
Flink:从入门到放弃
一、Flink简介
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
1. Flink组件栈
每一层所包含的组件都提供了特定的抽象,用来服务于上层组件:
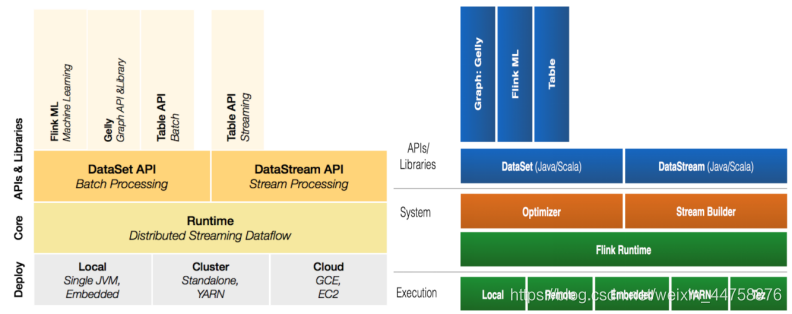
物理部署层: Flink 支持本地运行、能在独立集群或者在被 YARN 管理的集群上运行, 也能部署在云上,该层主要涉及Flink的部署模式,目前Flink支持多种部署模式:本地、集群(Standalone、YARN)、云(GCE/EC2)、Kubenetes。Flink能够通过该层能够支持不同平台的部署,用户可以根据需要选择使用对应的部署模式。
Runtime核心层: Runtime层提供了支持Flink计算的全部核心实现,为上层API层提供基础服务,该层主要负责对上层不同接口提供基础服务,也是Flink分布式计算框架的核心实现层,支持分布式Stream作业的执行、JobGraph到ExecutionGraph的映射转换、任务调度等。将DataSteam和DataSet转成统一的可执行的Task Operator,达到在流式引擎下同时处理批量计算和流式计算的目的。
API&Libraries层: Flink 首先支持了 Scala 和 Java 的 API,Python 也正在测试中。DataStream、DataSet、Table、SQL API,作为分布式数据处理框架,Flink同时提供了支撑计算和批计算的接口,两者都提供给用户丰富的数据处理高级API,例如Map、FlatMap操作等,也提供比较低级的Process Function API,用户可以直接操作状态和时间等底层数据。
扩展库: Flink 还包括用于复杂事件处理的CEP,机器学习库FlinkML,图处理库Gelly等。Table 是一种接口化的 SQL 支持,也就是 API 支持(DSL),而不是文本化的SQL 解析和执行。
2. Flink基石

- Checkpoint
- Flink基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义。
- State
- 提供了一致性的语义之后,Flink为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的State API,包括里面的有ValueState、ListState、MapState,近期添加了BroadcastState,使用State API能够自动享受到这种一致性的语义。
- Time
- Flink还实现了Watermark的机制,能够支持基于事件的时间的处理,能够容忍迟到/乱序的数据。
- Window
- 流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
3. Fink的应用场景
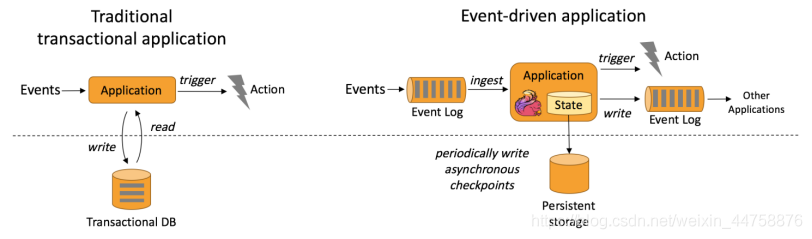
3.1 Event-driven Applications【事件驱动】
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。 比较典型的就是以 kafka 为代表的消息队列几乎都是事件驱动型应用。
事件驱动型应用是在计算存储分离的传统应用基础上进化而来。
在传统架构中,应用需要读写远程事务型数据库。
相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。
系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。
从某种程度上来说,所有的实时的数据处理或者是流式数据处理都应该是属于Data Driven,流计算本质上是Data Driven 计算。应用较多的如风控系统,当风控系统需要处理各种各样复杂的规则时,Data Driven 就会把处理的规则和逻辑写入到Datastream 的API 或者是ProcessFunction 的API 中,然后将逻辑抽象到整个Flink 引擎,当外面的数据流或者是事件进入就会触发相应的规则,这就是Data Driven 的原理。在触发某些规则后,Data Driven 会进行处理或者是进行预警,这些预警会发到下游产生业务通知,这是Data Driven 的应用场景,Data Driven 在应用上更多应用于复杂事件的处理。
- 典型实例:
- 欺诈检测(Fraud detection)
- 异常检测(Anomaly detection)
- 基于规则的告警(Rule-based alerting)
- 业务流程监控(Business process monitoring)
- Web应用程序(社交网络)
3.2 Data Analytics Applications【数据分析】
数据分析任务需要从原始数据中提取有价值的信息和指标。
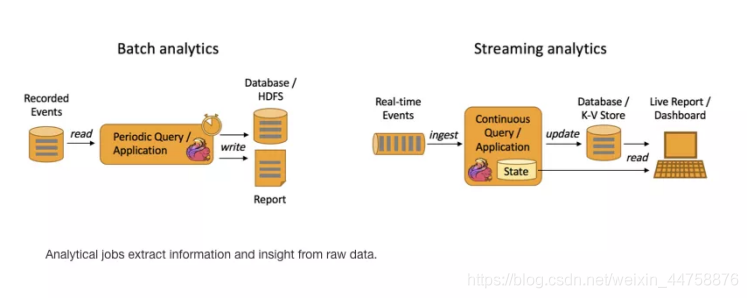
如下图所示,Apache Flink 同时支持流式及批量分析应用。
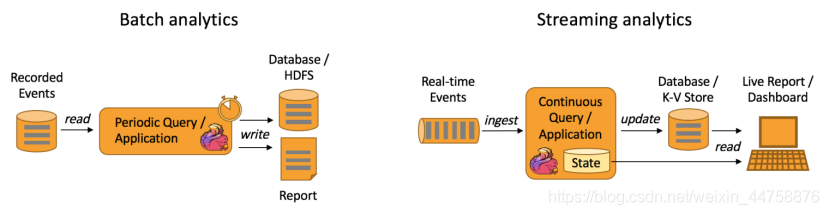
Data Analytics Applications包含Batch analytics(批处理分析) 和Streaming analytics(流处理分析)
Batch analytics可以理解为周期性查询:Batch Analytics 就是传统意义上使用类似于Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表。比如Flink应用凌晨从Recorded Events中读取昨天的数据,然后做周期查询运算,最后将数据写入Database或者HDFS,或者直接将数据生成报表供公司上层领导决策使用。
Streaming analytics可以理解为连续性查询:比如实时展示双十一天猫销售GMV(Gross Merchandise Volume成交总额),用户下单数据需要实时写入消息队列,Flink 应用源源不断读取数据做实时计算,然后不断的将数据更新至Database或者K-VStore,最后做大屏实时展示。
- 典型实例
- 电信网络质量监控
- 移动应用中的产品更新及实验评估分析
- 消费者技术中的实时数据即席分析
- 大规模图分析
3.3 Data Pipeline Applications【数据管道】
什么是数据管道?
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。
ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。
但数据管道是以持续流模式运行,而非周期性触发。
因此数据管道支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。
例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
和周期性 ETL 作业相比,持续数据管道可以明显降低将数据移动到目的端的延迟。
此外,由于它能够持续消费和发送数据,因此用途更广,支持用例更多。
下图描述了周期性ETL作业和持续数据管道的差异。
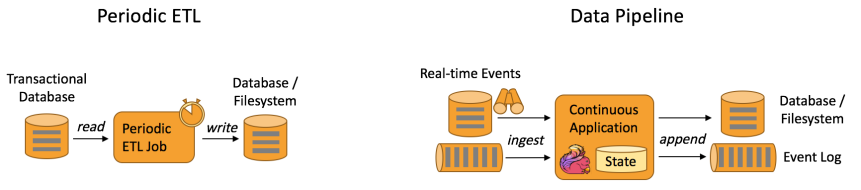
Periodic ETL:比如每天凌晨周期性的启动一个Flink ETL Job,读取传统数据库中的数据,然后做ETL,最后写入数据库和文件系统。
Data Pipeline:比如启动一个Flink 实时应用,数据源(比如数据库、Kafka)中的数据不断的通过Flink Data Pipeline流入或者追加到数据仓库(数据库或者文件系统),或者Kafka消息队列。
Data Pipeline 的核心场景类似于数据搬运并在搬运的过程中进行部分数据清洗或者处理,而整个业务架构图的左边是Periodic ETL,它提供了流式ETL 或者实时ETL,能够订阅消息队列的消息并进行处理,清洗完成后实时写入到下游的Database或File system 中。
- 典型实例
- 电子商务中的持续 ETL(实时数仓)
- 当下游要构建实时数仓时,上游则可能需要实时的Stream ETL。这个过程会进行实时清洗或扩展数据,清洗完成后写入到下游的实时数仓的整个链路中,可保证数据查询的时效性,形成实时数据采集、实时数据处理以及下游的实时Query。
- 电子商务中的实时查询索引构建(搜索引擎推荐)
- 搜索引擎这块以淘宝为例,当卖家上线新商品时,后台会实时产生消息流,该消息流经过Flink 系统时会进行数据的处理、扩展。然后将处理及扩展后的数据生成实时索引,写入到搜索引擎中。这样当淘宝卖家上线新商品时,能在秒级或者分钟级实现搜索引擎的搜索。
- 电子商务中的持续 ETL(实时数仓)
4. Flink的优点

- 主要优点
- Flink 具备统一的框架处理有界和无界两种数据流的能力
- 部署灵活,Flink 底层支持多种资源调度器,包括Yarn、Kubernetes 等。Flink 自身带的Standalone 的调度器,在部署上也十分灵活
- 极高的可伸缩性,可伸缩性对于分布式系统十分重要,阿里巴巴双11大屏采用Flink 处理海量数据,使用过程中测得Flink 峰值可达17 亿条/秒。
- 极致的流式处理性能。Flink 相对于Storm 最大的特点是将状态语义完全抽象到框架中,支持本地状态读取,避免了大量网络IO,可以极大提升状态存取的性能。
- 其他优点
- 同时支持高吞吐、低延迟、高性能
- Flink 是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式数据处理框架
- Spark 只能兼顾高吞吐和高性能特性,无法做到低延迟保障,因为Spark是用批处理来做流处理
- Storm 只能支持低延时和高性能特性,无法满足高吞吐的要求
- 支持事件时间(Event Time)概念
- 在流式计算领域中,窗口计算的地位举足轻重,但目前大多数框架窗口计算采用的都是系统时间(Process Time),也就是事件传输到计算框架处理时,系统主机的当前时间
- Flink 能够支持基于事件时间(Event Time)语义进行窗口计算
- 这种基于事件驱动的机制使得事件即使乱序到达甚至延迟到达,流系统也能够计算出精确的结果,保持了事件原本产生时的时序性,尽可能避免网络传输或硬件系统的影响
- 支持有状态计算
- Flink1.4开始支持有状态计算
- 所谓状态就是在流式计算过程中将算子的中间结果保存在内存或者文件系统中,等下一个事件进入算子后可以从之前的状态中获取中间结果,计算当前的结果,从而无须每次都基于全部的原始数据来统计结果,极大的提升了系统性能,状态化意味着应用可以维护随着时间推移已经产生的数据聚合
- 支持高度灵活的窗口(Window)操作
- Flink 将窗口划分为基于 Time 、Count 、Session、以及Data-Driven等类型的窗口操作,窗口可以用灵活的触发条件定制化来达到对复杂的流传输模式的支持,用户可以定义不同的窗口触发机制来满足不同的需求
- 基于轻量级分布式快照(Snapshot/Checkpoints)的容错机制
- Flink 能够分布运行在上千个节点上,通过基于分布式快照技术的Checkpoints,将执行过程中的状态信息进行持久化存储,一旦任务出现异常停止,Flink 能够从 Checkpoints 中进行任务的自动恢复,以确保数据处理过程中的一致性
- Flink 的容错能力是轻量级的,允许系统保持高并发,同时在相同时间内提供强一致性保证
- 基于 JVM 实现的独立的内存管理
- Flink 实现了自身管理内存的机制,通过使用散列,索引,缓存和排序有效地进行内存管理,通过序列化/反序列化机制将所有的数据对象转换成二进制在内存中存储,降低数据存储大小的同时,更加有效的利用空间。使其独立于 Java 的默认垃圾收集器,尽可能减少 JVM GC 对系统的影响
- SavePoints 保存点
- 对于 7 * 24 小时运行的流式应用,数据源源不断的流入,在一段时间内应用的终止有可能导致数据的丢失或者计算结果的不准确(比如集群版本的升级,停机运维操作等)
- Flink 通过SavePoints 技术将任务执行的快照保存在存储介质上,当任务重启的时候,可以从事先保存的 SavePoints 恢复原有的计算状态,使得任务继续按照停机之前的状态运行
- Flink 保存点提供了一个状态化的版本机制,使得能以无丢失状态和最短停机时间的方式更新应用或者回退历史数据
- 灵活的部署方式,支持大规模集群
- Flink 被设计成能用上千个点在大规模集群上运行
- 除了支持独立集群部署外,Flink 还支持 YARN 和Mesos 方式部署
- Flink 的程序内在是并行和分布式的
- 数据流可以被分区成 stream partitions,operators 被划分为operator subtasks,这些 subtasks 在不同的机器或容器中分不同的线程独立运行
- operator subtasks 的数量就是operator的并行计算数,不同的 operator 阶段可能有不同的并行数
- 丰富的库
- Flink 拥有丰富的库来进行机器学习,图形处理,关系数据处理等
- 同时支持高吞吐、低延迟、高性能
5. 流处理&批处理
- Batch Analytics 批量计算: 统一收集数据->存储到DB->对数据进行批量处理,就是传统意义上使用类似于 Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表
- Streaming Analytics 流式计算: 顾名思义,就是对数据流进行处理,如使用流式分析引擎如 Storm,Flink 实时处理分析数据,应用较多的场景如实时大屏、实时报表
- 主要区别
- 与批量计算那样慢慢积累数据不同,流式计算立刻计算,数据持续流动,计算完之后就丢弃
- 批量计算是维护一张表,对表进行实施各种计算逻辑。流式计算相反,是必须先定义好计算逻辑,提交到流式计算系统,这个计算作业逻辑在整个运行期间是不可更改的
- 计算结果上,批量计算对全部数据进行计算后传输结果,流式计算是每次小批量计算后,结果可以立刻实时化展现
6. 流批统一
在大数据处理领域,批处理任务与流处理任务一般被认为是两种不同的任务,一个大数据框架一般会被设计为只能处理其中一种任务:
- MapReduce只支持批处理任务
- Storm只支持流处理任务
- Spark Streaming采用micro-batch架构,本质上还是基于Spark批处理对流式数据进行处理
- Flink通过灵活的执行引擎,能够同时支持批处理任务与流处理任务
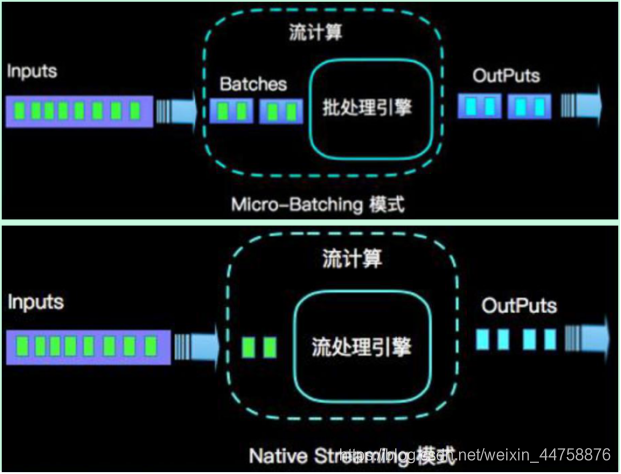
在执行引擎这一层,流处理系统与批处理系统最大不同在于节点间的数据传输方式:
- 对于一个流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理
- 对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点
这两种数据传输模式是两个极端,对应的是流处理系统对低延迟的要求和批处理系统对高吞吐量的要求。
Flink的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型:
- Flink以固定的缓存块为单位进行网络数据传输,用户可以通过设置缓存块超时值指定缓存块的传输时机
- 如果缓存块的超时值为0,则Flink的数据传输方式类似上面所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟
- 如果缓存块的超时值为无限大/-1,则Flink的数据传输方式类似上文所提到批处理系统的标准模型,此时系统可以获得最高的吞吐量
- 同时缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阈值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量
默认情况下,流中的元素并不会一个一个的在网络中传输,而是缓存起来伺机一起发送(默认为32KB,通过taskmanager.memory.segment-size设置),这样可以避免导致频繁的网络传输,提高吞吐量,但如果数据源输入不够快的话会导致后续的数据处理延迟,所以可以使用env.setBufferTimeout(默认100ms),来为缓存填入设置一个最大等待时间。等待时间到了之后,即使缓存还未填满,缓存中的数据也会自动发送
- timeoutMillis > 0 表示最长等待 timeoutMillis 时间,就会flush
- timeoutMillis = 0 表示每条数据都会触发 flush,直接将数据发送到下游,相当于没有Buffer了(避免设置为0,可能导致性能下降)
- timeoutMillis = -1 表示只有等到 buffer满了或 CheckPoint的时候,才会flush。相当于取消了 timeout 策略
Flink以缓存块为单位进行网络数据传输,用户可以设置缓存块超时时间和缓存块大小来控制缓冲块传输时机,从而控制Flink的延迟性和吞吐量
二、Flink安装部署
1. Local本地模式
1.1 原理
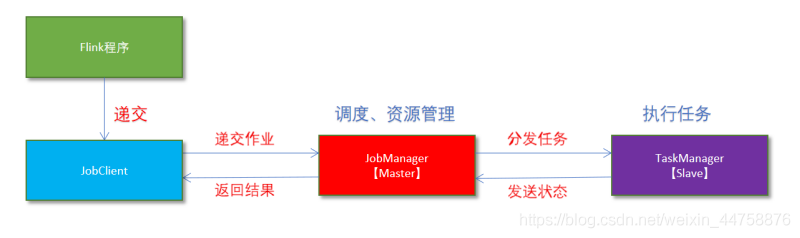
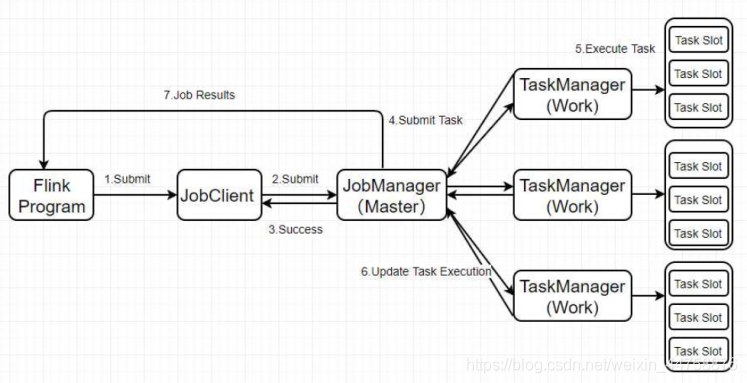
- Flink程序由JobClient进行提交
- JobClient将作业提交给JobManager
- JobManager负责协调资源分配和作业执行。资源分配完成后,任务将提交给相应的TaskManager
- TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改,如开始执行,正在进行或已完成
- 作业执行完成后,结果将发送回客户端(JobClient)
1.2 操作
-
上传flink-1.12.0-bin-scala_2.12.tgz到指定目录
-
解压
1
tar -zxvf flink-1.12.0-bin-scala_2.12.tgz
-
如果出现权限问题,需要修改权限
1
chown -R root:root /data/flink-1.12.0
-
改名或创建软链接
1
2mv flink-1.12.0 flink
ln -s /data/flink-1.12.0 /data/flink
1.3 测试
-
准备文件/data/words.txt
1
vim /data/words.txt
1
2
3
4hello me you her
hello me you
hello me
hello -
启动Flink本地集群
1
/data/flink/bin/start-cluster.sh
-
使用jps可以查看到下面两个进程
1
2- TaskManagerRunner
- StandaloneSessionClusterEntrypoint -
访问Flink的Web UI
http://IP地址:8081/#/overview
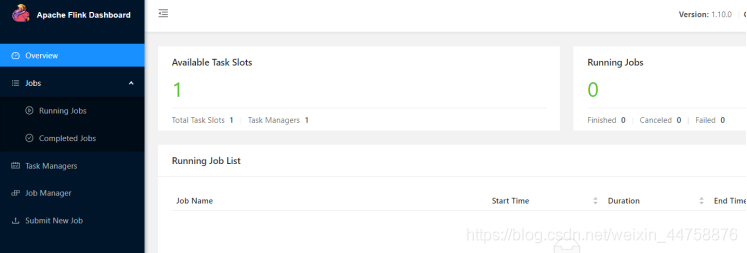
slot在Flink里面可以认为是资源组,Flink是通过将任务分成子任务并且将这些子任务分配到slot来并行执行程序 -
执行官方示例
1
/data/flink/bin/flink run /data/flink/examples/batch/WordCount.jar --input /data/words.txt --output /data/out
-
停止Flink
1
/data/flink/bin/start-scala-shell.sh local
2. Standalone独立集群模式
2.1 原理
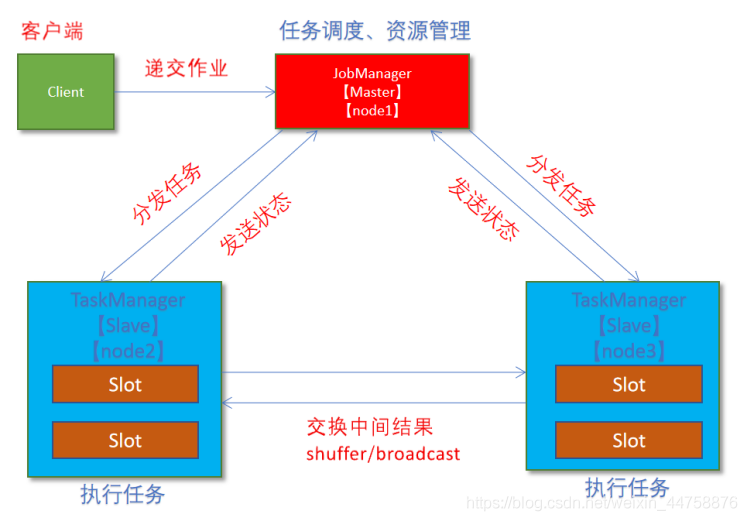
- client客户端提交任务给JobManager
- JobManager负责申请任务运行所需要的资源并管理任务和资源
- JobManager分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
2.2 操作
- 集群规划:
- 服务器: flink1(Master + Slave): JobManager + TaskManager
- 服务器: flink2(Slave): TaskManager
- 服务器: flink3(Slave): TaskManager
-
修改flink-conf.yaml
1
vim /data/flink/conf/flink-conf.yaml
1
2
3
4
5
6
7
8
9jobmanager.rpc.address: node1
taskmanager.numberOfTaskSlots: 2
web.submit.enable: true
#历史服务器
jobmanager.archive.fs.dir: hdfs://flink1:8020/flink/completed-jobs/
historyserver.web.address: flink1
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://flink1:8020/flink/completed-jobs/ -
修改masters
1
vim /data/flink/conf/masters
1
flink1:8081
-
修改slaves
1
vim /data/flink/conf/workers
1
2
3flink1
flink2
flink3 -
添加HADOOP_CONF_DIR环境变量
1
vim /etc/profile
1
export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop
-
分发
1
2
3
4scp -r /data/flink flink2:/data/flink
scp -r /data/flink flink3:/data/flink
scp /etc/profile flink2:/etc/profile
scp /etc/profile flink3:/etc/profile -
source
1
source /etc/profile
2.3 测试
-
启动集群,在flink1上执行如下命令
1
/data/flink/bin/start-cluster.sh
或者单独启动
1
2/data/flink/bin/jobmanager.sh ((start|start-foreground) cluster)|stop|stop-all
/data/flink/bin/taskmanager.sh start|start-foreground|stop|stop-all -
启动历史服务器
1
/data/flink/bin/historyserver.sh start
-
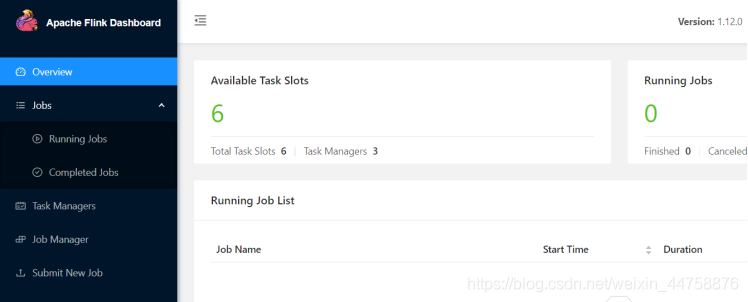
访问Flink UI界面或使用jps查看
http://flink1:8081/#/overview
http://flink1:8082/#/overview
TaskManager界面:可以查看到当前Flink集群中有多少个TaskManager,每个TaskManager的slots、内存、CPU Core是多少
-
执行官方测试案例
1
/data/flink/bin/flink run /data/flink/examples/batch/WordCount.jar --input hdfs://flink1:8020/wordcount/input/words.txt --output hdfs://flink1:8020/wordcount/output/result.txt --parallelism 2
-
查看历史日志
http://flink1:50070/explorer.html#/flink/completed-jobs
http://flink1:8082/#/overview -
停止Flink集群
1
/data/flink/bin/stop-cluster.sh
3. Standalone-HA高可用集群模式
3.1 原理
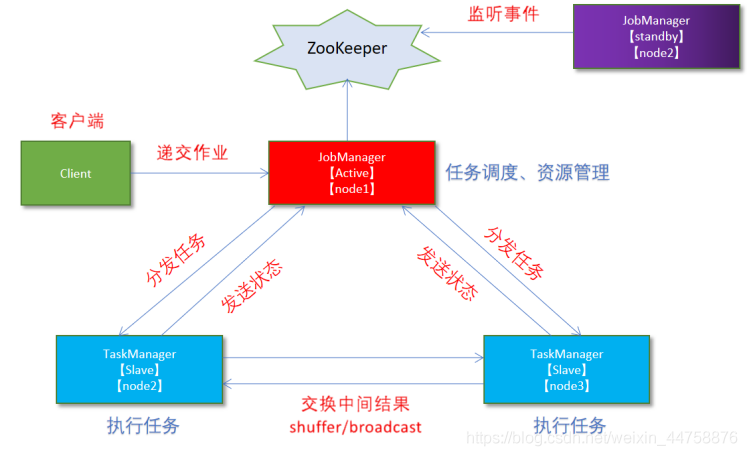
从之前的架构中可以很明显的发现 JobManager 有明显的单点问题(SPOF,single point of failure)。JobManager 肩负着任务调度以及资源分配,一旦 JobManager 出现意外,其后果可想而知。
在 Zookeeper 的帮助下,一个 Standalone的Flink集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于 Standby 状态。当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选一个新的 JobManager 来接管 Flink 集群。
3.2 操作
- 集群规划
- 服务器: flink1(Master + Slave): JobManager + TaskManager
- 服务器: flink2(Master + Slave): JobManager + TaskManager
- 服务器: flink3(Slave): TaskManager
-
启动ZooKeeper
1
2
3zkServer.sh status
zkServer.sh stop
zkServer.sh start -
启动HDFS
1
/data/hadoop/sbin/start-dfs.sh
-
停止Flink集群
1
/data/flink/bin/stop-cluster.sh
-
修改flink-conf.yaml
1
vim /data/flink/conf/flink-conf.yaml
增加如下内容
1
2
3
4
5
6
7
8
9
10#开启HA,使用文件系统作为快照存储
state.backend: filesystem
#启用检查点,可以将快照保存到HDFS
state.backend.fs.checkpointdir: hdfs://flink1:8020/flink-checkpoints
#使用zookeeper搭建高可用
high-availability: zookeeper
# 存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://flink1:8020/flink/ha/
# 配置ZK集群地址
high-availability.zookeeper.quorum: flink1:2181,flink2:2181,flink3:2181 -
修改masters
1
vim /data/flink/conf/masters
1
2flink1:8081
flink2:8081 -
同步
1
2
3
4scp -r /data/flink/conf/flink-conf.yaml flink2:/data/flink/conf/
scp -r /data/flink/conf/flink-conf.yaml flink3:/data/flink/conf/
scp -r /data/flink/conf/masters flink2:/data/flink/conf/
scp -r /data/flink/conf/masters flink3:/data/flink/conf/ -
修改flink2上的flink-conf.yaml
1
vim /data/flink/conf/flink-conf.yaml
1
jobmanager.rpc.address: flink2
-
重新启动Flink集群,flink1上执行
1
2/data/flink/bin/stop-cluster.sh
/data/flink/bin/start-cluster.sh -
使用jps命令查看
发现没有Flink相关进程被启动 -
查看日志
1
cat /data/flink/log/flink-root-standalonesession-0-node1.log
发现如下错误
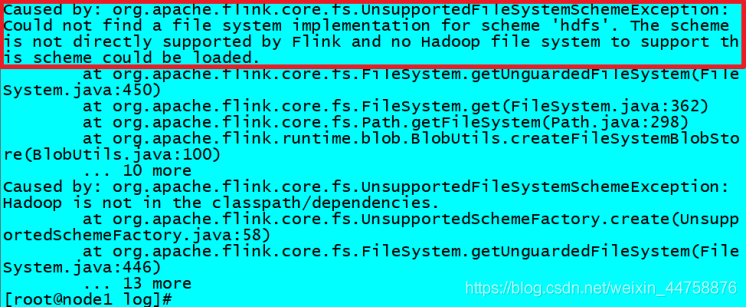
因为在Flink1.8版本后,Flink官方提供的安装包里没有整合HDFS的jar -
下载jar包并在Flink的lib目录下放入该jar包并分发使Flink能够支持对Hadoop的操作
https://flink.apache.org/downloads.html

依次放入lib目录1
cd /data/flink/lib
-
重新启动Flink集群,flink1上执行
1
/data/flink/bin/start-cluster.sh
-
使用jps命令查看,发现三台机器服务已启动
3.3 测试
-
访问WebUI
http://flink1:8081/#/job-manager/config
http://flink2:8081/#/job-manager/config -
执行wordcount
1
/data/flink/bin/flink run /data/flink/examples/batch/WordCount.jar
-
kill掉其中一个master
-
重新执行wc,还是可以正常执行
1
/data/flink/bin/flink run /data/flink/examples/batch/WordCount.jar
-
停止集群
1
/data/flink/bin/stop-cluster.sh
4. Flink On Yarn模式
4.1 原理
在实际开发中,使用Flink时,更多的使用方式是Flink On Yarn模式,原因如下:
- Yarn的资源可以按需使用,提高集群的资源利用率
- Yarn的任务有优先级,根据优先级运行作业
- 基于Yarn调度系统,能够自动化地处理各个角色的 Failover(容错)
- JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控
- 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器
- 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager
4.1.1 Flink如何和Yarn进行交互
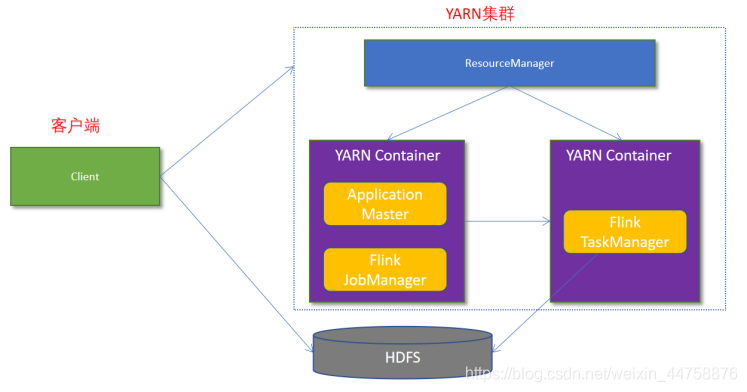
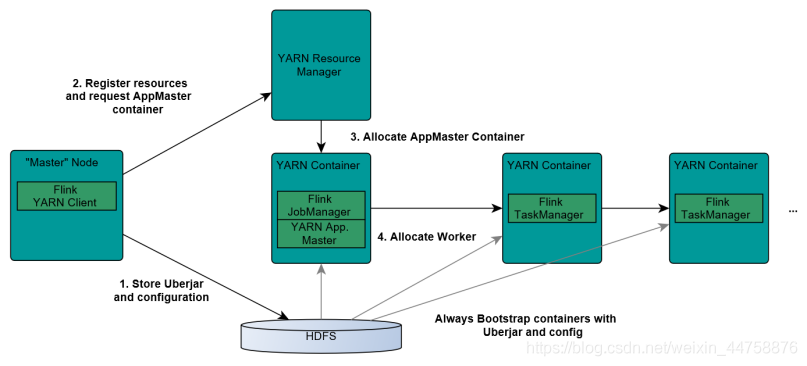
- Client上传jar包和配置文件到HDFS集群上
- Client向Yarn ResourceManager提交任务并申请资源
- ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager
JobManager和ApplicationMaster运行在同一个container上。
一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器)。
它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。
这个配置文件也被上传到HDFS上。
此外,AppMaster容器也提供了Flink的web服务接口。
YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink - ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务
4.1.2 两种方式
4.1.2.1 Session模式
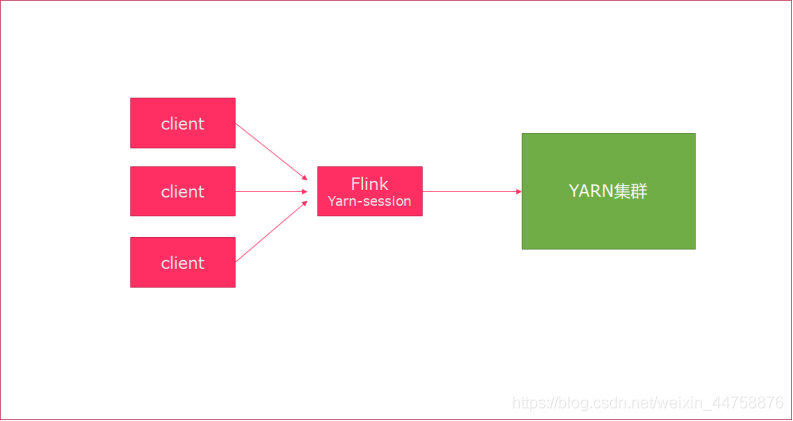
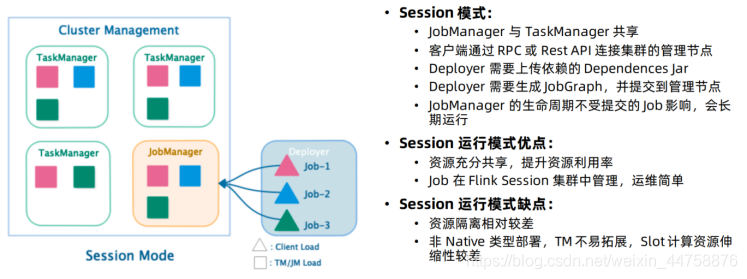
特点: 需要事先申请资源,启动JobManager和TaskManger
优点: 不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提高执行效率
缺点: 作业执行完成以后,资源不会被释放,因此一直会占用系统资源
应用场景: 适合作业递交比较频繁的场景,小作业比较多的场景
4.1.2.2 Per-Job模式
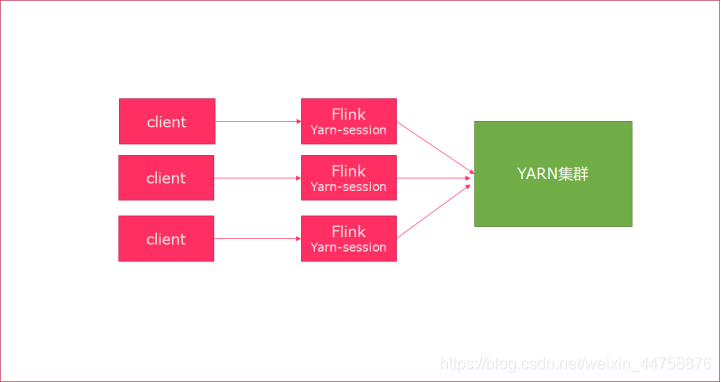
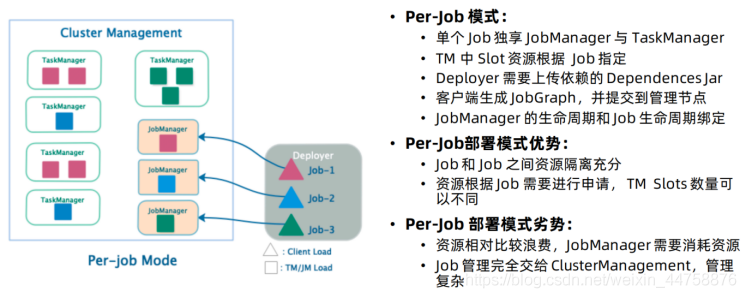
特点: 每次递交作业都需要申请一次资源
优点: 作业运行完成,资源会立刻被释放,不会一直占用系统资源
缺点: 每次递交作业都需要申请资源,会影响执行效率,因为申请资源需要消耗时间
应用场景: 适合作业比较少的场景、大作业的场景
4.2 操作
-
关闭yarn的内存检查
1
vim /data/hadoop/etc/hadoop/yarn-site.xml
添加:
1
2
3
4
5
6
7
8
9<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>说明:
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
在这里面我们需要关闭,因为对于flink使用yarn模式下,很容易内存超标,这个时候yarn会自动杀掉job -
同步
1
2scp -r /data/hadoop/etc/hadoop/yarn-site.xml flink2:/data/hadoop/etc/hadoop/yarn-site.xml
scp -r /data/hadoop/etc/hadoop/yarn-site.xml flink3:/data/hadoop/etc/hadoop/yarn-site.xml -
重启yarn
1
2/data/hadoop/sbin/stop-yarn.sh
/data/hadoop/sbin/start-yarn.sh
4.3 测试
4.3.1 Session模式
-
在yarn上启动一个Flink会话,flink1上执行以下命令
1
/data/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
说明:申请2个CPU、1600M内存
-n 表示申请2个容器,这里指的就是多少个taskmanager
-tm 表示每个TaskManager的内存大小
-s 表示每个TaskManager的slots数量
-d 表示以后台程序方式运行 -
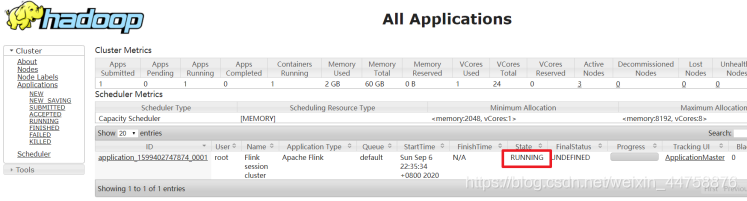
查看UI界面
http://flink1:8088/cluster
-
使用flink run提交任务
1
/data/flink/bin/flink run /data/flink/examples/batch/WordCount.jar
运行完之后可以继续运行其他的小任务
1
/data/flink/bin/flink run /data/flink/examples/batch/WordCount.jar
-
通过上方的ApplicationMaster可以进入Flink的管理界面
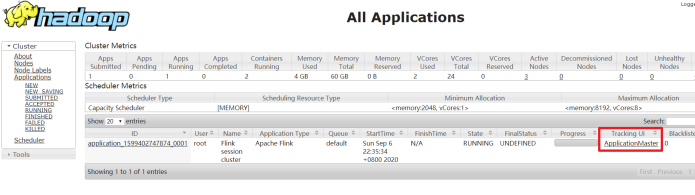
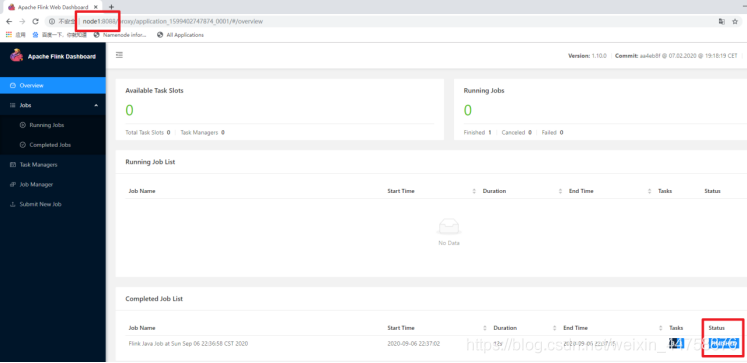
-
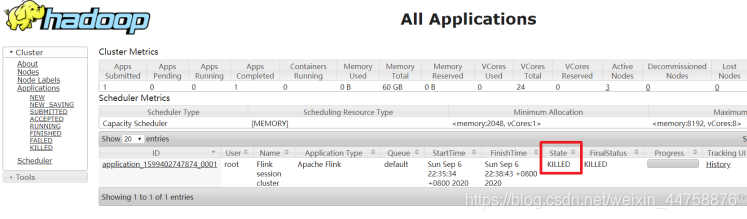
关闭yarn-session
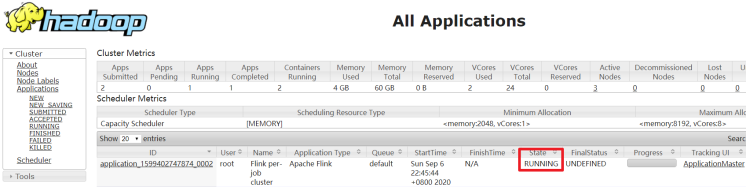
1
yarn application -kill application_1599402747874_0001
1
rm -rf /tmp/.yarn-properties-root
4.3.2 Per-Job分离模式
-
直接提交job
1
2/data/flink/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024
/data/flink/examples/batch/WordCount.jar-m jobmanager的地址
-yjm 1024 指定jobmanager的内存信息
-ytm 1024 指定taskmanager的内存信息 -
查看UI界面
http://flink1:8088/cluster
-
注意
在之前版本中如果使用的是flink on yarn方式,想切换回standalone模式的话,如果报错需要删除:【/tmp/.yarn-properties-root】1
rm -rf /tmp/.yarn-properties-root
因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager
三、Flink入门案例
1. 前置说明
1.1 API
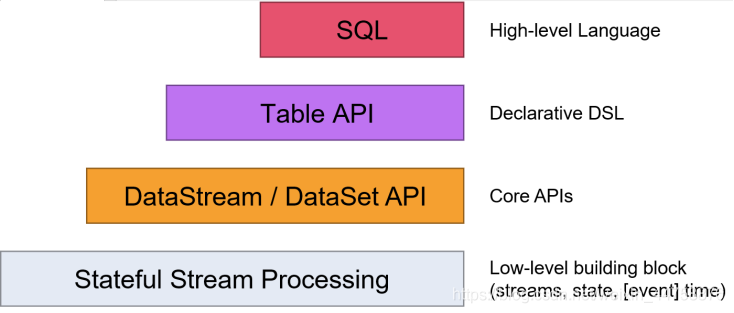
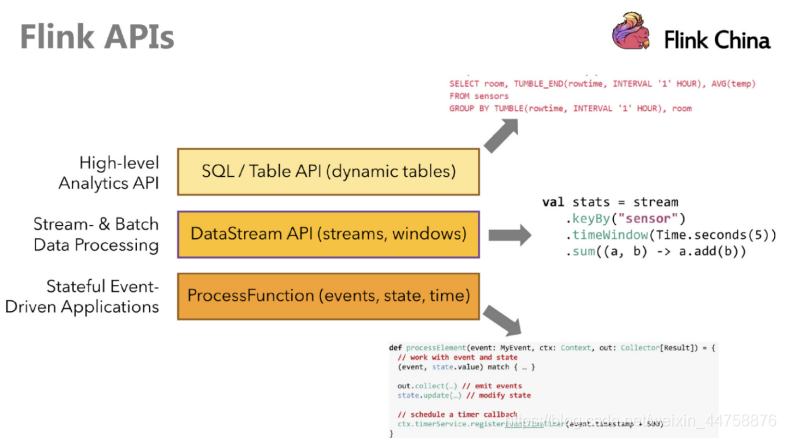
Flink提供了多个层次的API供开发者使用,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大
注:在Flink1.12时支持流批一体,DataSet API已经不推荐使用了,后续都会优先使用DataStream流式API,既支持无界数据处理/流处理,也支持有界数据处理/批处理
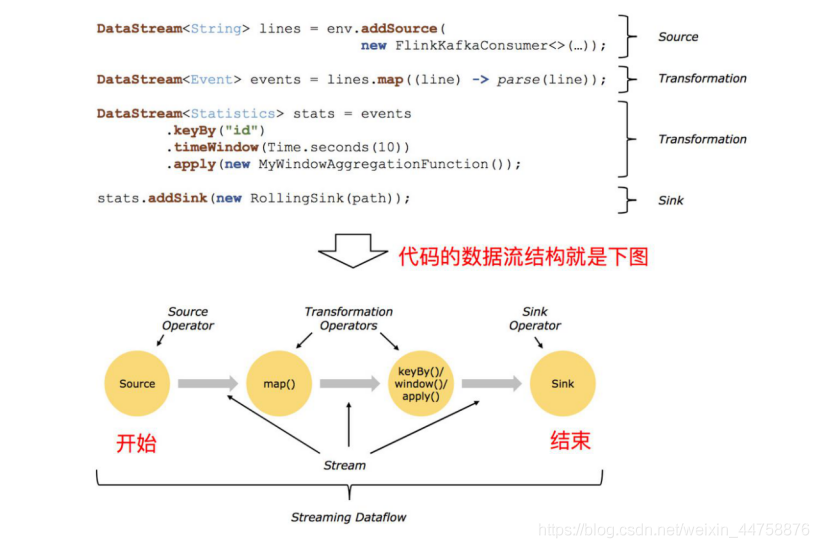
1.2 编程模型
Flink 应用程序结构主要包含三部分,Source/Transformation/Sink,如下图所示
2. 准备工作
2.1 pom文件
1 |
|
2.2 log4j.properties
1 | log4j.rootLogger=WARN, console |
3. Flink实现WordCount
3.1 编码步骤
- 准备环境-env
- 准备数据-source
- 处理数据-transformation
- 输出结果-sink
- 触发执行-execute
其中创建环境可以使用下面三种方式
1 | getExecutionEnvironment() //推荐使用 |
3.2 代码实现

3.2.1 批处理wordcount
1 | object WordCount { |
3.2.2 流处理wordcount
1 | object StreamWordCount { |
四、Flink原理
1. 角色分工
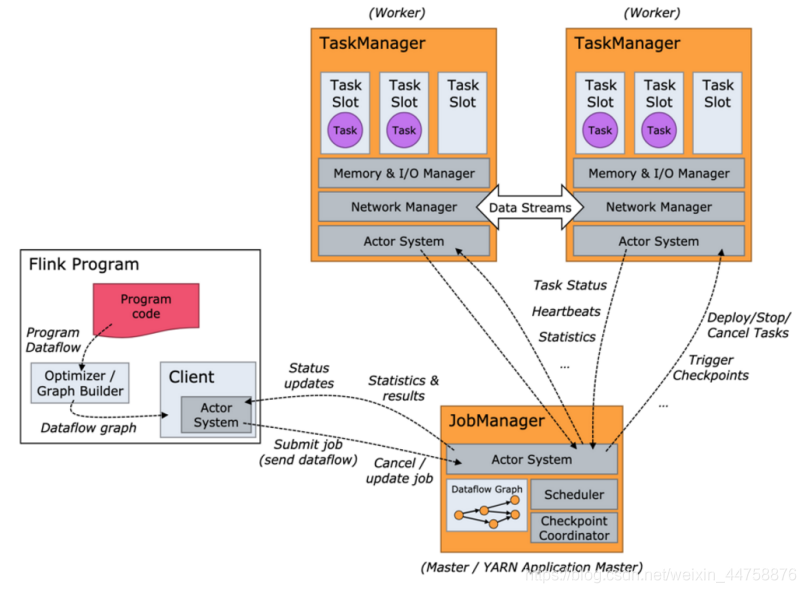
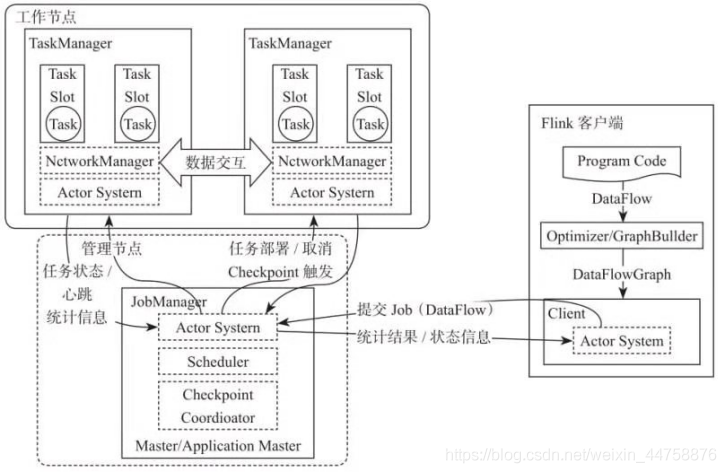
在实际生产中,Flink 都是以集群在运行,在运行的过程中包含了两类进程:
- JobManager
- 它扮演的是集群管理者的角色,负责调度任务、协调 checkpoints、协调故障恢复、收集 Job 的状态信息,并管理 Flink 集群中的从节点 TaskManager
- TaskManager
- 实际负责执行计算的 Worker,在其上执行 Flink Job 的一组 Task;TaskManager 还是所在节点的管理员,它负责把该节点上的服务器信息比如内存、磁盘、任务运行情况等向 JobManager 汇报
- Client
- 用户在提交编写好的 Flink 工程时,会先创建一个客户端再进行提交,这个客户端就是 Client
- 用户在提交编写好的 Flink 工程时,会先创建一个客户端再进行提交,这个客户端就是 Client
2. 执行流程
2.1 Standalone版
2.2 On Yarn版
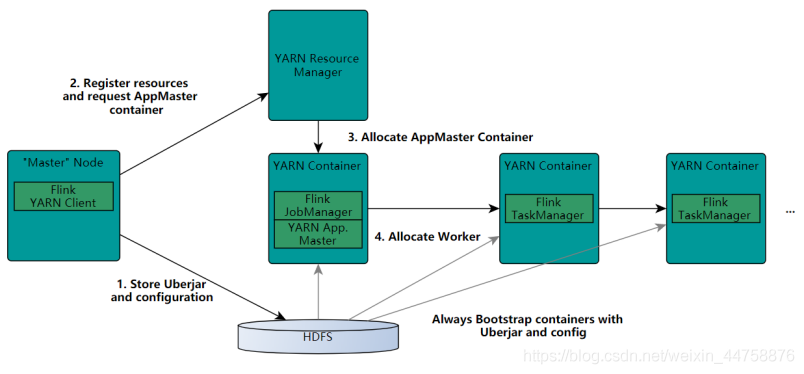
- Client向HDFS上传Flink的Jar包和配置
- Client向Yarn ResourceManager提交任务并申请资源
- ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager
- ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务
3. Flink Streaming Dataflow
3.1 Dataflow、Operator、Partition、SubTask、Parallelism
- Dataflow
- Flink程序在执行的时候会被映射成一个数据流模型
- Operator
- 数据流模型中的每一个操作被称作Operator,Operator分为:Source/Transform/Sink
- Partition
- 数据流模型是分布式的和并行的,执行中会形成1~n个分区
- Subtask
- 多个分区任务可以并行,每一个都是独立运行在一个线程中的,也就是一个Subtask子任
- Parallelism
- 并行度,就是可以同时真正执行的子任务数/分区数
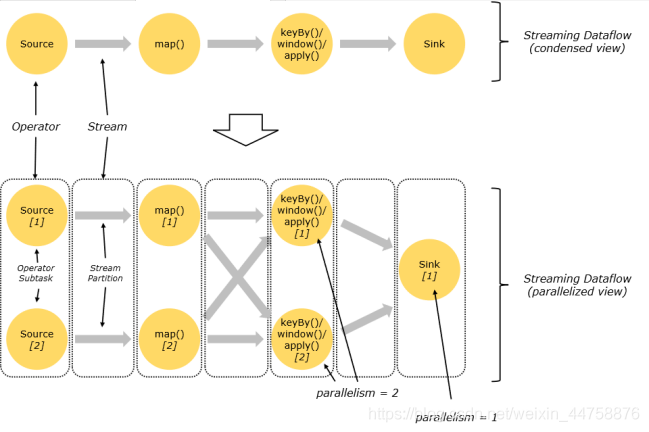
- 并行度,就是可以同时真正执行的子任务数/分区数
3.2 Operator传递模式
数据在两个operator(算子)之间传递的时候有两种模式:
- One to One模式
- 两个operator用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的Source1到Map1,它就保留的Source的分区特性,以及分区元素处理的有序性(类似于Spark中的窄依赖)
- Redistributing模式
- 这种模式会改变数据的分区数;每个一个operator subtask会根据选择transformation把数据发送到不同的目标subtasks,比如keyBy()会通过hashcode重新分区,broadcast()和rebalance()方法会随机重新分区(类似于Spark中的宽依赖)
3.3 Operator Chain
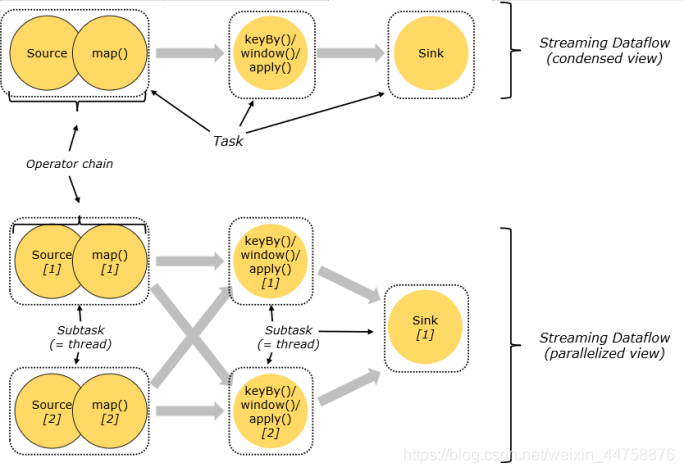
客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行(就是SubTask)
3.4 TaskSlot And Slot Sharing
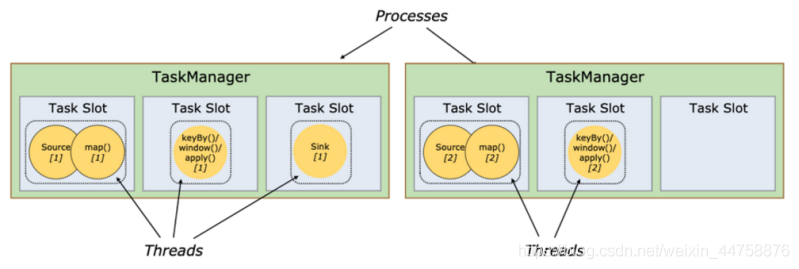
- 任务槽(TaskSlot)
- 每个TaskManager是一个JVM的进程, 为了控制一个TaskManager(worker)能接收多少个task,Flink通过Task Slot来进行控制
TaskSlot数量是用来限制一个TaskManager工作进程中可以同时运行多少个工作线程,TaskSlot 是一个 TaskManager 中的最小资源分配单位,一个 TaskManager 中有多少个 TaskSlot 就意味着能支持多少并发的Task处理
- 每个TaskManager是一个JVM的进程, 为了控制一个TaskManager(worker)能接收多少个task,Flink通过Task Slot来进行控制
Flink将进程的内存进行了划分到多个slot中,内存被划分到不同的slot之后可以获得如下好处:
- TaskManager最多能同时并发执行的子任务数是可以通过TaskSolt数量来控制的
- TaskSolt有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响
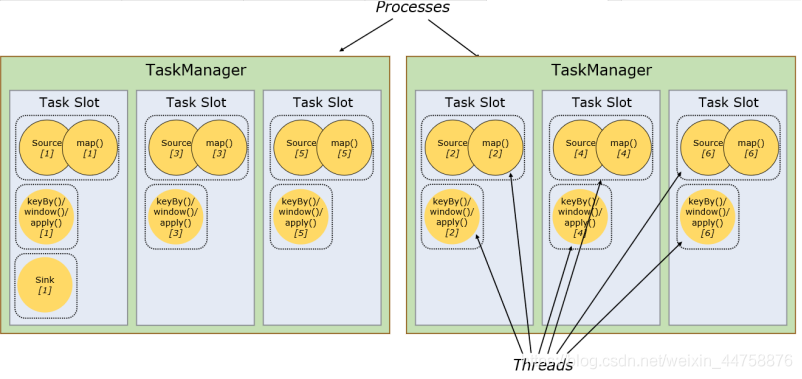
- 槽共享(Slot Sharing)
- Flink允许子任务共享插槽,即使它们是不同任务(阶段)的子任务(subTask),只要它们来自同一个作业
比如图左下角中的map和keyBy和sink 在一个 TaskSlot 里执行以达到资源共享的目的
- Flink允许子任务共享插槽,即使它们是不同任务(阶段)的子任务(subTask),只要它们来自同一个作业
允许插槽共享有两个主要好处:
- 资源分配更加公平,如果有比较空闲的slot可以将更多的任务分配给它
- 有了任务槽共享,可以提高资源的利用率
注:
slot是静态的概念,是指taskmanager具有的并发执行能力
parallelism是动态的概念,是指程序运行时实际使用的并发能力
4. Flink运行时的组件
Flink运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:
- 作业管理器(JobManager)
- 分配任务、调度checkpoint做快照
- 任务管理器(TaskManager)
- 主要干活的
- 资源管理器(ResourceManager)
- 管理分配资源
- 分发器(Dispatcher)
- 方便递交任务的接口,WebUI
因为Flink是用Java和Scala实现的,所以所有组件都会运行在Java虚拟机上。每个组件的职责如下:
- 作业管理器(JobManager)
- 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager 所控制执行
- JobManager 会先接收到要执行的应用程序,这个应用程序会包括:作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的JAR包
- JobManager 会把JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务
- JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调
- 任务管理器(TaskManager)
- Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量
- 启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了
- 在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据
- 资源管理器(ResourceManager)
- 主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是Flink中定义的处理资源单元
- Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,以及standalone部署
- 当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器
- 分发器(Dispatcher)
- 可以跨作业运行,它为应用提交提供了REST接口
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager
- Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息
- Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式
5. Flink执行图(ExecutionGraph)
由Flink程序直接映射成的数据流图是StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(也叫执行图),详细说明程序的执行方式。
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
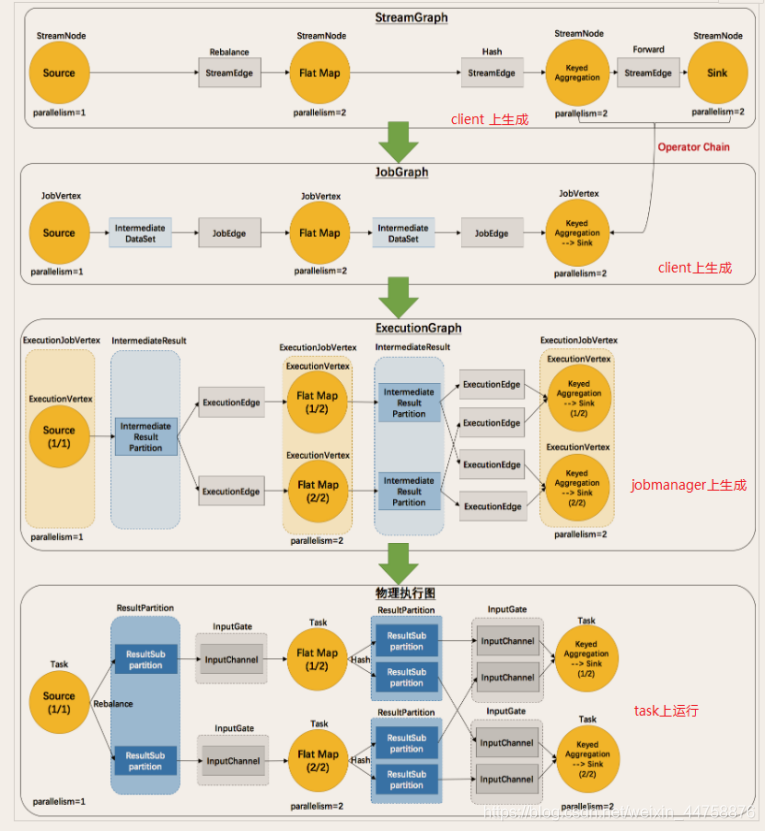
- 原理介绍
- Flink执行executor会自动根据程序代码生成DAG数据流图
- Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
- StreamGraph: 是根据用户通过 Stream API 编写的代码生成的最初的图。表示程序的拓扑结构
- JobGraph: StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗
- ExecutionGraph: JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构
- 物理执行图: JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构
- 简单理解
- StreamGraph: 最初的程序执行逻辑流程,也就是算子之间的前后顺序(在Client上生成)
- JobGraph: 将OneToOne的Operator合并为OperatorChain(在Client上生成)
- ExecutionGraph: 将JobGraph根据代码中设置的并行度和请求的资源进行并行化规划!(在JobManager上生成)
- 物理执行图: 将ExecutionGraph的并行计划,落实到具体的TaskManager上,将具体的SubTask落实到具体的TaskSlot内进行运行
五、流批一体API
1. DataStream API
- DataStream API 支持批执行模式
- Flink 的核心 API 最初是针对特定的场景设计的,尽管 Table API / SQL 针对流处理和批处理已经实现了统一的 API,但当用户使用较底层的 API 时,仍然需要在批处理(DataSet API)和流处理(DataStream API)这两种不同的 API 之间进行选择。鉴于批处理是流处理的一种特例,将这两种 API 合并成统一的 API,有一些非常明显的好处,比如:
- 可复用性:作业可以在流和批这两种执行模式之间自由地切换,而无需重写任何代码。因此,用户可以复用同一个作业,来处理实时数据和历史数据
- 维护简单:统一的 API 意味着流和批可以共用同一组 connector,维护同一套代码,并能够轻松地实现流批混合执行,例如 backfilling 之类的场景
- Flink 的核心 API 最初是针对特定的场景设计的,尽管 Table API / SQL 针对流处理和批处理已经实现了统一的 API,但当用户使用较底层的 API 时,仍然需要在批处理(DataSet API)和流处理(DataStream API)这两种不同的 API 之间进行选择。鉴于批处理是流处理的一种特例,将这两种 API 合并成统一的 API,有一些非常明显的好处,比如:
考虑到这些优点,社区已朝着流批统一的 DataStream API 迈出了第一步:支持高效的批处理(FLIP-134)。从长远来看,这意味着 DataSet API 将被弃用(FLIP-131),其功能将被包含在 DataStream API 和 Table API / SQL 中。
2. Source
2.1 预定义Source
2.1.1 基于集合的Source
1 | // 定义样例类,传感器id,时间戳,温度 |
2.1.2 基于文件的Source
1 | val stream2: DataStream[String] = env.readTextFile("FILE_PATH") |
2.1.3 基于Socket的Source
1 | object StreamTest { |
2.1.4 Kafka Source
需要引入Kafka连接器的依赖:
1 | <!-- |
1 | object StreamTest { |
2.2 自定义Source
除了以上的 source 数据来源, 我们还可以自定义 source。需要做的, 只是传入一个 SourceFunction 就可以。具体调用如下:
1 | val stream = env.addSource( new MySensorSource() ) |
我们希望可以随机生成传感器数据, MySensorSource 具体的代码实现如下:
1 | class MySensorSource extends SourceFunction[SensorReading]{ |
3. Transformation
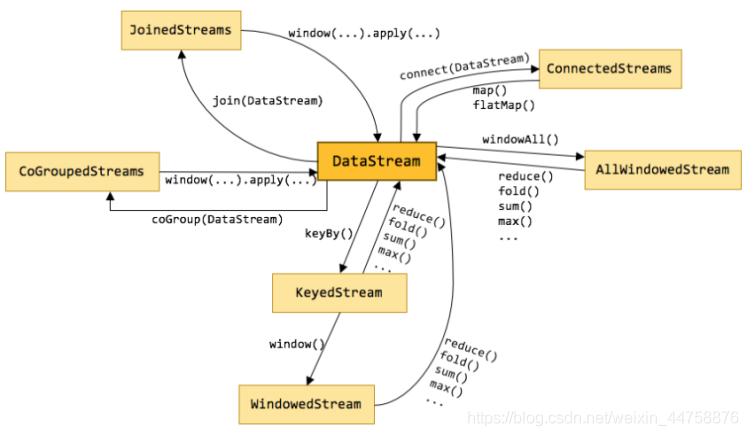
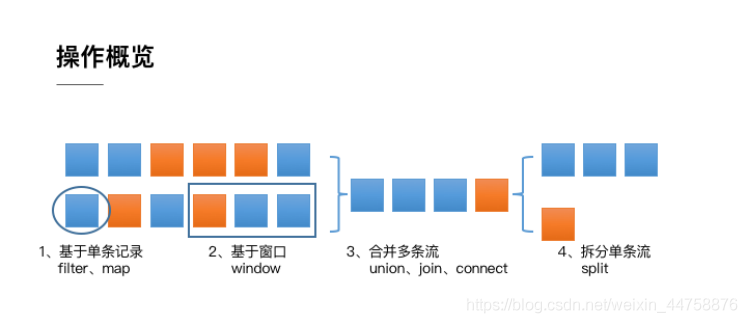
整体来说,流式数据上的操作可以分为四类:
- 第一类是对于单条记录的操作,比如筛除掉不符合要求的记录(Filter 操作),或者将每条记录都做一个转换(Map 操作)
- 第二类是对多条记录的操作。比如说统计一个小时内的订单总成交量,就需要将一个小时内的所有订单记录的成交量加到一起。为了支持这种类型的操作,就得通过 Window 将需要的记录关联到一起进行处理
- 第三类是对多个流进行操作并转换为单个流。例如,多个流可以通过 Union、Join 或 Connect 等操作合到一起。这些操作合并的逻辑不同,但是它们最终都会产生了一个新的统一的流,从而可以进行一些跨流的操作
- DataStream 还支持与合并对称的拆分操作,即把一个流按一定规则拆分为多个流(Split 操作),每个流是之前流的一个子集,这样我们就可以对不同的流作不同的处理
3.1 map
map: 将函数作用在集合中的每一个元素上,并返回作用后的结果
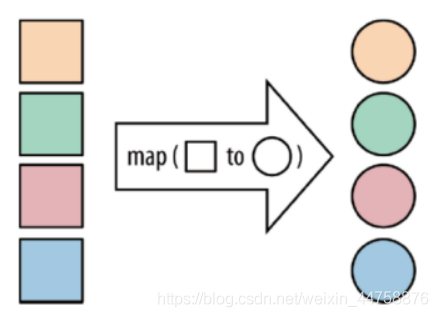
1 | val streamMap = stream.map { x => x * 2 } |
3.2 flatMap
flatMap: 将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果
1 | val streamFlatMap = stream.flatMap{ |
flatMap 的函数签名:
1 | def flatMap[A,B](as: List[A])(f: A ⇒ List[B]): List[B] |
例如:
1 | flatMap(List(1,2,3))(i => List(i,i)) |
结果是 List(1,1,2,2,3,3)
1 | List("a b", "c d").flatMap(line => line.split(" ")) |
结果是 List(a, b, c, d)
3.3 filter
filter: 按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素

1 | val streamFilter = stream.filter{ |
3.4 keyBy
DataStream → KeyedStream: 逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同 key 的元素,在内部以 hash 的形式实现的。
注: 流处理中没有groupBy,而是keyBy
3.5 滚动聚合算子(Rolling Aggregation)
这些算子可以针对 KeyedStream 的每一个支流做聚合:
- sum()
- min()
- max()
- minBy()
- maxBy()
3.6 Reduce
KeyedStream → DataStream: 一个分组数据流的聚合操作,合并当前的元素 和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是 只返回最后一次聚合的最终结果
1 | val stream2 = env.readTextFile("YOUR_PATH\\sensor.txt") |
3.7 合并&拆分
3.7.1 Split 和 Select
Split: 根据某些特征把一个 DataStream 拆分成两个或者 多个 DataStream(DataStream → SplitStream)
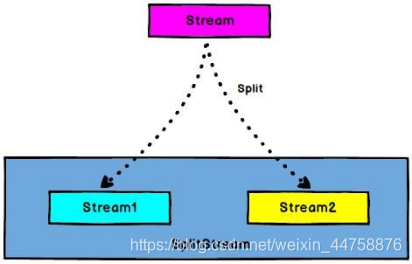
Select: 从一个 SplitStream 中获取一个或者多个DataStream(SplitStream→DataStream)
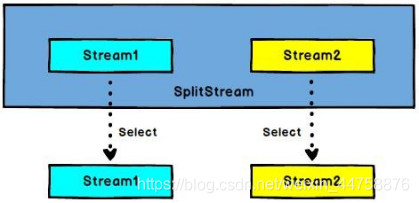
需求: 传感器数据按照温度高低(以 30 度为界),拆分成两个流
1 | val splitStream = stream2 |
3.7.2 Connect 和 CoMap
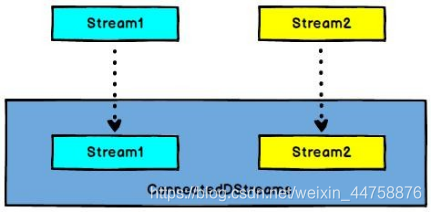
Connect: 连接两个保持他们类型的数据流, 两个数据流被 Connect 之后, 只是被放在了一个同一个流中, 内部依然保持各自的数据和形式不发生任何变化, 两个流相互独立(DataStream,DataStream → ConnectedStreams)
CoMap,CoFlatMap: 作用于 ConnectedStreams 上, 功能与 map 和 flatMap 一样, 对ConnectedStreams 中的每一个 Stream 分别进行 map 和 flatMap 处理(ConnectedStreams → DataStream)
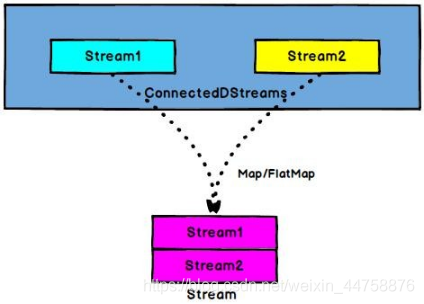
1 | val warning = high.map( sensorData => (sensorData.id, sensorData.temperature) ) |
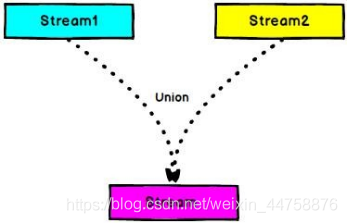
3.7.3 Union
DataStream → DataStream: 对两个或者两个以上的 DataStream 进行 union 操 作,产生一个包含所有 DataStream 元素的新 DataStream
1 | //合并以后打印 |
Connect 与 Union 区别:
- Union 之前两个流的类型必须是一样,Connect 可以不一样,在之后的 coMap 中再去调整成为一样的
- Connect 只能操作两个流,Union 可以操作多个
3.8 分区
3.8.1 rebalance重平衡分区
类似于Spark中的repartition,但是功能更强大,可以直接解决数据倾斜
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发生如图所示的状况,出现了数据倾斜,其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成:
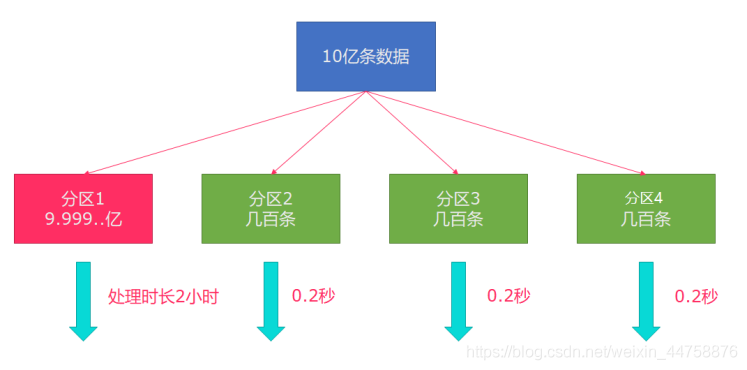
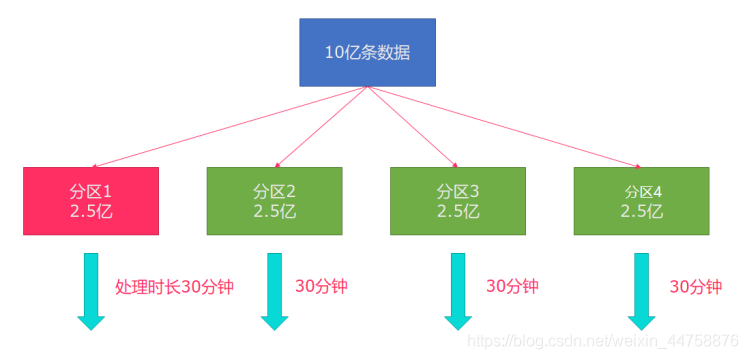
所以在实际的工作中,出现这种情况比较好的解决方案就是rebalance(内部使用round robin方法将数据均匀打散)
3.8.2 其他分区
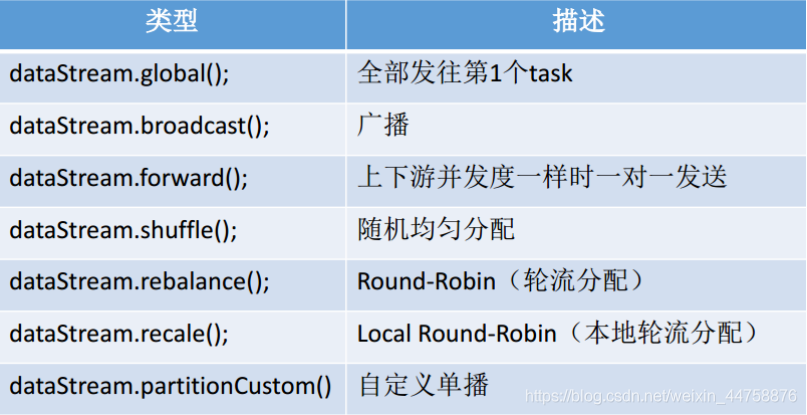
recale分区: 基于上下游Operator的并行度,将记录以循环的方式输出到下游Operator的每个实例
举例: 上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。若上游并行度是4,下游并行度是2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上。
3.9 支持的数据类型
Flink 流应用程序处理的是以数据对象表示的事件流。所以在 Flink 内部, 我们需要能够处理这些对象。它们需要被序列化和反序列化, 以便通过网络传送它们; 或者从状态后端、检查点和保存点读取它们。为了有效地做到这一点,Flink 需要明确知道应用程序所处理的数据类型。Flink 使用类型信息的概念来表示数据类型,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
Flink 还具有一个类型提取系统,该系统分析函数的输入和返回类型,以自动获取类型信息,从而获得序列化器和反序列化器。但是,在某些情况下,例如 lambda 函数或泛型类型, 需要显式地提供类型信息, 才能使应用程序正常工作或提高其性能。
3.9.1 基础数据类型
Flink 支持所有的 Java 和 Scala 基础数据类型, Int, Double, Long, String, …
1 | val numbers: DataStream[Long] = env.fromElements(1L, 2L, 3L, 4L) |
3.9.2 Java 和Scala 元组(Tuples)
1 | val persons: DataStream[(String, Integer)] = env |
3.9.3 Scala 样例类(case classes)
1 | case class Person(name: String, age: Int) |
3.9.4 Java 简单对象(POJOs)
1 | public class Person { |
3.9.5 其它(Arrays, Lists, Maps, Enums, 等等)
Flink 对 Java 和 Scala 中的一些特殊目的的类型也都是支持的,比如 Java 的 ArrayList,HashMap,Enum 等等。
4. Sink
Flink 没有类似于 spark 中 foreach 方法, 让用户进行迭代的操作。虽有对外的输出操作都要利用 Sink 完成。最后通过类似如下方式完成整个任务最终输出操作。
1 | stream.addSink(new MySink(xxxx)) |
官方提供了一部分的框架的 sink。除此以外, 需要用户自定义实现 sink
4.1 Kafka
- pom依赖
1 | <!-- |
- 主函数中添加sink
1 | val union = high.union(low).map(_.temperature.toString) |
4.2 Redis
- pom依赖
1 | <!-- |
- 定义一个 redis 的 mapper 类, 用于定义保存到 redis 时调用的命令
1 | class MyRedisMapper extends RedisMapper[SensorReading]{ |
- 在主函数中调用
1 | val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build() |
4.3 Elasticsearch
- pom依赖
1 | <dependency> |
- 在主函数中调用
1 | val httpHosts = new util.ArrayList[HttpHost]() |
4.4 JDBC自定义sink
- pom依赖
1 | <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --> |
- 添加 MyJdbcSink
1 | class MyJdbcSink() extends RichSinkFunction[SensorReading]{ |
- 在 main 方法中增加
1 | dataStream.addSink(new MyJdbcSink()) |
六、Flink中的Window
1. Window概述
- 简介
streaming 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集, 而 window 是一种切割无限数据为有限块进行处理的手段。
Window 是无限数据流处理的核心,可以将一个无限的 stream 拆分成有限大小的” buckets” 桶, 我们可以在这些桶上做计算操作。 - 为什么需要Window?
在流处理应用中,数据是连续不断的,有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。
在这种情况下,我们必须定义一个窗口(window),用来收集最近1分钟内的数据,并对这个窗口内的数据进行计算。
2. Window的分类
2.1 按照time和count分类
time-window:时间窗口,根据时间划分窗口,如:每xx分钟统计最近xx分钟的数据。
count-window:数量窗口,根据数量划分窗口,如:每xx个数据统计最近xx个数据。

2.2 按照side和size分类
窗口有两个重要的属性: 窗口大小size和滑动间隔slide,根据它们的大小关系可分为:
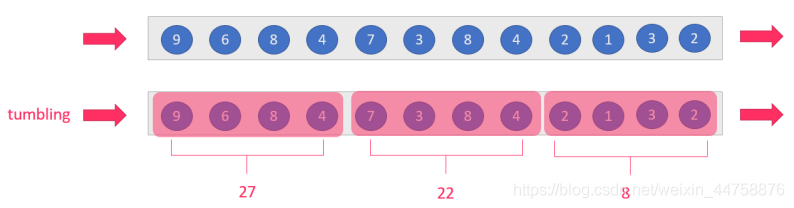
tumbling-window:滚动窗口,size=slide,如:每隔10s统计最近10s的数据
特点:时间对齐,窗口长度固定,没有重叠
适用场景:适合做 BI 统计等(做每个时间段的聚合计算)
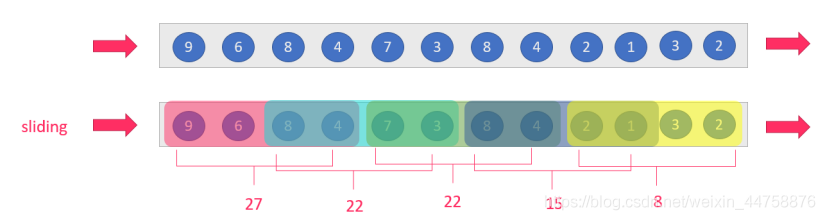
sliding-window:滑动窗口,size>slide,如:每隔5s统计最近10s的数据
特点:时间对齐,窗口长度固定,可以有重叠
适用场景:对最近一个时间段内的统计(求某接口最近 5min 的失败率来决定是 否要报警)
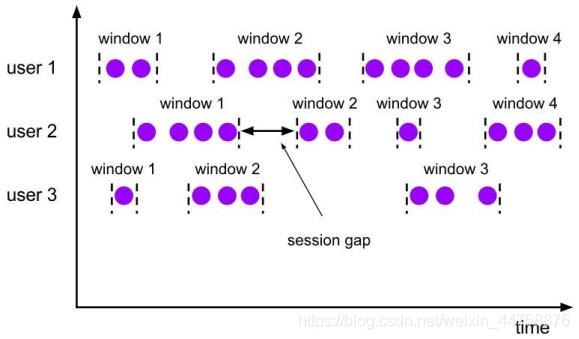
session-windows:会话窗口,size=slide,如:每隔10s统计最近10s的数据
特点:时间无对齐
session 窗口分配器通过 session 活动来对元素进行分组,session 窗口跟滚动窗 口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它 在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关 闭。一个 session 窗口通过一个 session 间隔来配置,这个 session 间隔定义了非活跃 周期的长度,当这个非活跃周期产生,那么当前的 session 将关闭并且后续的元素将 被分配到新的 session 窗口中去
注意:当size<slide的时候,如每隔15s统计最近10s的数据,那么中间5s的数据会丢失,所有开发中不用
2.3 总结
按照上面窗口的分类方式进行组合,可以得出如下的窗口:
- 基于时间的滚动窗口tumbling-time-window——用的较多
- 基于时间的滑动窗口sliding-time-window——用的较多
- 基于数量的滚动窗口tumbling-count-window——用的较少
- 基于数量的滑动窗口sliding-count-window——用的较少
注意:Flink还支持一个特殊的窗口:Session会话窗口,需要设置一个会话超时时间,如30s,则表示30s内没有数据到来,则触发上个窗口的计算
3. Window API
3.1 TimeWindow
TimeWindow 是将指定时间范围内的所有数据组成一个 window, 一次对一个window 里面的所有数据进行计算。
3.1.1 滚动窗口
Flink 默认的时间窗口根据 Processing Time 进行窗口的划分,将 Flink 获取到的数据根据进入 Flink 的时间划分到不同的窗口中。
1 | val minTempPerWindow = dataStream |
时间间隔可以通过 Time.milliseconds(x),Time.seconds(x),Time.minutes(x) 等其中的一个来指定。
3.1.2 滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的, 只是在传参数时需要传入两个参数, 一个是 window_size, 一个是 sliding_size。
- 下面代码中的 sliding_size 设置为了 5s,也就是说,每 5s 就计算输出结果一次, 每一次计算的 window 范围是 15s 内的所有元素:
1 | val minTempPerWindow: DataStream[(String, Double)] = dataStream |
时间间隔可以通过 Time.milliseconds(x),Time.seconds(x),Time.minutes(x) 等其中的一个来指定。
3.2 CountWindow
CountWindow 根据窗口中相同 key 元素的数量来触发执行, 执行时只计算元素数量达到窗口大小的 key 对应的结果。
注: CountWindow 的 window_size 指的是相同 Key 的元素的个数,不是输入的所有元素的总数。
3.2.1 滚动窗口
默认的 CountWindow 是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时, 就会触发窗口的执行。
1 | val minTempPerWindow: DataStream[(String, Double)] = dataStream |
3.2.2 滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的, 只是在传参数时需要传入两个参数, 一个是 window_size, 一个是 sliding_size。
- 下面代码中的 sliding_size 设置为了 2, 也就是说, 每收到两个相同 key 的数据就计算一次, 每一次计算的 window 范围是 10 个元素:
1 | val keyedStream: KeyedStream[(String, Int), Tuple] = dataStream.map(r => (r.id,r.temperature)).keyBy(0) |
3.3 window function
window function 定义了要对窗口中收集的数据做的计算操作,主要可以分为两类:
- 增量聚合函数( incremental aggregation functions)
- 每条数据到来就进行计算, 保持一个简单的状态
- 典型的增量聚合函数有ReduceFunction, AggregateFunction
- 全窗口函数( full window functions)
- 先把窗口所有数据收集起来, 等到计算的时候会遍历所有数据
- ProcessWindowFunction 就是一个全窗口函数
3.4 其他API
- .trigger() —— 触发器
- 定义 window 什么时候关闭, 触发计算并输出结果
- .evitor() —— 移除器
- 定义移除某些数据的逻辑
- .allowedLateness() —— 允许处理迟到的数据
- .sideOutputLateData() —— 将迟到的数据放入侧输出流
- .getSideOutput() —— 获取侧输出流

七、时间语义与Wartermark
1. Flink中的时间语义
在Flink的流式处理中,会涉及到时间的不同概念,如下图所示:
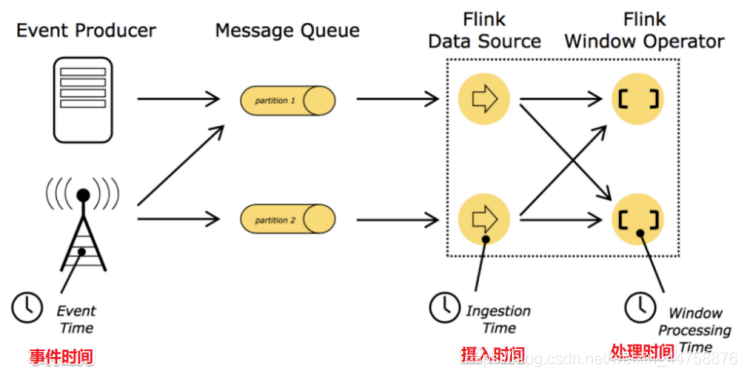
Event Time: 是事件创建的时间。它通常由事件中的时间戳描述, 例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事件时间戳。
Ingestion Time: 是数据进入 Flink 的时间。
Processing Time: 是每一个执行基于时间操作的算子的本地系统时间, 与机器相关, 默认的时间属性就是 Processing Time。
2. EventTime的重要性
在 Flink 的流式处理中, 绝大部分的业务都会使用 eventTime, 一般只在eventTime 无法使用时, 才会被迫使用 ProcessingTime 或者 IngestionTime。
如果要使用 EventTime,那么需要引入 EventTime 的时间属性,引入方式如下所示:
1 | val env = StreamExecutionEnvironment.getExecutionEnvironment |
3. Watermark
3.1 基本概念
我们知道,流处理从事件产生,到流经 source,再到 operator,中间是有一个过程和时间的, 虽然大部分情况下, 流到 operator 的数据都是按照事件产生的时间顺序来的, 但是也不排除由于网络、分布式等原因, 导致乱序的产生, 所谓乱序, 就是指 Flink 接收到的事件的先后顺序不是严格按照事件的 Event Time 顺序排列的。
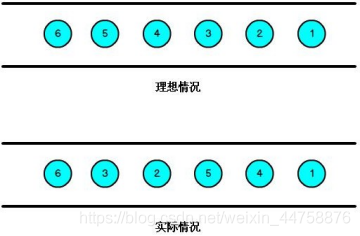
那么此时出现一个问题,一旦出现乱序,如果只根据 eventTime 决定 window 的运行, 我们不能明确数据是否全部到位, 但又不能无限期的等下去, 此时必须要有个机制来保证一个特定的时间后, 必须触发 window 去进行计算了, 这个特别的机制, 就是 Watermark。
- Watermark 是一种衡量 Event Time 进展的机制。
- Watermark 是用于处理乱序事件的, 而正确的处理乱序事件, 通常用Watermark 机制结合 window 来实现。
- 数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了, 因此, window 的执行也是由 Watermark 触发的。
- Watermark 可以理解成一个延迟触发机制,我们可以设置 Watermark 的延时时长 t,每次系统会校验已经到达的数据中最大的 maxEventTime,然后认定 eventTime小于 maxEventTime - t 的所有数据都已经到达, 如果有窗口的停止时间等于maxEventTime – t, 那么这个窗口被触发执行。
有序流的 Watermarker 如下图所示( Watermark 设置为 0):
乱序流的 Watermarker 如下图所示( Watermark 设置为 2):

当 Flink 接收到数据时, 会按照一定的规则去生成 Watermark, 这条 Watermark 就等于当前所有到达数据中的 maxEventTime - 延迟时长,也就是说,Watermark 是基于数据携带的时间戳生成的, 一旦 Watermark 比当前未触发的窗口的停止时间要晚, 那么就会触发相应窗口的执行。由于 event time 是由数据携带的, 因此, 如果运行过程中无法获取新的数据, 那么没有被触发的窗口将永远都不被触发。
上图中,我们设置的允许最大延迟到达时间为 2s,所以时间戳为 7s 的事件对应的 Watermark 是 5s, 时间戳为 12s 的事件的 Watermark 是 10s, 如果我们的窗口 1 是 1s~5s, 窗口 2 是 6s~10s, 那么时间戳为 7s 的事件到达时的 Watermarker 恰好触发窗口 1, 时间戳为 12s 的事件到达时的 Watermark 恰好触发窗口 2。
Watermark 就是触发前一窗口的“关窗时间”, 一旦触发关门那么以当前时刻为准在窗口范围内的所有所有数据都会收入窗中。
只要没有达到水位那么不管现实中的时间推进了多久都不会触发关窗。
3.2 Watermark 的引入
watermark 的引入很简单, 对于乱序数据, 最常见的引用方式如下:
1 | dataStream.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.milliseconds(1000)) { |
Event Time 的使用一定要指定数据源中的时间戳。否则程序无法知道事件的事件时间是什么(数据源里的数据没有时间戳的话, 就只能使用 Processing Time 了)。我们看到上面的例子中创建了一个看起来有点复杂的类, 这个类实现的其实就是分配时间戳的接口。Flink 暴露了 TimestampAssigner 接口供我们实现, 使我们可以自定义如何从事件数据中抽取时间戳。
1 | val env = StreamExecutionEnvironment.getExecutionEnvironment |
MyAssigner 有两种类型
- AssignerWithPeriodicWatermarks
- AssignerWithPunctuatedWatermarks
以上两个接口都继承自 TimestampAssigner
Assigner with periodic watermarks
周期性的生成 watermark: 系统会周期性的将 watermark 插入到流中(水位线也是一种特殊的事件)。默认周期是 200 毫秒。可以使用ExecutionConfig.setAutoWatermarkInterval()方法进行设置。
1 | val env = StreamExecutionEnvironment.getExecutionEnvironment |
产生 watermark 的逻辑: 每隔 5 秒钟, Flink 会调用
AssignerWithPeriodicWatermarks 的 getCurrentWatermark()方法。如果方法返回一个时间戳大于之前水位的时间戳, 新的 watermark 会被插入到流中。这个检查保证了水位线是单调递增的。如果方法返回的时间戳小于等于之前水位的时间戳, 则不会产生新的 watermark。
例:自定义一个周期性的时间戳抽取
1 | class PeriodicAssigner extends AssignerWithPeriodicWatermarks[SensorReading] { |
一种简单的特殊情况是, 如果我们事先得知数据流的时间戳是单调递增的, 也就是说没有乱序, 那我们可以使用 assignAscendingTimestamps, 这个方法会直接使用数据的时间戳生成 watermark。
1 | val stream: DataStream[SensorReading] = ... |
而对于乱序数据流, 如果我们能大致估算出数据流中的事件的最大延迟时间, 就可以使用如下代码:
1 | val stream: DataStream[SensorReading] = ... |
Assigner with punctuated watermarks
间断式地生成 watermark。和周期性生成的方式不同,这种方式不是固定时间的, 而是可以根据需要对每条数据进行筛选和处理。直接上代码来举个例子, 我们只给sensor_1 的传感器的数据流插入 watermark:
1 | class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[SensorReading] { |
4. EventTime 在window 中的使用
4.1 滚动窗口(TumblingEventTimeWindows)
1 | def main(args: Array[String]): Unit = { |
结果是按照 Event Time 的时间窗口计算得出的,而无关系统的时间(包括输入的快慢)。
4.2 滑动窗口(SlidingEventTimeWindows)
1 | def main(args: Array[String]): Unit = { |
4.3 会话窗口(EventTimeSessionWindows)
相邻两次数据的 EventTime 的时间差超过指定的时间间隔就会触发执行。如果加入 Watermark,会在符合窗口触发的情况下进行延迟,到达延迟水位再进行窗口触发。
1 | def main(args: Array[String]): Unit = { |
八、ProcessFunction API(底层 API)
我们之前学习的转换算子是无法访问事件的时间戳信息和水位线信息的。而这 在一些应用场景下, 极为重要。例如 MapFunction 这样的 map 转换算子就无法访问时间戳或者当前事件的事件时间。
基于此, DataStream API 提供了一系列的 Low-Level 转换算子。可以访问时间戳、watermark 以及注册定时事件。还可以输出特定的一些事件,例如超时事件等。Process Function 用来构建事件驱动的应用以及实现自定义的业务逻辑(使用之前的window 函数和转换算子无法实现)。例如, Flink SQL 就是使用 Process Function 实现的。
Flink 提供了 8 个 Process Function:
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- ProcessJoinFunction
- BroadcastProcessFunction
- KeyedBroadcastProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
1. KeyedProcessFunction
KeyedProcessFunction 用来操作 KeyedStream。KeyedProcessFunction 会处理流的每一个元素,输出为 0 个、1 个或者多个元素。所有的 Process Function 都继承自RichFunction 接口, 所以都有 open()、close()和 getRuntimeContext()等方法。而KeyedProcessFunction[KEY, IN, OUT] 还额外提供了两个方法:
- processElement(v: IN, ctx: Context, out: Collector[OUT]), 流中的每一个元素都会调用这个方法, 调用结果将会放在 Collector 数据类型中输出。Context 可以访问元素的时间戳,元素的 key,以及 TimerService 时间服务。Context 还可以将结果输出到别的流(side outputs)。
- onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT])是一个回调函数。当之前注册的定时器触发时调用。参数 timestamp 为定时器所设定的触发的时间戳。Collector 为输出结果的集合。OnTimerContext 和processElement 的 Context 参数一样,提供了上下文的一些信息,例如定时器触发的时间信息(事件时间或者处理时间)。
2. TimerService 和 定时器(Timers)
Context 和 OnTimerContext 所持有的 TimerService 对象拥有以下方法:
- currentProcessingTime(): Long 返回当前处理时间
- currentWatermark(): Long 返回当前 watermark 的时间戳
- registerProcessingTimeTimer(timestamp: Long): Unit 会注册当前 key 的 processing time 的定时器。当 processing time 到达定时时间时, 触发 timer
- registerEventTimeTimer(timestamp: Long): Unit 会注册当前 key 的 event time 定时器。当水位线大于等于定时器注册的时间时,触发定时器执行回调函数
- deleteProcessingTimeTimer(timestamp: Long): Unit 删除之前注册处理时间定时器。如果没有这个时间戳的定时器, 则不执行
- deleteEventTimeTimer(timestamp: Long): Unit 删除之前注册的事件时间定时器, 如果没有此时间戳的定时器, 则不执行
当定时器 timer 触发时, 会执行回调函数 onTimer()。注意定时器 timer 只能在keyed streams 上面使用。
下面举个例子说明 KeyedProcessFunction 如何操作 KeyedStream。
- 需求: 监控温度传感器的温度值, 如果温度值在一秒钟之内(processing time)连续上升, 则报警。
1 | val warnings = readings |
看一下 TempIncreaseAlertFunction 如何实现, 程序中使用了 ValueState 这样一个 状态变量
1 | class TempIncreaseAlertFunction extends KeyedProcessFunction[String, SensorReading, String] { |
3. 侧输出流(SideOutput)
大部分的 DataStream API 的算子的输出是单一输出,也就是某种数据类型的流。除了 split 算子, 可以将一条流分成多条流, 这些流的数据类型也都相同。process function 的 side outputs 功能可以产生多条流, 并且这些流的数据类型可以不一样。一个 side output 可以定义为 OutputTag[X]对象, X 是输出流的数据类型。process function 可以通过 Context 对象发射一个事件到一个或者多个 side outputs。
下面是一个示例程序:
1 | val monitoredReadings: DataStream[SensorReading] = readings.process(new FreezingMonitor) |
接下来我们实现 FreezingMonitor 函数,用来监控传感器温度值,将温度值低于32F 的温度输出到 side output
1 | class FreezingMonitor extends ProcessFunction[SensorReading, SensorReading] { |
4. CoProcessFunction
对于两条输入流, DataStream API 提供了 CoProcessFunction 这样的 low-level 操作。CoProcessFunction 提供了操作每一个输入流的方法: processElement1()和processElement2()。
类似于 ProcessFunction, 这两种方法都通过 Context 对象来调用。这个 Context 对象可以访问事件数据, 定时器时间戳, TimerService, 以及 side outputs。
CoProcessFunction 也提供了 onTimer()回调函数。
九、状态编程和容错机制
流式计算分为无状态和有状态两种情况。无状态的计算观察每个独立事件, 并根据最后一个事件输出结果。例如, 流处理应用程序从传感器接收温度读数, 并在温度超过 90 度时发出警告。有状态的计算则会基于多个事件输出结果。以下是一些例子:
- 所有类型的窗口。例如, 计算过去一小时的平均温度,就是有状态的计算
- 所有用于复杂事件处理的状态机。例如,若在一分钟内收到两个相差 20 度以上的温度读数, 则发出警告, 这是有状态的计算
- 流与流之间的所有关联操作, 以及流与静态表或动态表之间的关联操作, 都是有状态的计算
下图展示了无状态流处理和有状态流处理的主要区别。无状态流处理分别接收每条数据记录(图中的黑条),然后根据最新输入的数据生成输出数据(白条);有状态流处理会维护状态(根据每条输入记录进行更新), 并基于最新输入的记录和当前的状态值生成输出记录(灰条)
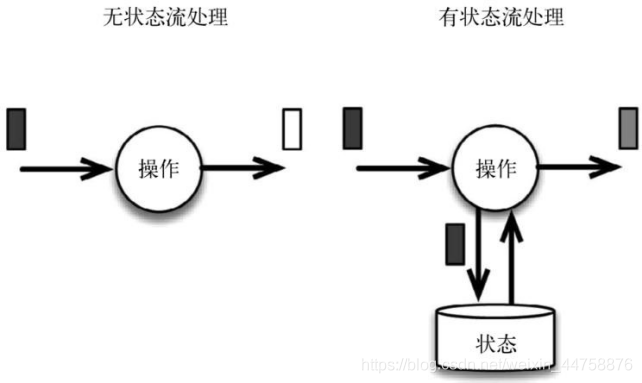
上图中输入数据由黑条表示。无状态流处理每次只转换一条输入记录, 并且仅根据最新的输入记录输出结果(白条)。有状态流处理维护所有已处理记录的状态值, 并根据每条新输入的记录更新状态,因此输出记录(灰条)反映的是综合考虑多个事件之后的结果。
尽管无状态的计算很重要, 但是流处理对有状态的计算更感兴趣。事实上, 正确地实现有状态的计算比实现无状态的计算难得多。旧的流处理系统并不支持有状 态的计算, 而新一代的流处理系统则将状态及其正确性视为重中之重。
1. 有状态的算子和应用程序
Flink 内置的很多算子,数据源 source,数据存储 sink 都是有状态的,流中的数据都是 buffer records,会保存一定的元素或者元数据。例如: ProcessWindowFunction 会缓存输入流的数据, ProcessFunction 会保存设置的定时器信息等等。
在 Flink 中, 状态始终与特定算子相关联。总的来说, 有两种类型的状态:
- 算子状态( operator state)
- 键控状态( keyed state)
1.1 算子状态(operator state)
算子状态的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态, 状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问。
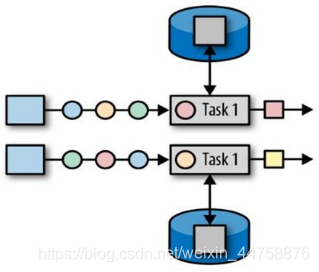
Flink 为算子状态提供三种基本数据结构:
- 列表状态(List state)
- 将状态表示为一组数据的列表
- 联合列表状态(Union list state)
- 也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保 存点(savepoint)启动应用程序时如何恢复
- 广播状态(Broadcast state)
- 如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态
1.2 键控状态(keyed state)
键控状态是根据输入数据流中定义的键(key)来维护和访问的。Flink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个 key 对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key。因此,具有相同 key 的所有数据都会访问相同的状态。Keyed State 很类似于一个分布式的 key-value map 数据结构,只能用于 KeyedStream( keyBy 算子处理之后)
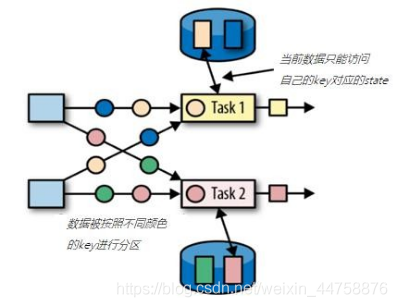
Flink 的 Keyed State 支持以下数据类型:
- ValueState[T]保存单个的值,值的类型为 T
- get 操作: ValueState.value()
- set 操作: ValueState.update(value: T)
- ListState[T]保存一个列表,列表里的元素的数据类型为 T。基本操作如下:
- ListState.add(value: T)
- ListState.addAll(values: java.util.List[T])
- oListState.get() 返回 Iterable[T]
- ListState.update(values: java.util.List[T])
- MapState[K, V]保存 Key-Value 对
- MapState.get(key: K)
- MapState.put(key: K, value: V)
- MapState.contains(key: K)
- MapState.remove(key: K)
- ReducingState[T]
- AggregatingState[I, O]
State.clear()是清空操作
1 | val sensorData: DataStream[SensorReading] = ... |
通过 RuntimeContext 注册 StateDescriptor。StateDescriptor 以状态 state 的名字和存储的数据类型为参数。
在 open()方法中创建 state 变量。注意复习之前的 RichFunction 相关知识。
接下来我们使用了 FlatMap with keyed ValueState 的快捷方式 flatMapWithState 实现以上需求:
1 | val alerts: DataStream[(String, Double, Double)] = keyedSensorData |
2. 状态一致性
当在分布式系统中引入状态时, 自然也引入了一致性问题。一致性实际上是" 正确性级别"的另一种说法,也就是说在成功处理故障并恢复之后得到的结果,与没 有发生任何故障时得到的结果相比, 前者到底有多正确? 举例来说, 假设要对最近一小时登录的用户计数。在系统经历故障之后, 计数结果是多少? 如果有偏差, 是有漏掉的计数还是重复计数?
2.1 一致性级别
在流处理中, 一致性可以分为 3 个级别:
- at-most-once: 这其实是没有正确性保障的委婉说法——故障发生之后, 计数结果可能丢失。同样的还有 udp
- at-least-once: 这表示计数结果可能大于正确值, 但绝不会小于正确值。也就是说, 计数程序在发生故障后可能多算, 但是绝不会少算
- exactly-once: 这指的是系统保证在发生故障后得到的计数结果与正确值一致
曾经, at-least-once 非常流行。第一代流处理器(如 Storm 和 Samza)刚问世时只保证 at-least-once, 原因有二:
- 保证 exactly-once 的系统实现起来更复杂。这在基础架构层(决定什么代表正确, 以及 exactly-once 的范围是什么)和实现层都很有挑战性
- 流处理系统的早期用户愿意接受框架的局限性, 并在应用层想办法弥补(例如使应用程序具有幂等性, 或者用批量计算层再做一遍计算)
最先保证 exactly-once 的系统(Storm Trident 和 Spark Streaming)在性能和表现力这两个方面付出了很大的代价。为了保证 exactly-once,这些系统无法单独地对每条记录运用应用逻辑, 而是同时处理多条(一批)记录, 保证对每一批的处理要么全部成功,要么全部失败。这就导致在得到结果前,必须等待一批记录处理结束。因此, 用户经常不得不使用两个流处理框架(一个用来保证 exactly-once, 另一个用来对每个元素做低延迟处理), 结果使基础设施更加复杂。曾经, 用户不得不在保证exactly-once 与获得低延迟和效率之间权衡利弊。Flink 避免了这种权衡。
Flink 的一个重大价值在于,它既保证了 exactly-once, 也具有低延迟和高吞吐的处理能力。
从根本上说,Flink 通过使自身满足所有需求来避免权衡,它是业界的一次意义重大的技术飞跃。尽管这在外行看来很神奇, 但是一旦了解, 就会恍然大悟。
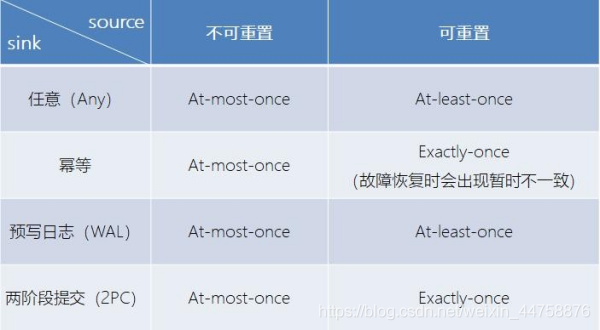
2.2 端到端(end-to-end)状态一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在 Flink 流处理器内部保证的; 而在真实应用中, 流处理应用除了流处理器以外还包含了数据源( 例如 Kafka) 和输出到持久化系统。
端到端的一致性保证, 意味着结果的正确性贯穿了整个流处理应用的始终; 每一个组件都保证了它自己的一致性, 整个端到端的一致性级别取决于所有组件中一致性最弱的组件。具体可以划分如下:
- 内部保证 —— 依赖 checkpoint
- source 端 —— 需要外部源可重设数据的读取位置
- sink 端 —— 需要保证从故障恢复时, 数据不会重复写入外部系统
而对于 sink 端, 又有两种具体的实现方式: 幂等( Idempotent) 写入和事务性( Transactional) 写入。
- 幂等写入
- 所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改, 也就是说, 后面再重复执行就不起作用了
- 事务写入
- 需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候, 才把所有对应的结果写入 sink 系统中
对于事务性写入, 具体又有两种实现方式: 预写日志( WAL) 和两阶段提交( 2PC)。DataStream API 提供了 GenericWriteAheadSink 模板类和 TwoPhaseCommitSinkFunction 接口, 可以方便地实现这两种方式的事务性写入。
不同 Source 和 Sink 的一致性保证可以用下表说明:
3. 检查点(checkpoint)
Flink 具体如何保证 exactly-once 呢? 它使用一种被称为"检查点"(checkpoint)的特性,在出现故障时将系统重置回正确状态。下面通过简单的类比来解释检查点 的作用。
假设你和两位朋友正在数项链上有多少颗珠子,如下图所示。你捏住珠子,边数边拨,每拨过一颗珠子就给总数加一。你的朋友也这样数他们手中的珠子。当你分神忘记数到哪里时,怎么办呢? 如果项链上有很多珠子,你显然不想从头再数一 遍,尤其是当三人的速度不一样却又试图合作的时候,更是如此(比如想记录前一分钟三人一共数了多少颗珠子,回想一下一分钟滚动窗口)。
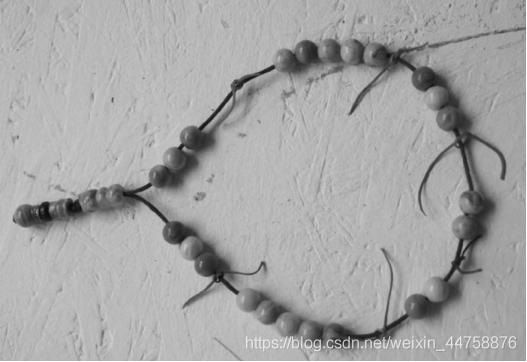
于是,你想了一个更好的办法:在项链上每隔一段就松松地系上一根有色皮筋,将珠子分隔开;当珠子被拨动的时候,皮筋也可以被拨动; 然后,你安排一个助手, 让他在你和朋友拨到皮筋时记录总数。用这种方法,当有人数错时,就不必从头开始数。相反,你向其他人发出错误警示,然后你们都从上一根皮筋处开始重数,助手则会告诉每个人重数时的起始数值,例如在粉色皮筋处的数值是多少。
Flink 检查点的作用就类似于皮筋标记。数珠子这个类比的关键点是:对于指定的皮筋而言,珠子的相对位置是确定的; 这让皮筋成为重新计数的参考点。总状态(珠子的总数)在每颗珠子被拨动之后更新一次,助手则会保存与每根皮筋对应的检查点状态,如当遇到粉色皮筋时一共数了多少珠子,当遇到橙色皮筋时又是多少。当问题出现时,这种方法使得重新计数变得简单。
3.1 Flink的检查点算法
Flink 检查点的核心作用是确保状态正确,即使遇到程序中断,也要正确。记住 这一基本点之后,我们用一个例子来看检查点是如何运行的。Flink 为用户提供了用 来定义状态的工具。例如,以下这个 Scala 程序按照输入记录的第一个字段(一个字 符串)进行分组并维护第二个字段的计数状态。
1 | val stream: DataStream[(String, Int)] = ... |
该程序有两个算子: keyBy 算子用来将记录按照第一个元素(一个字符串)进行分 组,根据该 key 将数据进行重新分区,然后将记录再发送给下一个算子: 有状态的 map 算子(mapWithState)。map 算子在接收到每个元素后,将输入记录的第二个字段 的数据加到现有总数中,再将更新过的元素发射出去。下图表示程序的初始状态: 输 入流中的 6 条记录被检查点分割线(checkpoint barrier)隔开,所有的 map 算子状态均为 0(计数还未开始)。所有 key 为 a 的记录将被顶层的 map 算子处理,所有 key 为 b 的记录将被中间层的 map 算子处理,所有 key 为 c 的记录则将被底层的 map 算子处理。

上图是程序的初始状态。注意,a、b、c 三组的初始计数状态都是 0,即三个圆 柱上的值。ckpt 表示检查点分割线(checkpoint barriers)。每条记录在处理顺序上 严格地遵守在检查点之前或之后的规定,例如[“b”,2]在检查点之前被处理,[“a”,2] 则在检查点之后被处理。
当该程序处理输入流中的 6 条记录时,涉及的操作遍布 3 个并行实例(节点、CPU 内核等)。那么,检查点该如何保证 exactly-once 呢?
检查点分割线和普通数据记录类似。它们由算子处理,但并不参与计算,而是 会触发与检查点相关的行为。当读取输入流的数据源(在本例中与 keyBy 算子内联) 遇到检查点屏障时,它将其在输入流中的位置保存到持久化存储中。如果输入流来 自消息传输系统(Kafka),这个位置就是偏移量。Flink 的存储机制是插件化的,持久 化存储可以是分布式文件系统,如 HDFS。下图展示了这个过程(遇到 checkpoint barrier 时, 保存其在输入流中的位置)
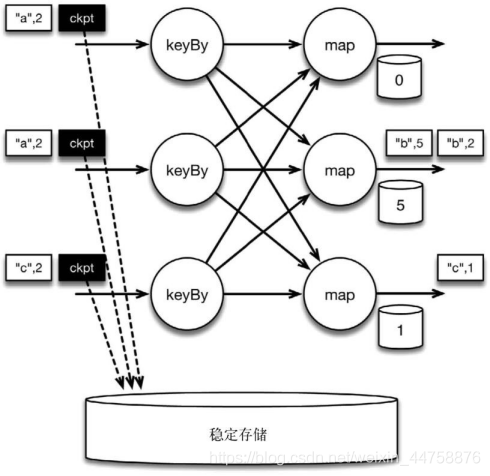
当 Flink 数据源(在本例中与 keyBy 算子内联)遇到检查点分界线(barrier)时, 它会将其在输入流中的位置保存到持久化存储中。这让 Flink 可以根据该位置重启。
检查点像普通数据记录一样在算子之间流动。当 map 算子处理完前 3 条数据并 收到检查点分界线时,它们会将状态以异步的方式写入持久化存储,如下图所示(保存 map 算子状态, 也就是当前各个 key 的计数值)
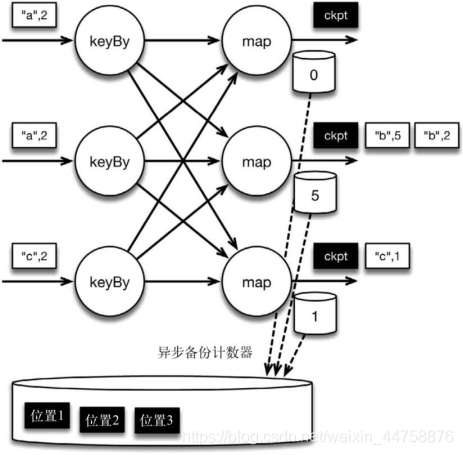
位于检查点之前的所有记录([“b”,2]、[“b”,3]和[“c”,1])被 map 算子处理之后的情 况。此时,持久化存储已经备份了检查点分界线在输入流中的位置(备份操作发生在 barrier 被输入算子处理的时候)。map 算子接着开始处理检查点分界线,并触发将状 态异步备份到稳定存储中这个动作。
当 map 算子的状态备份和检查点分界线的位置备份被确认之后,该检查点操作 就可以被标记为完成,如下图所示。我们在无须停止或者阻断计算的条件下,在一 个逻辑时间点(对应检查点屏障在输入流中的位置)为计算状态拍了快照。通过确保 备份的状态和位置指向同一个逻辑时间点,后文将解释如何基于备份恢复计算,从 而保证 exactly-once。值得注意的是,当没有出现故障时,Flink 检查点的开销极小, 检查点操作的速度由持久化存储的可用带宽决定。回顾数珠子的例子: 除了因为数 错而需要用到皮筋之外,皮筋会被很快地拨过。
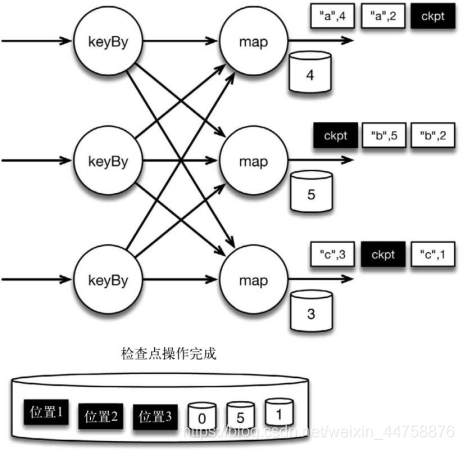
检查点操作完成,状态和位置均已备份到稳定存储中。输入流中的所有数据记 录都已处理完成。值得注意的是,备份的状态值与实际的状态值是不同的。备份反 映的是检查点的状态。
如果检查点操作失败,Flink 可以丢弃该检查点并继续正常执行,因为之后的某 一个检查点可能会成功。虽然恢复时间可能更长,但是对于状态的保证依旧很有力。 只有在一系列连续的检查点操作失败之后,Flink 才会抛出错误,因为这通常预示着 发生了严重且持久的错误。
现在来看看下图所示的情况:检查点操作已经完成,但故障紧随其后(故障紧跟检查点, 导致最底部的实例丢失)
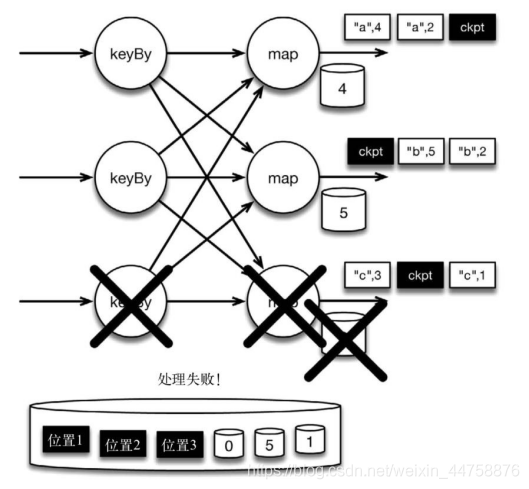
在这种情况下(故障时的状态恢复),Flink 会重新拓扑(可能会获取新的执行资源),将输入流倒回到 上一个检查点,然后恢复状态值并从该处开始继续计算。在本例中,[“a”,2]、[“a”,2] 和[“c”,2]这几条记录将被重播。
下图展示了这一重新处理过程。从上一个检查点开始重新计算,可以保证在剩 下的记录被处理之后,得到的 map 算子的状态值与没有发生故障时的状态值一致。
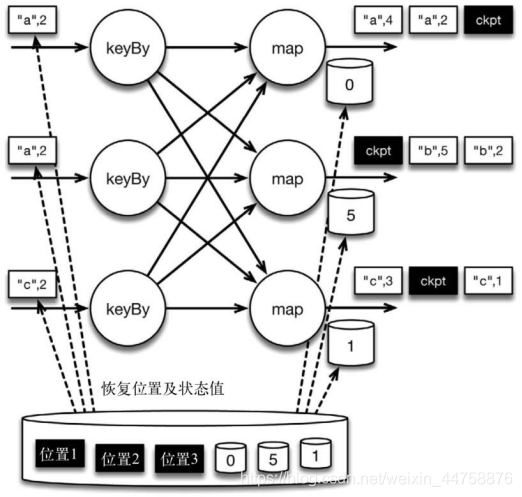
Flink 将输入流倒回到上一个检查点屏障的位置,同时恢复 map 算子的状态值。 然后,Flink 从此处开始重新处理。这样做保证了在记录被处理之后,map 算子的状 态值与没有发生故障时的一致。
Flink 检查点算法的正式名称是异步分界线快照(asynchronous barrier snapshotting)。该算法大致基于 Chandy-Lamport 分布式快照算法。
检查点是 Flink 最有价值的创新之一,因为它使 Flink 可以保证 exactly-once, 并且不需要牺牲性能。
3.2 Flink+Kafka 如何实现端到端的 exactly-once 语义
我们知道,端到端的状态一致性的实现,需要每一个组件都实现,对于 Flink + Kafka 的数据管道系统(Kafka 进、Kafka 出)而言,各组件怎样保证 exactly-once 语义呢?
- 内部 —— 利用 checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
- source —— kafka consumer 作为 source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
- sink —— kafka producer 作为 sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
内部的 checkpoint 机制我们已经有了了解,那 source 和 sink 具体又是怎样运行 的呢?接下来我们逐步做一个分析。
我们知道 Flink 由 JobManager 协调各个 TaskManager 进行 checkpoint 存储, checkpoint 保存在 StateBackend 中,默认 StateBackend 是内存级的,也可以改为文件级的进行持久化保存。
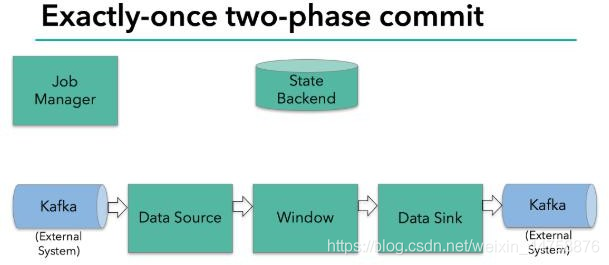
当 checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流; barrier 会在算子间传递下去。
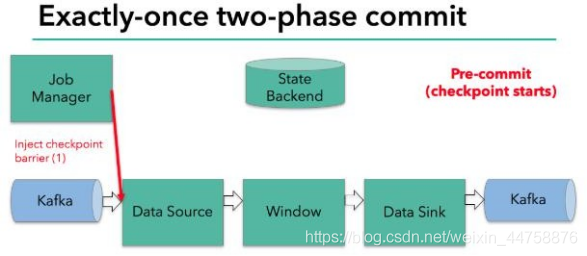
每个算子会对当前的状态做个快照,保存到状态后端。对于 source 任务而言, 就会把当前的 offset 作为状态保存起来。下次从 checkpoint 恢复时,source 任务可以重新提交偏移量,从上次保存的位置开始重新消费数据。
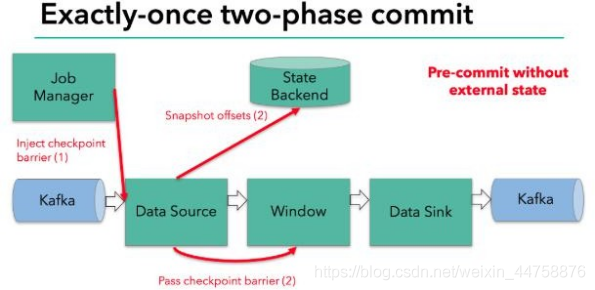
每个内部的 transform 任务遇到 barrier 时,都会把状态存到 checkpoint 里。
sink 任务首先把数据写入外部 kafka,这些数据都属于预提交的事务(还不能被消费);当遇到 barrier 时,把状态保存到状态后端,并开启新的预提交事务。
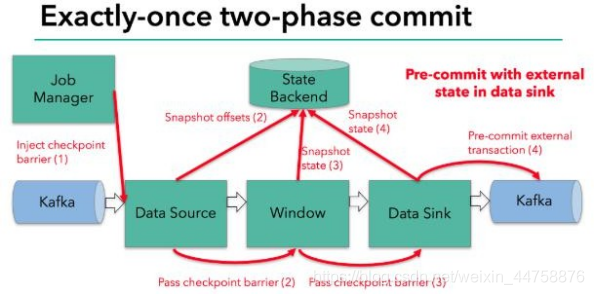
当所有算子任务的快照完成,也就是这次的 checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 checkpoint 完成。
当 sink 任务收到确认通知,就会正式提交之前的事务,kafka 中未确认的数据 就改为“已确认”,数据就真正可以被消费了。
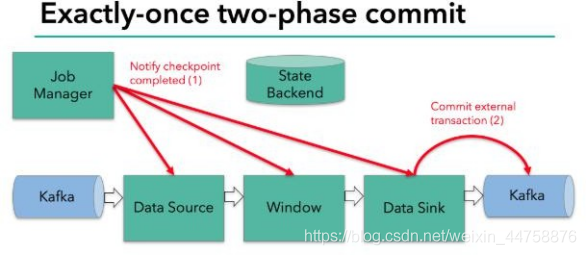
所以我们看到,执行过程实际上是一个两段式提交,每个算子执行完成,会进 行“预提交”,直到执行完 sink 操作,会发起“确认提交”,如果执行失败,预提 交会放弃掉。
具体的两阶段提交步骤总结如下:
- 第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”
- jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
- sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
- sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
- 外部 kafka 关闭事务,提交的数据可以正常消费了
所以我们也可以看到,如果宕机需要通过 StateBackend 进行恢复,只能恢复所有确认提交的操作。
4. 选择一个状态后端(state backend)
- MemoryStateBackend
- 内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在 TaskManager 的 JVM 堆上;而将 checkpoint 存储在 JobManager 的内存中
- FsStateBackend
- 将 checkpoint 存到远程的持久化文件系统(FileSystem)上。而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上
- RocksDBStateBackend
- 将所有状态序列化后,存入本地的 RocksDB 中存储
注:RocksDB 的支持并不直接包含在 flink 中,需要引入依赖:
1 | <dependency> |
设置状态后端为 FsStateBackend:
1 | val env = StreamExecutionEnvironment.getExecutionEnvironment |
4. Savepoint
4.1 Savepoint介绍
Savepoint:保存点,类似于以前玩游戏的时候,遇到难关了/遇到boss了,赶紧手动存个档,然后接着玩,如果失败了,赶紧从上次的存档中恢复,然后接着玩。
在实际开发中,可能会遇到这样的情况:如要对集群进行停机维护/扩容
那么这时候需要执行一次Savepoint也就是执行一次手动的Checkpoint/也就是手动的发一个barrier栅栏,那么这样的话,程序的所有状态都会被执行快照并保存,当维护/扩容完毕之后,可以从上一次Savepoint的目录中进行恢复!
4.2 Savepoint VS Checkpoint
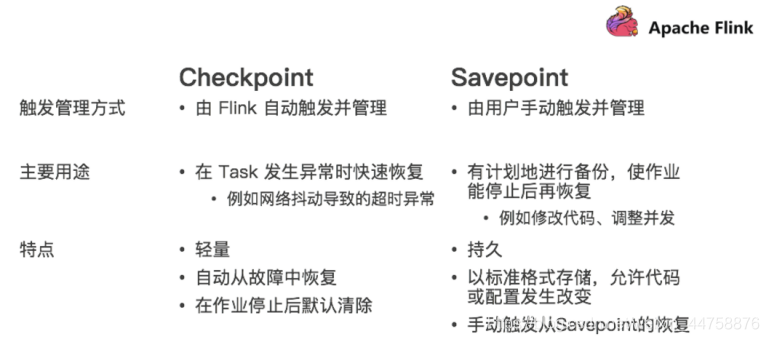
- 目标
- 从概念上讲,Savepoints和Checkpoints的不同之处类似于传统数据库中备份和恢复日志的不同。Checkpoints的作用是确保程序有潜在失败可能的情况下(如网络暂时异常),可以正常恢复。相反,Savepoints的作用是让用户手动触发备份后,通过重启来恢复程序
- 实现
- Checkpoints和Savepoints在实现上有所不同。Checkpoints轻量并且快速,它可以利用底层状态存储的各种特性,来实现快速备份和恢复。例如,以RocksDB作为状态存储,状态将会以RocksDB的格式持久化而不是Flink原生的格式,同时利用RocksDB的特性实现了增量Checkpoints。这个特性加速了checkpointing的过程,也是Checkpointing机制中第一个更轻量的实现。相反,Savepoints更注重数据的可移植性,并且支持任何对任务的修改,同时这也让Savepoints的备份和恢复成本相对更高。
- 生命周期
- Checkpoints本身是定时自动触发的。它们的维护、创建和删除都由Flink自身来操作,不需要任何用户的干预。相反,Savepoints的触发、删除和管理等操作都需要用户手动触发。
| 维度 | Checkpoints | Savepoints |
|---|---|---|
| 目标 | 任务失败的恢复/故障转移机制 | 手动备份/重启/恢复任务 |
| 实现 | 轻量快速 | 注重可移植性,成本较高 |
| 生命周期 | Flink自身控制 | 用户手动控制 |
4.3 Savepoint演示
- 启动yarn session
/export/server/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d - 运行job-会自动执行Checkpoint
/export/server/flink/bin/flink run --class cn.itcast.checkpoint.CheckpointDemo01 /root/ckp.jar - 手动创建savepoint–相当于手动做了一次Checkpoint
/export/server/flink/bin/flink savepoint 702b872ef80f08854c946a544f2ee1a5 hdfs://node1:8020/flink-checkpoint/savepoint/ - 停止job
/export/server/flink/bin/flink cancel 702b872ef80f08854c946a544f2ee1a5 - 重新启动job,手动加载savepoint数据
/export/server/flink/bin/flink run -s hdfs://node1:8020/flink-checkpoint/savepoint/savepoint-702b87-0a11b997fa70 --class cn.itcast.checkpoint.CheckpointDemo01 /root/ckp.jar - 停止yarn session
yarn application -kill application_1607782486484_0014
5. 关于并行度
一个Flink程序由多个Operator组成(source、transformation和 sink)。
一个Operator由多个并行的Task(线程)来执行,一个Operator的并行Task(线程)数目就被称为该Operator(任务)的并行度(Parallel)
并行度可以有如下几种指定方式:
- Operator Level(算子级别)(可以使用)
一个算子、数据源和sink的并行度可以通过调用 setParallelism()方法来指定

- Execution Environment Level(Env级别)(可以使用)
执行环境(任务)的默认并行度可以通过调用setParallelism()方法指定。为了以并行度3来执行所有的算子、数据源和data sink, 可以通过如下的方式设置执行环境的并行度:
执行环境的并行度可以通过显式设置算子的并行度而被重写
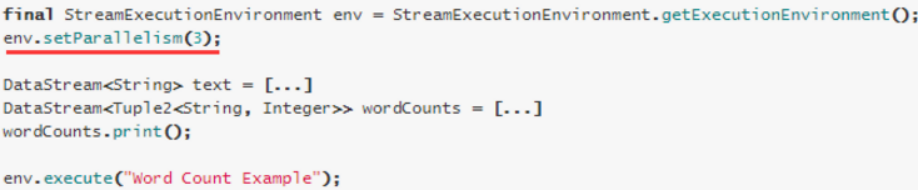
- Client Level(客户端级别,推荐使用)(可以使用)
并行度可以在客户端将job提交到Flink时设定
对于CLI客户端,可以通过-p参数指定并行度:
./bin/flink run -p 10 WordCount-java.jar - System Level(系统默认级别,尽量不使用)
在系统级可以通过设置flink-conf.yaml文件中的parallelism.default属性来指定所有执行环境的默认并行度
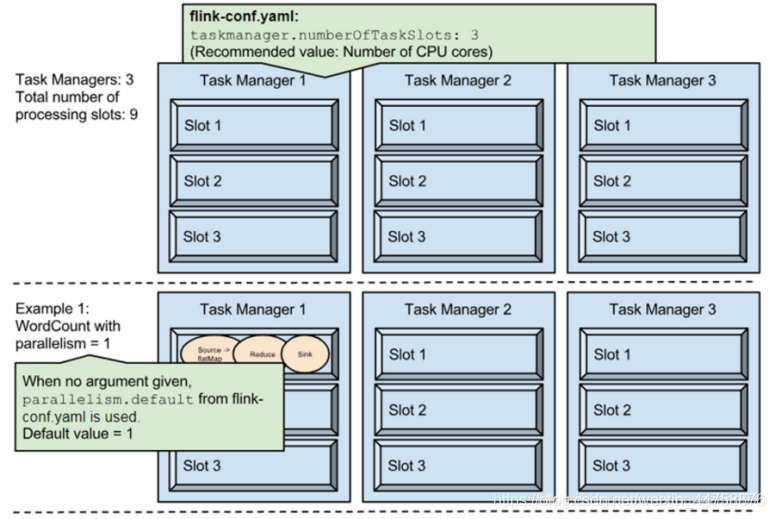
- Example1:
- 在fink-conf.yaml中 taskmanager.numberOfTaskSlots 默认值为1,即每个Task Manager上只有一个Slot ,此处是3
- Example1中,WordCount程序设置了并行度为1,意味着程序 Source、Reduce、Sink在一个Slot中,占用一个Slot
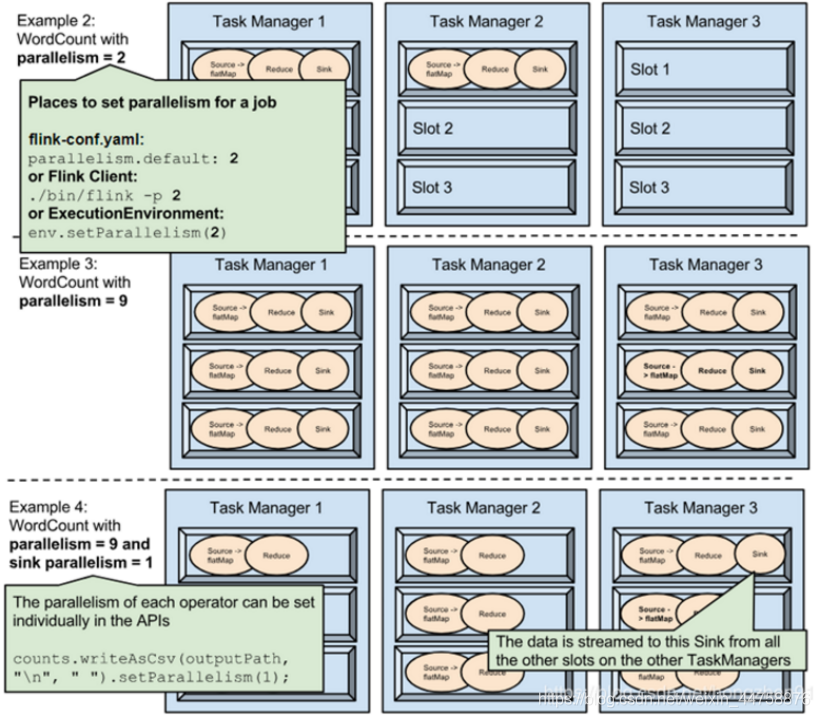
- Example2:
- 通过设置并行度为2后,将占用2个Slot
- Example3:
- 通过设置并行度为9,将占用9个Slot
- Example4:
- 通过设置并行度为9,并且设置sink的并行度为1,则Source、Reduce将占用9个Slot,但是Sink只占用1个Slot
注:
- 并行度的优先级:算子级别 > env级别 > Client级别 > 系统默认级别 (越靠前具体的代码并行度的优先级越高)
- 如果source不可以被并行执行,即使指定了并行度为多个,也不会生效
- 在实际生产中,我们推荐在算子级别显示指定各自的并行度,方便进行显示和精确的资源控制
- slot是静态的概念,是指taskmanager具有的并发执行能力; parallelism是动态的概念,是指程序运行时实际使用的并发能力
十、Table API 与SQL
Table API 是流处理和批处理通用的关系型 API,Table API 可以基于流输入或者批输入来运行而不需要进行任何修改。Table API 是 SQL 语言的超集并专门为 Apache Flink 设计的,Table API 是 Scala 和 Java 语言集成式的 API。与常规 SQL 语言中将查询指定为字符串不同,Table API 查询是以 Java 或 Scala 中的语言嵌入样式来定义的, 具有 IDE 支持如:自动完成和语法检测。
1. Table API & SQL的特点
Flink之所以选择将 Table API & SQL 作为未来的核心 API,是因为其具有一些非常重要的特点:

- 声明式:属于设定式语言,用户只要表达清楚需求即可,不需要了解底层执行
- 高性能:可优化,内置多种查询优化器,这些查询优化器可为 SQL 翻译出最优执行计划
- 简单易学:易于理解,不同行业和领域的人都懂,学习成本较低
- 标准稳定:语义遵循SQL标准,非常稳定,在数据库 30 多年的历史中,SQL 本身变化较少
- 流批统一:可以做到API层面上流与批的统一,相同的SQL逻辑,既可流模式运行,也可批模式运行,Flink底层Runtime本身就是一个流与批统一的引擎
2. Table API & SQL发展历程
2.1 架构升级
自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 Flink 打造新一代计算引擎,针对 Flink 存在的不足进行优化和改进,并且在 2019 年初将最终代码开源,也就是Blink。Blink 在原来的 Flink 基础上最显著的一个贡献就是 Flink SQL 的实现。随着版本的不断更新,API 也出现了很多不兼容的地方。
在 Flink 1.9 中,Table 模块迎来了核心架构的升级,引入了阿里巴巴Blink团队贡献的诸多功能
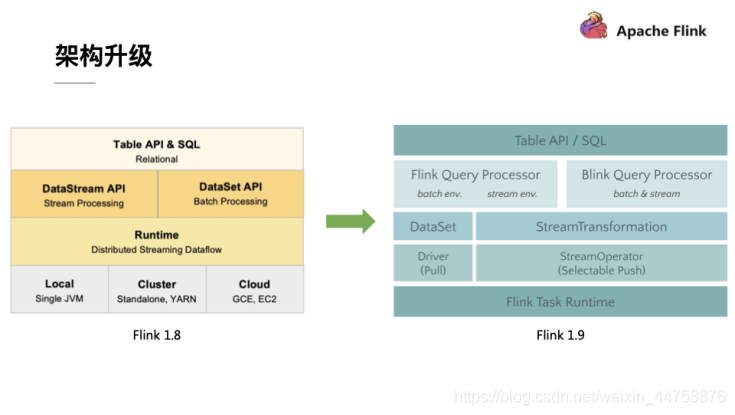
在Flink 1.9 之前,Flink API 层 一直分为DataStream API 和 DataSet API,Table API & SQL 位于 DataStream API 和 DataSet API 之上。可以看处流处理和批处理有各自独立的api (流处理DataStream,批处理DataSet)。而且有不同的执行计划解析过程,codegen过程也完全不一样,完全没有流批一体的概念,面向用户不太友好。
在Flink1.9之后新的架构中,有两个查询处理器:Flink Query Processor,也称作Old Planner和Blink Query Processor,也称作Blink Planner。为了兼容老版本Table及SQL模块,插件化实现了Planner,Flink原有的Flink Planner不变,后期版本会被移除。新增加了Blink Planner,新的代码及特性会在Blink planner模块上实现。批或者流都是通过解析为Stream Transformation来实现的,不像Flink Planner,批是基于Dataset,流是基于DataStream。
2.2 查询处理器的选择
查询处理器是 Planner 的具体实现,通过parser、optimizer、codegen(代码生成技术)等流程将 Table API & SQL作业转换成 Flink Runtime 可识别的 Transformation DAG,最终由 Flink Runtime 进行作业的调度和执行。
Flink Query Processor查询处理器针对流计算和批处理作业有不同的分支处理,流计算作业底层的 API 是 DataStream API, 批处理作业底层的 API 是 DataSet API
Blink Query Processor查询处理器则实现流批作业接口的统一,底层的 API 都是Transformation,这就意味着我们和Dataset完全没有关系了
Flink1.11之后Blink Query Processor查询处理器已经是默认的了
- 了解-Blink planner和Flink Planner具体区别如下:
- Blink将批处理作业视为流式处理的特殊情况。因此,表和数据集之间的转换也不受支持,批处理作业不会转换为数据集程序,而是转换为数据流程序,与流作业相同
- Blink planner不支持Batch TableSource
- old planner和Blink planner的FilterableSource实现不兼容
- 基于字符串的键值配置选项仅用于Blink planner
- PlannerConfig在两个planners中的实现(CalciteConfig)是不同的
- Blink planner将在TableEnvironment和StreamTableEnvironment上将多个汇优化为一个DAG。旧的计划者总是将每个水槽优化为一个新的DAG,其中所有DAG彼此独立
- 旧的计划期现在不支持目录统计,而Blink计划器支持
2.3 注意
- API 稳定性
- 性能对比
- 目前FlinkSQL性能不如SparkSQL,未来FlinkSQL可能会越来越好(下图是Hive、Spark、Flink的SQL执行速度对比)
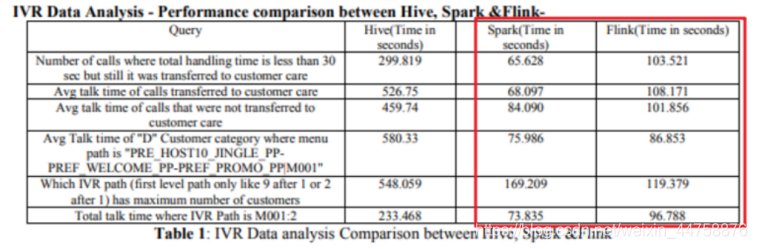
- 目前FlinkSQL性能不如SparkSQL,未来FlinkSQL可能会越来越好(下图是Hive、Spark、Flink的SQL执行速度对比)
3. 需要引入的pom依赖
1 | <dependency> |
4. 简单了解TableAPI
1 | def main(args: Array[String]): Unit = { |
4.1 动态表
如果流中的数据类型是 case class 可以直接根据 case class 的结构生成 table
1 | tableEnv.fromDataStream(dataStream) |
或者根据字段顺序单独命名
1 | tableEnv.fromDataStream(dataStream,’id,’timestamp........) |
最后的动态表可以转换为流进行输出
1 | table.toAppendStream[(String,String)] |
4.2 字段
用一个单引放到字段前面来标识字段名, 如 ‘name , ‘id ,’amount 等。
5. TableAPI 的窗口聚合操作
5.1 案例演示
- 统计每10 秒中每个传感器温度值的个数
1 | // 统计每10 秒中每个传感器温度值的个数 |
5.2 关于 group by
- 如果了使用 groupby, table 转换为流的时候只能用 toRetractDstream
1 | val dataStream: DataStream[(Boolean, (String, Long))] = table |
- toRetractDstream 得到的第一个 boolean 型字段标识 true 就是最新的数据(Insert), false 表示过期老数据(Delete)
1 | val dataStream: DataStream[(Boolean, (String, Long))] = table |
- 如果使用的 api 包括时间窗口, 那么窗口的字段必须出现在 groupBy 中
1 | val resultTable: Table = dataTable |
5.3 关于时间窗口
- 用到时间窗口, 必须提前声明时间字段, 如果是 processTime 直接在创建动态表时进行追加就可以
1 | val dataTable: Table = tableEnv.fromDataStream(dataStream, 'id, 'temperature, 'ps.proctime) |
- 如果是 EventTime 要在创建动态表时声明
1 | val dataTable: Table = tableEnv.fromDataStream(dataStream, 'id, 'temperature, 'ts.rowtime) |
- 滚动窗口可以使用 Tumble over 10000.millis on 来表示
1 | val resultTable: Table = dataTable |
6. SQL 如何编写
1 | // 统计每10 秒中每个传感器温度值的个数 |
7. 相关概念
7.1 Dynamic Tables & Continuous Queries
在Flink中,它把针对无界流的表称之为Dynamic Table(动态表),是Flink Table API和SQL的核心概念。顾名思义,它表示了Table是不断变化的。
我们可以这样来理解,当我们用Flink的API,建立一个表,其实把它理解为建立一个逻辑结构,这个逻辑结构需要映射到数据上去。Flink source源源不断的流入数据,就好比每次都往表上新增一条数据。表中有了数据,我们就可以使用SQL去查询了。要注意一下,流处理中的数据是只有新增的,所以看起来数据会源源不断地添加到表中。
动态表也是一种表,既然是表,就应该能够被查询。我们来回想一下原先我们查询表的场景:
- 将SQL语句放入到mysql的终端执行
- 查看结果
- 再编写一条SQL语句
- 再放入到终端执行
- 再查看结果
…如此反复
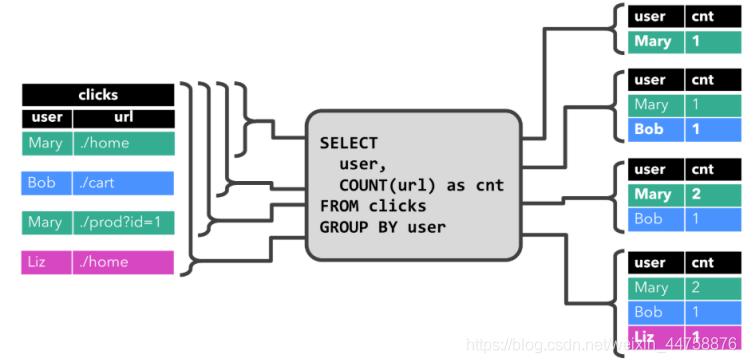
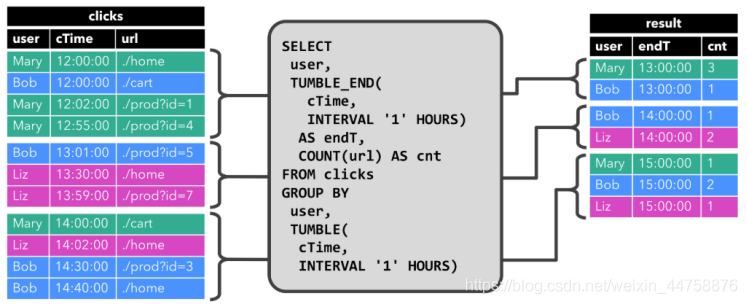
而针对动态表,Flink的source端肯定是源源不断地会有数据流入,然后我们基于这个数据流建立了一张表,再编写SQL语句查询数据,进行处理。这个SQL语句一定是不断地执行的。而不是只执行一次。注意:针对流处理的SQL绝对不会像批式处理一样,执行一次拿到结果就完了。而是会不停地执行,不断地查询获取结果处理。所以,官方给这种查询方式取了一个名字,叫Continuous Query,中文翻译过来叫连续查询。而且每一次查询出来的数据也是不断变化的。

这是一个非常简单的示意图。该示意图描述了:我们通过建立动态表和连续查询来实现在无界流中的SQL操作。大家也可以看到,在Continuous上面有一个State,表示查询出来的结果会存储在State中,再下来Flink最终还是使用流来进行处理。
所以,我们可以理解为Flink的Table API和SQL,是一个逻辑模型,通过该逻辑模型可以让我们的数据处理变得更加简单。
7.2 Table to Stream Conversion
7.2.1 表中的Update和Delete
我们前面提到的表示不断地Append,表的数据是一直累加的,因为表示对接Source的,Source是不会有update的。但如果我们编写了一个SQL。这个SQL看起来是这样的:
1 | SELECT user, sum(money) FROM order GROUP BY user; |
当执行一条SQL语句之后,这条语句的结果还是一个表,因为在Flink中执行的SQL是Continuous Query,这个表的数据是不断变化的。新创建的表存在Update的情况。仔细看下下面的示例,例如:
1 | 第一条数据,张三,2000,执行这条SQL语句的结果是,张三,2000 |
大家发现了吗,现在数据结果是有Update的。张三一开始是2000,但后面变成了2300。
那还有删除的情况吗?有的。看一下下面这条SQL语句:
1 | SELECT t1.`user`, SUM(t1.`money`) FROM t_order t1 |
1 | 第一条数据,张三,2000,执行这条SQL语句的结果是,张三,2000 |
因为张三的消费的金额已经超过了3000,所以SQL执行完后,张三是被处理掉了。从数据的角度来看,它不就是被删除了吗?
通过上面的两个示例,给大家演示了,在Flink SQL中,对接Source的表都是Append-only的,不断地增加。执行一些SQL生成的表,这个表可能是要UPDATE的、也可能是要INSERT的。
7.2.2 对表的编码操作
我们前面说到过,表是一种逻辑结构。而Flink中的核心还是Stream。所以,Table最终还是会以Stream方式来继续处理。如果是以Stream方式处理,最终Stream中的数据有可能会写入到其他的外部系统中,例如:将Stream中的数据写入到MySQL中。
我们前面也看到了,表是有可能会UPDATE和DELETE的。那么如果是输出到MySQL中,就要执行UPDATE和DELETE语句了。而DataStream我们在学习Flink的时候就学习过了,DataStream是不能更新、删除事件的。
如果对表的操作是INSERT,这很好办,直接转换输出就好,因为DataStream数据也是不断递增的。但如果一个TABLE中的数据被UPDATE了、或者被DELETE了,如果用流来表达呢?因为流不可变的特征,我们肯定要对这种能够进行UPDATE/DELETE的TABLE做特殊操作。
我们可以针对每一种操作,INSERT/UPDATE/DELETE都用一个或多个经过编码的事件来表示。
例如:针对UPDATE,我们用两个操作来表达,[DELETE] 数据+ [INSERT]数据。也就是先把之前的数据删除,然后再插入一条新的数据。针对DELETE,我们也可以对流中的数据进行编码,[DELETE]数据。
总体来说,我们通过对流数据进行编码,也可以告诉DataStream的下游,[DELETE]表示发出MySQL的DELETE操作,将数据删除。用 [INSERT]表示插入新的数据。
7.2.3 将表转换为三种不同编码方式的流
Flink中的Table API或者SQL支持三种不同的编码方式。分别是:
-
Append-only流
- 跟INSERT操作对应。这种编码类型的流针对的是只会不断新增的Dynamic Table。这种方式好处理,不需要进行特殊处理,源源不断地往流中发送事件即可
-
Retract流
- 这种流就和Append-only不太一样。上面的只能处理INSERT,如果表会发生DELETE或者UPDATE,Append-only编码方式的流就不合适了。Retract流有几种类型的事件类型:
- ADD MESSAGE:这种消息对应的就是INSERT操作
- RETRACT MESSAGE:直译过来叫取消消息。这种消息对应的就是DELETE操作
- 我们可以看到通过ADD MESSAGE和RETRACT MESSAGE可以很好的向外部系统表达删除和插入操作。那如何进行UPDATE呢?好办!RETRACT MESSAGE + ADD MESSAGE即可。先把之前的数据进行删除,然后插入一条新的。完美~
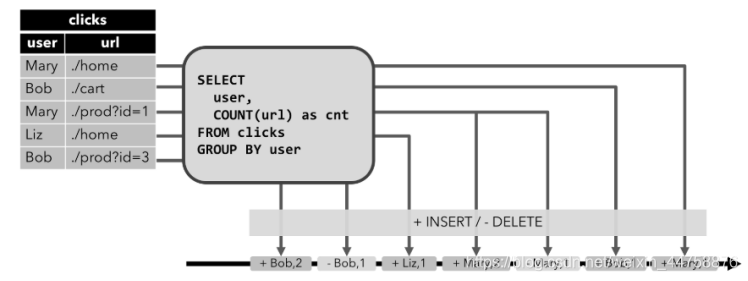
- 这种流就和Append-only不太一样。上面的只能处理INSERT,如果表会发生DELETE或者UPDATE,Append-only编码方式的流就不合适了。Retract流有几种类型的事件类型:
-
Upsert流
- 前面我们看到的RETRACT编码方式的流,实现UPDATE是使用DELETE + INSERT模式的。大家想一下:在MySQL中我们更新数据的时候,肯定不会先DELETE掉一条数据,然后再插入一条数据,肯定是直接发出UPDATE语句执行更新。而Upsert编码方式的流,是能够支持Update的,这种效率更高。它同样有两种类型的消息:
- UPSERT MESSAGE:这种消息可以表示要对外部系统进行Update或者INSERT操作
- DELETE MESSAGE:这种消息表示DELETE操作
- Upsert流是要求必须指定Primary Key的,因为Upsert操作是要有Key的。Upsert流针对UPDATE操作用一个UPSERT MESSAGE就可以描述,所以效率会更高
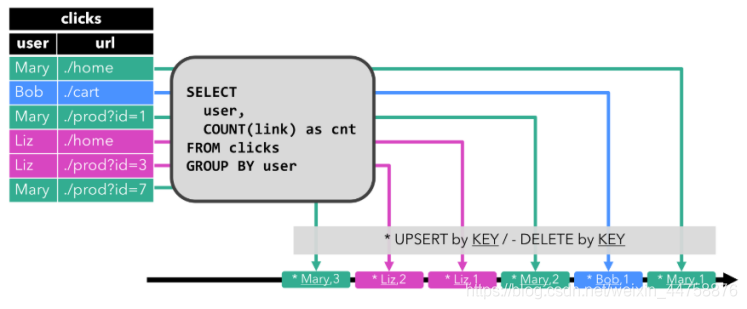
- 前面我们看到的RETRACT编码方式的流,实现UPDATE是使用DELETE + INSERT模式的。大家想一下:在MySQL中我们更新数据的时候,肯定不会先DELETE掉一条数据,然后再插入一条数据,肯定是直接发出UPDATE语句执行更新。而Upsert编码方式的流,是能够支持Update的,这种效率更高。它同样有两种类型的消息:
十一、Flink CEP 简介
1. 什么是复杂事件处理CEP
一个或多个由简单事件构成的事件流通过一定的规则匹配, 然后输出用户想得到的数据, 满足规则的复杂事件。
特征:
- 目标
- 从有序的简单事件流中发现一些高阶特征
- 输入
- 一个或多个由简单事件构成的事件流
- 处理
- 识别简单事件之间的内在联系, 多个符合一定规则的简单事件构成复杂事件
- 输出
- 满足规则的复杂事件
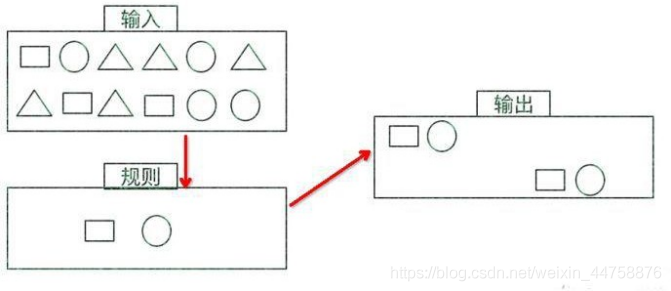
CEP 用于分析低延迟、频繁产生的不同来源的事件流。CEP 可以帮助在复杂的、不相关的事件流中找出有意义的模式和复杂的关系,以接近实时或准实时的获得通知并阻止一些行为。
CEP 支持在流上进行模式匹配, 根据模式的条件不同, 分为连续的条件或不连续的条件;模式的条件允许有时间的限制,当在条件范围内没有达到满足的条件时, 会导致模式匹配超时。
看起来很简单, 但是它有很多不同的功能:
- 输入的流数据, 尽快产生结果
- 在 2 个 event 流上, 基于时间进行聚合类的计算
- 提供实时/准实时的警告和通知
- 在多样的数据源中产生关联并分析模式
- 高吞吐、低延迟的处理
市场上有多种 CEP 的解决方案, 例如 Spark、Samza、Beam 等, 但他们都没有提供专门的 library 支持。但是 Flink 提供了专门的 CEP library。
2. Flink CEP
Flink 为 CEP 提供了专门的 Flink CEP library, 它包含如下组件:
- Event Stream
- pattern 定义
- pattern 检测
- 生成 Alert
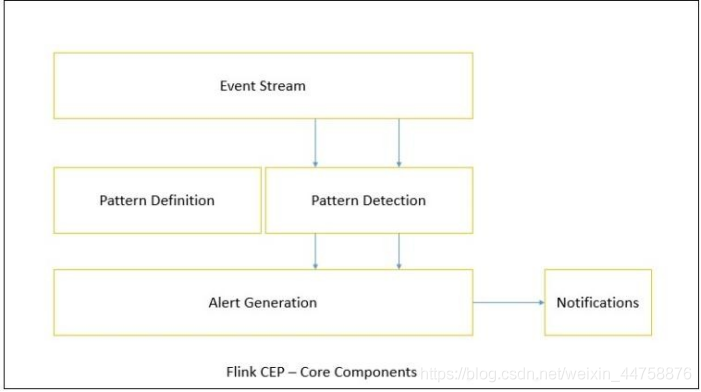
首先, 开发人员要在 DataStream 流上定义出模式条件, 之后 Flink CEP 引擎进行模式检测, 必要时生成告警。
为了使用 Flink CEP, 我们需要导入依赖:
1 | <dependency> |
2.1 Event Streams
以登陆事件流为例:
1 | case class LoginEvent(userId: String, ip: String, eventType: String, eventTi me: String) |
2.2 Pattern API
每个 Pattern 都应该包含几个步骤,或者叫做 state。从一个 state 到另一个 state, 通常我们需要定义一些条件, 例如下列的代码:
1 | val loginFailPattern = Pattern.begin[LoginEvent]("begin") |
每个 state 都应该有一个标示: 例如.beginLoginEvent中的"begin"
每个 state 都需要有一个唯一的名字, 而且需要一个 filter 来过滤条件, 这个过滤条件定义事件需要符合的条件, 例如:
1 | .where(_.eventType.equals("fail")) |
我们也可以通过 subtype 来限制 event 的子类型:
1 | start.subtype(SubEvent.class).where(...); |
事实上,你可以多次调用 subtype 和 where 方法;而且如果 where 条件是不相关 的,你可以通过 or 来指定一个单独的 filter 函数:
1 | pattern.where(...).or(...); |
之后,我们可以在此条件基础上,通过 next 或者 followedBy 方法切换到下一个 state,next 的意思是说上一步符合条件的元素之后紧挨着的元素;而 followedBy 并 不要求一定是挨着的元素。这两者分别称为严格近邻和非严格近邻。
1 | val strictNext = start.next("middle") |
最后,我们可以将所有的 Pattern 的条件限定在一定的时间范围内:
1 | next.within(Time.seconds(10)) |
这个时间可以是 Processing Time,也可以是 Event Time。
2.3 Pattern 检测
通过一个 input DataStream 以及刚刚我们定义的 Pattern, 我们可以创建一个PatternStream:
1 | val input = ... |
一旦获得 PatternStream,我们就可以通过 select 或 flatSelect,从一个 Map 序列 找到我们需要的警告信息。
2.4 select
select 方法需要实现一个 PatternSelectFunction, 通过 select 方法来输出需要的警告。它接受一个 Map 对,包含 string/event,其中 key 为 state 的名字, event 则为真实的 Event。
1 | val loginFailDataStream = patternStream |
其返回值仅为 1 条记录。
2.5 flatSelect
通过实现 PatternFlatSelectFunction,实现与 select 相似的功能。唯一的区别就 是 flatSelect 方法可以返回多条记录,它通过一个 Collector[OUT]类型的参数来将要 输出的数据传递到下游。
2.6 超时事件的处理
通过 within 方法,我们的 parttern 规则将匹配的事件限定在一定的窗口范围内。 当有超过窗口时间之后到达的 event,我们可以通过在 select 或 flatSelect 中,实现 PatternTimeoutFunction 和 PatternFlatTimeoutFunction 来处理这种情况。
1 | val patternStream: PatternStream[Event] = CEP.pattern(input, pattern) |




