了向后链的操作,这样,当中某一结点就无法找到它的前驱结点了,就像我们刚才说的,不能回到从前。
比如,你是一业务员,家在上海。需要经常出差,行程就是上海到北京一路上的城市,找客户谈生意或分公司办理业务。你从上海出发,乘火车路经多个城市停留后,再乘飞机返回上海,以后,每隔一段时间,你基本还要按照这样的行程开展业务,如下图所示。

有一次,你先到南京开会,接下来要对以上的城市走一遍, 此时有人对你说,不行,你得从上海开始,因为上海是第一站。你会对这人说什么?神经病。哪有这么傻的,直接回上海根本没有必要,你可以从南京开始,下一站蚌埠,直到北京,之后再考虑走完上海及苏南的几个城市。显然这表示你是从当中一结点开始遍历整个链表,这都是原来的单链表结构解决不了的问题。
事实上,把北京和上海之间连起来,形成一个环就解决了前面所面临的困难。这就是我们现在要讲的循环链表。
将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表(circular linked list)。
从刚才的例子可以总结出,循环链表解决了一个很麻烦的问题。如何从当中一个结点出发,访问到链表的全部结点。
为了使空链表与非空链表处理一致, 我们通常设一个头结点,当然,这并不是说,循环链表一定要头结点,这需要注意。循环链表带有头结点的空链表如下图所示:
对于非空的循环链表就如下图所示。
 其实循环链表和单链表的主要差异就在于循环的判断条件上,原来是判断
其实循环链表和单链表的主要差异就在于循环的判断条件上,原来是判断p->next是否为空,现在则是p->next不等于头结点,则循环未结束。
在单链表中,我们有了头结点时,我们可以用 O(1) 的时间访问第一个结点,但对于要访问到最后一个结点,却需要 O(n) 时间,因为我们需要将单链表全部扫描一遍。
有没有可能用 O(1) 的时间由链表指针访问到最后一一个结点呢?当然可以。
不过我们需要改造一下这个循环链表,不用头指针,而是用指向终端结点的尾指针来表示循环链表(如下图所示),此时查找开始结点和终端结点都很方便了。

从上图中可以看到,终端结点用尾指针rear指示,则查找终端结点的时间复杂度是O(1),而开始结点,其实就是rear->next->next,其时间复杂也为O(1)。
举个程序的例子,要将两个循环链表合并成一个表时, 有了尾指针就非常简单了。比如下面的这两个循环链表,它们的尾指针分别是rearA和rearB,如下图所示。
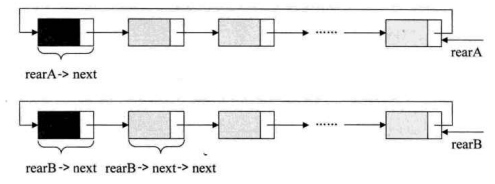
要想把它们合并,只需要如下的操作即可,如下图所示。
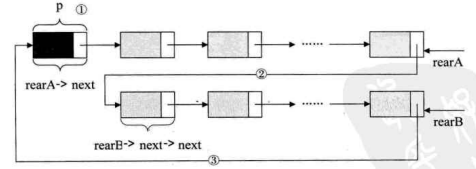
1 | p=rearA->next; /* 保存A表的头结点,即 ① */ |
9. 双向链表
继续我们刚才的例子,你平时都是从上海一路停留到北京的,可是这一次,你得先到北京开会,谁叫北京是首都呢,会就是多。开完会后,你需要例行公事,走访各个城市,此时你怎么办?
有人又出主意了,你可以先飞回上海,一路再乘火车走遍这几个城市,到了北京后,你再飞回上海。

你会感慨,人生中为什么总会有这样出馊主意的人存在呢?真要气死人才行。哪来这么麻烦,我一路从北京坐火车或汽车回去不就完了吗。如下图所示:

对呀,其实生活中类似的小智慧比比皆是,并不会那么的死板教条。我们的单链表,总是从头到尾找结点,难道就不可以正反遍历都可以吗?当然可以,只不过需要加点东西而已。
我们在单链表中,有了next指针,这就使得我们要查找下一结点的时间复杂度为O(1)。可是如果我们要查找的是上一结点的话,那最坏的时间复杂度就是 O(n) 了,因为我们每次都要从头开始遍历查找。
双向链表(double linked list)是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。 所以在双向链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前驱。
1 | /* 线性表的双向链表存储结构 */ |
既然单链表也可以有循环链表,那么双向链表当然也可以是循环表。
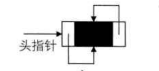
双向链表的循环带头结点的空链表如下图所示。
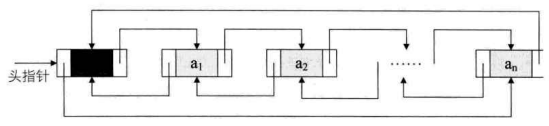
非空的循环的带头结点的双向链表如下图所示。
由于这是双向链表,那么对于链表中的某一个结点p,它的后继的前驱是谁?当然还是它自已。它的前驱的后继自然也是它自己,即:
1 | p->next->prior = p = p->prior->next |
这就如同上海的下一站是苏州,那么上海的下一站的前一站是哪里? 这里有点废话的感觉。
双向链表是单链表中扩展出来的结构,所以它的很多操作是和单链表相同的,比如求长度的ListLength,查找元素的GetElem,获得元素位置的LocateElem等,这些操作都只要涉及一个方向的指针即可,另一指针多了也不能提供什么帮助。
就像人生一样,想享乐就得先努力,欲收获就得付代价。双向链表既然是比单链表多了如可以反向遍历查找等数据结构,那么也就需要付出一些小的代价:在插入和删除时,需要更改两个指针变量。
插入操作时,其实并不复杂,不过顺序很重要,千万不能写反了。
我们现在假设存储元素e的结点为s,要实现将结点s插入到结点p和p->next之间需要下面几步,如下图所示。
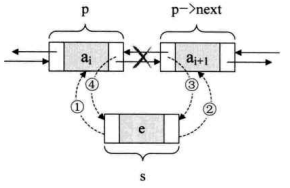
1 | s -> prior = p; /* 把p赋值給s的前驱,如图中 ① */ |
关键在于它们的顺序,由于第②步和第③步都用到了p->next。如果第④步先执行,则会使得p->next提前变成了s,使得插入的工作完不成。所以我们不妨把上面这张图在理解的基础上记忆,顺序是先搞定s的前驱和后继,再搞定后结点的前驱,最后解决前结点的后继。
如果插入操作理解了,那么删除操作,就比较简单了。
若要删除结点p,只需要下面两步骤,如下图所示。
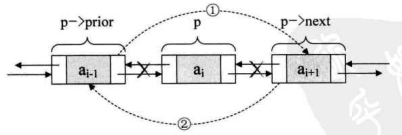
1 | p->prior->next=p->next; /* 把p->next赋值给p->prior的后继,如图中 ① */ |
双向链表相对于单链表来说,要更复杂一些,毕竟它多了prior指针,对于插入和删除时,需要格外小心。另外它由于每个结点都需要记录两份指针,所以在空间上是要占用略多一些的。 不过,由于它良好的对称性,使得对某个结点的前后结点的操作带来了方便,可以有效提高算法的时间性能。说白了,就是用空间来换时间。
10. 总结
链式存储结构具有不受固定的存储空间限制,可以比较快捷的插入和删除。
线性表的这两种结构其实是后面其他数据结构的基础,把它们学明白了,对后面的学习有着至关重要的作用。




