一、官网介绍
数据库、缓存和消息中间件。 它支持多种类型的数据结构,如字符串(strings), 散列(hashes),列表(lists),集合(sets),有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
二、Redis常用的五大数据类型
Redis常用的五大数据类型为:String(字符串)、List(列表)、Set(集合)、Hash(哈希,类似java里的map)、Zset(sorted set:有序集合)。
1. String(字符串)
String 是 Redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。512MB。
1.1 常用命令
1 2 127.0.0.1:6379> set key1 v1 OK
1 2 127.0.0.1:6379> get key1 "v1"
1 2 127.0.0.1:6379> keys * 1) "key1"
1 2 127.0.0.1:6379> EXISTS key1 (integer) 1
append : 追加字符串,如果当前key不存在,就相当于‘set key’
1 2 3 4 127.0.0.1:6379> APPEND key1 "hello" (integer) 7 127.0.0.1:6379> get key1 "v1hello"
1 2 127.0.0.1:6379> STRLEN key1 (integer) 7
1 2 3 4 5 6 7 8 127.0.0.1:6379> set views 0 OK 127.0.0.1:6379> get views "0" 127.0.0.1:6379> incr views (integer) 1 127.0.0.1:6379> get views "1"
1 2 3 4 127.0.0.1:6379> decr views (integer) 0 127.0.0.1:6379> get views "0"
1 2 3 4 127.0.0.1:6379> incrby views 3 (integer) 3 127.0.0.1:6379> get views "3"
1 2 3 4 127.0.0.1:6379> decrby views 5 (integer) -2 127.0.0.1:6379> get views "-2"
getrange : 获取字符串指定下标范围的元素
1 2 3 4 5 6 7 8 127.0.0.1:6379> set key1 "hello,redis" OK 127.0.0.1:6379> get key1 "hello,redis" 127.0.0.1:6379> GETRANGE key1 0 5 "hello," 127.0.0.1:6379> GETRANGE key1 0 -1 "hello,redis"
1 2 3 4 5 6 7 8 127.0.0.1:6379> set key2 "abcdefghijklmn" OK 127.0.0.1:6379> get key2 "abcdefghijklmn" 127.0.0.1:6379> SETRANGE key2 1 xx (integer) 14 127.0.0.1:6379> get key2 "axxdefghijklmn"
setex : 设置过期时间ttl : 查看剩余过期时间
1 2 3 4 5 # 设置“key3”30秒后过期 127.0.0.1:6379> setex key3 30 "hello" OK 127.0.0.1:6379> ttl key3 (integer) 20
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> setnx key4 v1 (integer) 1 127.0.0.1:6379> keys * 1) "key4" 2) "key2" 3) "key1" 127.0.0.1:6379> setnx key4 v3 (integer) 0 127.0.0.1:6379> get key4 "v1"
1 2 3 4 5 6 127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 OK 127.0.0.1:6379> keys * 1) "k3" 2) "k1" 3) "k2"
1 2 3 4 127.0.0.1:6379> mget k1 k2 k3 1) "v1" 2) "v2" 3) "v3"
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> keys * 1) "k3" 2) "k1" 3) "k2" 127.0.0.1:6379> msetnx k1 v2 k4 v4 # msetnx 是一个原子性的操作,要么一起成功,要么一起失败 (integer) 0 127.0.0.1:6379> get k1 "v1" 127.0.0.1:6379> get k4 (nil)
1 2 3 4 5 6 # user:{id}:{filed} 127.0.0.1:6379> mset user:1:name zhangsan user:1:age 2 OK 127.0.0.1:6379> mget user:1:name user:1:age 1) "zhangsan" 2) "2"
1 2 3 4 127.0.0.1:6379> set user:1 {name:zhangsan,age:26} OK 127.0.0.1:6379> get user:1 "{name:zhangsan,age:26}"
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> getset key1 hello (nil) 127.0.0.1:6379> get key1 "hello" 127.0.0.1:6379> getset key1 redis "hello" 127.0.0.1:6379> get key1 "redis"
想知道更多详细的命令可以访问: Redis命令详解
1.2 使用场景
1.3 数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList ,采用预分配冗余空间的方式来减少内存的频繁分配。
2. List(列表)
Redis 的列表类型是简单的字符串列表,按照插入顺序排序,可以添加一个元素到列表的头部(左边)或者尾部(右边)。双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
2.1 常用命令
1 2 3 4 5 6 7 127.0.0.1:6379> lrange list 0 -1 1) "three" 2) "two" 3) "one" 127.0.0.1:6379> lrange list 0 1 1) "three" 2) "two"
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> lrange list 0 -1 1) "three" 2) "two" 3) "one" 127.0.0.1:6379> lindex list 0 "three" 127.0.0.1:6379> lindex list 1 "two" 127.0.0.1:6379> lindex list 3 (nil)
1 2 3 4 5 6 127.0.0.1:6379> lrange list 0 -1 1) "three" 2) "two" 3) "one" 127.0.0.1:6379> llen list (integer) 3
1 2 3 4 5 6 7 8 127.0.0.1:6379> lpush list one (integer) 1 127.0.0.1:6379> lpush list two three (integer) 3 127.0.0.1:6379> lrange list 0 -1 1) "three" 2) "two" 3) "one"
1 2 3 4 5 6 7 8 127.0.0.1:6379> rpush list one (integer) 1 127.0.0.1:6379> rpush list two three (integer) 3 127.0.0.1:6379> lrange list 0 -1 1) "one" 2) "two" 3) "three"
1 2 3 4 5 6 7 8 9 127.0.0.1:6379> lrange list 0 -1 1) "one" 2) "two" 3) "three" 127.0.0.1:6379> lpop list "one" 127.0.0.1:6379> lrange list 0 -1 1) "two" 2) "three"
1 2 3 4 5 6 7 8 9 127.0.0.1:6379> lrange list 0 -1 1) "three" 2) "two" 3) "one" 127.0.0.1:6379> rpop list "one" 127.0.0.1:6379> lrange list 0 -1 1) "three" 2) "two"
1 2 3 4 5 6 7 8 9 127.0.0.1:6379> lrange list 0 -1 1) "three" 2) "two" 3) "one" 127.0.0.1:6379> lrem list 1 one (integer) 1 127.0.0.1:6379> lrange list 0 -1 1) "three" 2) "two"
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> lrange list 0 -1 1) "three" 2) "two" 3) "one" 4) "one" 127.0.0.1:6379> lrem list 2 one (integer) 2 127.0.0.1:6379> lrange list 0 -1 1) "three" 2) "two"
1 2 3 4 5 6 7 8 9 10 11 12 127.0.0.1:6379> rpush mylist "hello" "hello1" "hello2" "hello3" (integer) 4 127.0.0.1:6379> lrange mylist 0 -1 1) "hello" 2) "hello1" 3) "hello2" 4) "hello3" 127.0.0.1:6379> ltrim mylist 1 2 OK 127.0.0.1:6379> lrange mylist 0 -1 1) "hello1" 2) "hello2"
rpoplpush : 移除列表最后一个元素,将该元素移动到新的列表中(新列表不存在时会自动创建)
1 2 3 4 5 6 7 8 9 10 11 127.0.0.1:6379> lrange mylist 0 -1 1) "hello" 2) "hello1" 3) "hello2" 127.0.0.1:6379> rpoplpush mylist myotherlist "hello2" 127.0.0.1:6379> lrange mylist 0 -1 1) "hello" 2) "hello1" 127.0.0.1:6379> lrange myotherlist 0 -1 1) "hello2"
lset : 将列表中指定下标的值替换为另一个值(更新操作,更新不存在的下标会报错)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0.0.1:6379> exists list (integer) 0 127.0.0.1:6379> lset list 0 item (error) ERR no such key 127.0.0.1:6379> lpush list value1 (integer) 1 127.0.0.1:6379> lrange list 0 -1 1) "value1" 127.0.0.1:6379> lset list 0 item OK 127.0.0.1:6379> lrange list 0 -1 1) "item" 127.0.0.1:6379> lset list 1 other (error) ERR index out of range
linsert : 将某个具体的值插入到列表中指定元素的前面或后面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 127.0.0.1:6379> lrange mylist 0 -1 1) "hello" 2) "world" 127.0.0.1:6379> linsert mylist before "world" "other" (integer) 3 127.0.0.1:6379> lrange mylist 0 -1 1) "hello" 2) "other" 3) "world" 127.0.0.1:6379> linsert mylist after "world" "new" (integer) 4 127.0.0.1:6379> lrange mylist 0 -1 1) "hello" 2) "other" 3) "world" 4) "new"
2.2 使用场景
List 类型经常会被用于消息队列的服务,以完成多程序之间的消息交换
消息队列(lpush rpop)
栈(lpush lpop)
2.3 数据结构
List的数据结构为快速链表 quickList 。
3. Set(集合)
set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。复杂度都是O(1)。
3.1 常用命令
1 2 3 4 127.0.0.1:6379> smembers myset 1) "world" 2) "hello" 3) "redis"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 127.0.0.1:6379> smembers myset 1) "world" 2) "hello" 3) "redis" 127.0.0.1:6379> sadd myset "Redis" (integer) 1 127.0.0.1:6379> smembers myset 1) "Redis" 2) "world" 3) "hello" 4) "redis" 127.0.0.1:6379> sadd myset "hello1" "hello2" (integer) 2 127.0.0.1:6379> smembers myset 1) "redis" 2) "hello" 3) "world" 4) "Redis" 5) "hello1" 6) "hello2"
sismember : 判断集合中是否存在指定元素
1 2 3 4 5 6 7 8 9 10 11 127.0.0.1:6379> smembers myset 1) "redis" 2) "hello" 3) "world" 4) "Redis" 5) "hello1" 6) "hello2" 127.0.0.1:6379> sismember myset hello1 (integer) 1 127.0.0.1:6379> sismember myset hello3 (integer) 0
1 2 3 4 5 6 7 8 9 127.0.0.1:6379> smembers myset 1) "hello" 2) "world" 3) "Redis" 4) "redis" 5) "hello1" 6) "hello2" 127.0.0.1:6379> scard myset (integer) 6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 127.0.0.1:6379> smembers myset 1) "hello" 2) "world" 3) "Redis" 4) "redis" 5) "hello1" 6) "hello2" 127.0.0.1:6379> srem myset world (integer) 1 127.0.0.1:6379> smembers myset 1) "hello" 2) "Redis" 3) "redis" 4) "hello1" 5) "hello2"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 127.0.0.1:6379> smembers myset 1) "hello" 2) "Redis" 3) "redis" 4) "hello1" 5) "hello2" 127.0.0.1:6379> srandmember myset "hello" 127.0.0.1:6379> srandmember myset "hello2" 127.0.0.1:6379> srandmember myset 2 1) "Redis" 2) "hello" 127.0.0.1:6379> srandmember myset 2 1) "redis" 2) "hello2"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 127.0.0.1:6379> smembers myset 1) "hello" 2) "Redis" 3) "redis" 4) "hello1" 5) "hello2" 127.0.0.1:6379> spop myset "hello2" 127.0.0.1:6379> smembers myset 1) "hello" 2) "Redis" 3) "redis" 4) "hello1" 127.0.0.1:6379> spop myset "Redis" 127.0.0.1:6379> smembers myset 1) "hello" 2) "redis" 3) "hello1"
smove : 将集合中指定的元素移动到另一个集合中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0.0.1:6379> smembers myset 1) "hello" 2) "redis" 3) "hello1" 127.0.0.1:6379> smembers myset2 1) "hello" 127.0.0.1:6379> smove myset myset2 "hello1" (integer) 1 127.0.0.1:6379> smembers myset 1) "hello" 2) "redis" 127.0.0.1:6379> smembers myset2 1) "hello" 2) "hello1"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0.0.1:6379> smembers set1 1) "c" 2) "b" 3) "a" 127.0.0.1:6379> smembers set2 1) "e" 2) "c" 3) "d" 127.0.0.1:6379> sdiff set1 set2 1) "a" 2) "b" 127.0.0.1:6379> sdiff set2 set1 1) "e" 2) "d"
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> smembers set1 1) "c" 2) "b" 3) "a" 127.0.0.1:6379> smembers set2 1) "e" 2) "c" 3) "d" 127.0.0.1:6379> sinter set1 set2 1) "c"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0.0.1:6379> smembers set1 1) "c" 2) "b" 3) "a" 127.0.0.1:6379> smembers set2 1) "e" 2) "c" 3) "d" 127.0.0.1:6379> sunion set1 set2 1) "a" 2) "b" 3) "c" 4) "e" 5) "d"
3.2 使用场景
用户之间的共同关注、共同爱好、二度好友
推荐好友
六度分割理论
3.3 数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
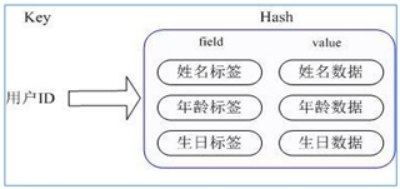
4. Hash(哈希)
Redis hash 是一个键值对集合。Map<String,Object>。
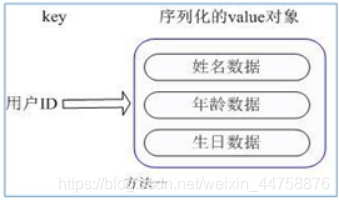
举个例子,用户ID为查找的 key ,存储的 value 用户对象包含姓名,年龄,生日等信息,如果用普通的 key/value 结构来存储,主要有以下2种存储方式:
每次修改用户的某个属性需要,先反序列化改好后再序列化回去,开销较大。
用户ID数据冗余。
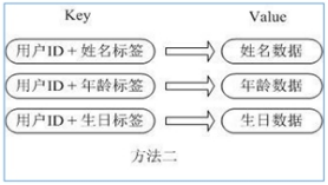
通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。
4.1 常用命令
1 2 3 127.0.0.1:6379> hkeys myhash 1) "field1" 2) "field2"
1 2 3 127.0.0.1:6379> hvals myhash 1) "hello" 2) "world"
hset : 设置hash的field-value值
1 2 3 4 5 6 127.0.0.1:6379> hset myhash field1 "hello" (integer) 1 127.0.0.1:6379> hkeys myhash 1) "field1" 127.0.0.1:6379> hvals myhash 1) "hello"
hmset : 设置多个hash的field-value值
1 2 3 4 5 6 7 8 127.0.0.1:6379> hmset myhash field1 hello field2 world OK 127.0.0.1:6379> hkeys myhash 1) "field1" 2) "field2" 127.0.0.1:6379> hvals myhash 1) "hello" 2) "world"
1 2 127.0.0.1:6379> hget myhash field1 "hello"
hmget : 获取hash中指定的多个value
1 2 3 127.0.0.1:6379> hmget myhash field1 field2 1) "hello" 2) "world"
1 2 3 4 5 127.0.0.1:6379> hgetall myhash 1) "field1" 2) "hello" 3) "field2" 4) "world"
hdel : 删除hash中指定的field(对应的value同样被删除)
1 2 3 4 5 6 7 8 9 10 11 12 127.0.0.1:6379> hkeys myhash 1) "field1" 2) "field2" 127.0.0.1:6379> hvals myhash 1) "hello" 2) "world" 127.0.0.1:6379> hdel myhash field1 (integer) 1 127.0.0.1:6379> hkeys myhash 1) "field2" 127.0.0.1:6379> hvals myhash 1) "world"
1 2 3 4 5 6 7 8 127.0.0.1:6379> hkeys myhash 1) "field2" 2) "field1" 127.0.0.1:6379> hvals myhash 1) "world" 2) "hello" 127.0.0.1:6379> hlen myhash (integer) 2
hexists : 判断hash中的指定元素是否存在
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> hkeys myhash 1) "field2" 2) "field1" 127.0.0.1:6379> hvals myhash 1) "world" 2) "hello" 127.0.0.1:6379> hexists myhash field1 (integer) 1 127.0.0.1:6379> hexists myhash field3 (integer) 0
hincrby : 使hash中指定field的值增量
1 2 3 4 5 6 7 8 9 10 11 12 127.0.0.1:6379> hset myhash field1 3 (integer) 1 127.0.0.1:6379> hincrby myhash field1 1 (integer) 4 127.0.0.1:6379> hgetall myhash 1) "field1" 2) "4" 127.0.0.1:6379> hincrby myhash field1 -1 (integer) 3 127.0.0.1:6379> hgetall myhash 1) "field1" 2) "3"
hsetnx : 设置hash的field-value值,如果field存在则不能设置,如果field不存在可以设置
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> hsetnx myhash field1 hello (integer) 1 127.0.0.1:6379> hgetall myhash 1) "field1" 2) "hello" 127.0.0.1:6379> hsetnx myhash field1 hello1 (integer) 0 127.0.0.1:6379> hgetall myhash 1) "field1" 2) "hello"
4.2 使用场景
hash更适合存储对象,而string更适合存储字符串
用户信息,经常变动的信息
4.3 数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。
5. Zset(sorted set:有序集合)
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
5.1 常用命令
1 2 3 4 5 6 7 127.0.0.1:6379> zrange salary 0 -1 1) "wangwu" 2) "zhangsan" 3) "lisi" 127.0.0.1:6379> zrange salary 0 1 1) "wangwu" 2) "zhangsan"
1 2 3 4 127.0.0.1:6379> zadd myset 1 one (integer) 1 127.0.0.1:6379> zadd myset 2 two 3 three (integer) 2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 127.0.0.1:6379> zadd salary 2500 zhangsan (integer) 1 127.0.0.1:6379> zadd salary 5000 lisi (integer) 1 127.0.0.1:6379> zadd salary 1000 wangwu (integer) 1 127.0.0.1:6379> zrangebyscore salary -inf +inf 1) "wangwu" 2) "zhangsan" 3) "lisi" 127.0.0.1:6379> zrangebyscore salary -inf +inf withscores 1) "wangwu" 2) "1000" 3) "zhangsan" 4) "2500" 5) "lisi" 6) "5000" 127.0.0.1:6379> zrangebyscore salary -inf +2500 withscores 1) "wangwu" 2) "1000" 3) "zhangsan" 4) "2500"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0.0.1:6379> zrevrange salary 0 -1 1) "lisi" 2) "zhangsan" 3) "zhaoliu" 4) "wangwu" 127.0.0.1:6379> zrevrange salary 0 -1 withscores 1) "lisi" 2) "5000" 3) "zhangsan" 4) "2500" 5) "zhaoliu" 6) "2000" 7) "wangwu" 8) "1000"
1 2 3 4 5 6 7 8 9 127.0.0.1:6379> zrange salary 0 -1 1) "wangwu" 2) "zhangsan" 3) "lisi" 127.0.0.1:6379> zrem salary wangwu (integer) 1 127.0.0.1:6379> zrange salary 0 -1 1) "zhangsan" 2) "lisi"
1 2 3 4 5 127.0.0.1:6379> zrange salary 0 -1 1) "zhangsan" 2) "lisi" 127.0.0.1:6379> zcard salary (integer) 2
1 2 3 4 5 6 7 8 9 10 11 127.0.0.1:6379> zrevrange salary 0 -1 withscores 1) "lisi" 2) "5000" 3) "zhangsan" 4) "2500" 5) "zhaoliu" 6) "2000" 7) "wangwu" 8) "1000" 127.0.0.1:6379> zcount salary 2000 5000 (integer) 3
5.2 使用场景
存储班级成绩表、工资表排序
带权重排序,普通消息为1,重要消息为2
排行榜应用实现、取TopN
5.3 数据结构
SortedSet(zset) 是 Redis 提供的一个非常特别的数据结构,一方面它等价于 Java 的数据结构Map<String, Double>,可以给每一个元素 value 赋予一个权重 score ,另一方面它又类似于TreeSet,内部的元素会按照权重 score 进行排序,可以得到每个元素的名次,还可以通过 score 的范围来获取元素的列表。
zset 底层使用了两个数据结构:
hash ,hash 的作用就是关联元素 value 和权重 score ,保障元素 value 的唯一性,可以通过元素 value 找到相应的 score 值。
跳跃表,跳跃表的目的在于给元素 value 排序,根据 score 的范围获取元素列表。
5.4 跳跃表(跳表)
5.4.1 简介
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。 Redis 采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
5.4.2 实例
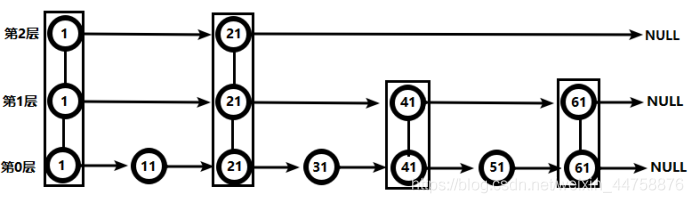
对比有序链表和跳跃表,从链表中查询出“51”:
有序链表
跳跃表
从此可以看出跳跃表比有序链表效率要高。
三、Redis的三种特殊数据类型
Geospatial(地理信息)、HyperLogLog(基数统计)、Bitmaps
1. Geospatial(地理信息)
Redis 3.2 中增加了对 GEO 类型的支持。GEO 是 Geographic(地理信息)的缩写。该类型,就是元素的 2 维坐标,在地图上就是经纬度。 redis 基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度 Hash 等常见操作。
1.1 常用命令
geoadd : 添加地理位置,两级无法直接添加(一般会下载城市数据通过java程序一次性导入),有效的经度是 -180 度到 180 度,有效的纬度是 -85.05112878 度到 85.05112878 度,当坐标位置超出指定范围时,该命令将会返回一个错误。已经添加的数据,是无法再次往里面添加的。
1 2 3 4 5 6 7 8 127.0.0.1:6379> geoadd china:city 116.405285 39.904989 beijing (integer) 1 127.0.0.1:6379> geoadd china:city 121.472644 31.231706 shanghai (integer) 1 127.0.0.1:6379> geoadd china:city 114.085947 22.547 shenzhen (integer) 1 127.0.0.1:6379> geoadd china:city 113.280637 23.125178 guangzhou (integer) 1
1 2 3 4 5 6 7 8 127.0.0.1:6379> geopos china:city beijing 1) 1) "116.40528291463851929" 2) "39.9049884229125027" 127.0.0.1:6379> geopos china:city beijing shanghai 1) 1) "116.40528291463851929" 2) "39.9049884229125027" 2) 1) "121.47264629602432251" 2) "31.23170490709807012"
geodist : 获取两个位置之间的直线距离
m 表示单位为米 [ 默认值 ]
km 表示单位为千米
mi 表示单位为英里
ft 表示单位为英尺
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> geodist china:city beijing shanghai "1067597.9668" 127.0.0.1:6379> geodist china:city beijing shanghai km "1067.5980" 127.0.0.1:6379> geodist china:city beijing shanghai mi "663.3763" 127.0.0.1:6379> geodist china:city beijing shanghai ft "3502618.0013" 127.0.0.1:6379> geodist china:city beijing guangzhou km "1889.3706"
georadius : 以给定的维度为中心,找出半径内的元素
withdist : 显示到中心位置的距离
withcoord : 显示半径内元素的坐标
count : 限定显示几个元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 127.0.0.1:6379> georadius china:city 110 30 1000 km 1) "shenzhen" 2) "guangzhou" 127.0.0.1:6379> georadius china:city 110 30 900 km 1) "guangzhou" 127.0.0.1:6379> georadius china:city 110 30 1000 km withdist 1) 1) "shenzhen" 2) "923.4929" 2) 1) "guangzhou" 2) "831.2636" 127.0.0.1:6379> georadius china:city 110 30 900 km withdist 1) 1) "guangzhou" 2) "831.2636" 127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord 1) 1) "shenzhen" 2) 1) "114.08594459295272827" 2) "22.54699993773966327" 2) 1) "guangzhou" 2) 1) "113.28063815832138062" 2) "23.12517743834835215" 127.0.0.1:6379> georadius china:city 110 30 1000 km withdist withcoord 1) 1) "shenzhen" 2) "923.4929" 3) 1) "114.08594459295272827" 2) "22.54699993773966327" 2) 1) "guangzhou" 2) "831.2636" 3) 1) "113.28063815832138062" 2) "23.12517743834835215" 127.0.0.1:6379> georadius china:city 110 30 1000 km withdist withcoord count 1 1) 1) "guangzhou" 2) "831.2636" 3) 1) "113.28063815832138062" 2) "23.12517743834835215"
georadiusbymember : 以指定元素为中心,找出半径内的元素
1 2 3 127.0.0.1:6379> georadiusbymember china:city beijing 1500 km 1) "shanghai" 2) "beijing"
geohash : 返回一个或多个位置元素,以Geohash表示(会返回一个11个字符的Geohash字符串)
1 2 3 4 # 将二维的经纬度转换为一维的字符串,如果两个字符串越接近,则距离越近 127.0.0.1:6379> geohash china:city beijing guangzhou 1) "wx4g0b7xrt0" 2) "ws0e9cb3yj0"
GEO底层的实现原理其实就是Zset,可以使用Zset命令来操作GEO
1 2 3 4 5 6 7 8 9 10 11 127.0.0.1:6379> zrange china:city 0 -1 1) "shenzhen" 2) "guangzhou" 3) "shanghai" 4) "beijing" 127.0.0.1:6379> zrem china:city beijing (integer) 1 127.0.0.1:6379> zrange china:city 0 -1 1) "shenzhen" 2) "guangzhou" 3) "shanghai"
1.2 使用场景
2. HyperLogLog(基数统计)
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站 PV(PageView 页面访问量),可以使用 Redis 的 incr 、incrby 轻松实现。
数据存储在 MySQL 表中,使用 distinct count 计算不重复个数
使用 Redis 提供的 hash、set、bitmaps 等数据结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
什么是基数?
2.1 常用命令
pfadd : 添加指定元素到HyperLogLog中(如果执行命令后HyperLogLog估计的近似基数发生变化,则返回1,否则返回0)
1 2 3 4 5 6 127.0.0.1:6379> pfadd mykey a b c d e f g h i j k l m (integer) 1 127.0.0.1:6379> pfadd mykey2 f s v z a b i j l (integer) 1 127.0.0.1:6379> pfadd mykey a (integer) 0
pfcount : 统计HyperLogLog的元素个数,计算HyperLogLog的近似基数(可以计算多个HyperLogLog,比如用HyperLogLog存储每天的UV,计算一周的UV可以使用7天的UV合并计算即可)
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> pfadd mykey a b c d e f g h i j k l m (integer) 1 127.0.0.1:6379> pfcount mykey (integer) 13 127.0.0.1:6379> pfadd mykey2 f s v z a b i j l (integer) 1 127.0.0.1:6379> pfcount mykey2 (integer) 9 127.0.0.1:6379> pfcount mykey mykey2 (integer) 16
pfmerge : 将一个或多个HyperLogLog合并后的结果存储在另一个HLL中,比如每月活跃用户可以使用每天的活跃用户来合并计算可得
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> pfcount mykey (integer) 13 127.0.0.1:6379> pfcount mykey2 (integer) 9 127.0.0.1:6379> pfcount mykey mykey2 (integer) 16 127.0.0.1:6379> pfmerge mykey3 mykey mykey2 OK 127.0.0.1:6379> pfcount mykey3 (integer) 16
2.2 使用场景
3. Bitmaps(位图)
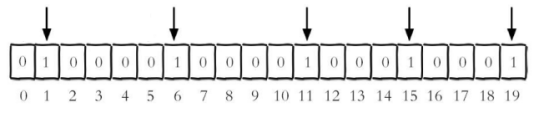
现代计算机用二进制(位) 作为信息的基础单位, 1个字节等于8位, 例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示, “abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是 01100001、 01100010 和 01100011,如下图:
Bitmaps 本身不是一种数据类型, 实际上它就是字符串(key-value) , 但是它可以对字符串的位进行操作。
Bitmaps 单独提供了一套命令, 所以在 Redis 中使用Bitmaps和使用字符串的方法不太相同。 可以把 Bitmaps 想象成一个以位为单位的数组, 数组的每个单元只能存储 0 和 1, 数组的下标在 Bitmaps 中叫做偏移量。
3.1 常用命令
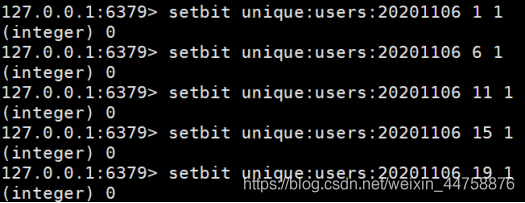
setbit : 设置Bitmaps中某个偏移量的值(0或1)
1 2 127.0.0.1:6379> setbit sign 0 1 (integer) 0
实例: 每个独立用户是否访问过网站存放在 Bitmaps 中, 将访问的用户记做 1, 没有访问的用户记做 0, 用偏移量作为用户的 id。注:
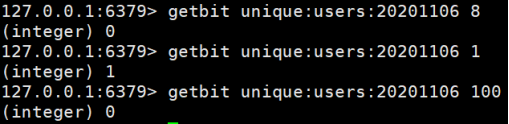
getbit : 获取Bitmaps中某个偏移量的值(获取键的第offset位的值(从0开始算))
1 2 3 4 127.0.0.1:6379> getbit sign 1 (integer) 0 127.0.0.1:6379> getbit sign 0 (integer) 1
实例: 获取 id=8 的用户是否在 2020-11-06 这天访问过, 返回 0 说明没有访问过:注:
bitcount : 统计字符串被设置为1的bit数。一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。start 和 end 参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位,start、end 是指bit组的字节的下标数,二者皆包含
1 2 127.0.0.1:6379> bitcount sign (integer) 3
实例: 计算 2022-11-06 这天的独立访问用户数量
bitop : 复合操作, 它可以做多个Bitmaps的and(交集) 、 or(并集) 、 not(非) 、 xor(异或) 操作并将结果保存在destkey中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 127.0.0.1:6379> setbit bitmap1 0 1 (integer) 0 127.0.0.1:6379> setbit bitmap1 1 0 (integer) 0 127.0.0.1:6379> setbit bitmap1 2 1 (integer) 0 127.0.0.1:6379> setbit bitmap2 2 1 (integer) 0 127.0.0.1:6379> setbit bitmap2 3 0 (integer) 0 127.0.0.1:6379> setbit bitmap2 4 1 (integer) 0 127.0.0.1:6379> bitop and bitmap3 bitmap1 bitmap2 (integer) 1 127.0.0.1:6379> bitcount bitmap3 (integer) 1 127.0.0.1:6379> bitop or bitmap4 bitmap1 bitmap2 (integer) 1 127.0.0.1:6379> bitcount bitmap4 (integer) 3 127.0.0.1:6379> bitop xor bitmap5 bitmap1 bitmap2 (integer) 1 127.0.0.1:6379> bitcount bitmap5 (integer) 2
3.2 使用场景
统计用户信息
区分活跃、不活跃用户;登录、未登录等等
上班打卡
3.3 Bitmaps与set对比
假设网站有1亿用户, 每天独立访问的用户有5千万, 如果每天用集合类型和Bitmaps分别存储活跃用户可以得到表
set 和 Bitmaps 存储一天活跃用户对比
数据类型
每个用户id占用空间
需要存储的用户量
全部内存量
集合类型
64位
50000000
64位 * 50000000 = 400MB
Bitmaps
1位
100000000
1位 * 100000000 = 12.5MB
很明显, 这种情况下使用Bitmaps能节省很多的内存空间, 尤其是随着时间推移节省的内存还是非常可观的
set 和 Bitmaps 存储独立用户空间对比
数据类型
一天
一个月
一年
集合类型
400MB
12GB
144GB
Bitmaps
12.5MB
375MB
4.5GB
但Bitmaps并不是万金油, 假如该网站每天的独立访问用户很少, 例如只有10万(大量的僵尸用户) , 那么两者的对比如下表所示, 很显然, 这时候使用Bitmaps就不太合适了, 因为基本上大部分位都是0
set 和 Bitmaps 存储一天活跃用户对比(独立用户比较少)
数据类型
每个userid占用空间
需要存储的用户量
全部内存量
集合类型
64位
100000
64位 * 100000 = 800KB
Bitmaps
1位
100000000
1位 * 100000000 = 12.5MB




 要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。
要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。